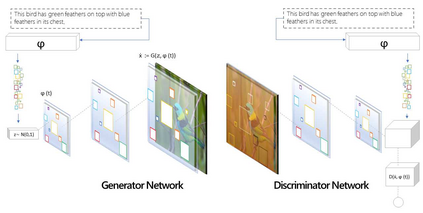
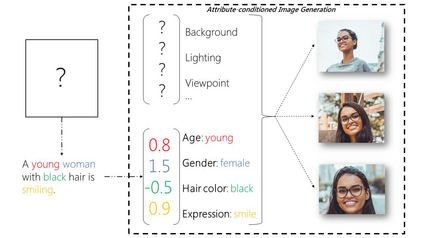
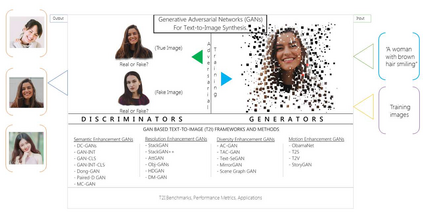
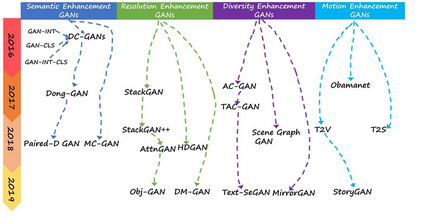
Text-to-image synthesis refers to computational methods which translate human written textual descriptions, in the form of keywords or sentences, into images with similar semantic meaning to the text. In earlier research, image synthesis relied mainly on word to image correlation analysis combined with supervised methods to find best alignment of the visual content matching to the text. Recent progress in deep learning (DL) has brought a new set of unsupervised deep learning methods, particularly deep generative models which are able to generate realistic visual images using suitably trained neural network models. In this paper, we review the most recent development in the text-to-image synthesis research domain. Our survey first introduces image synthesis and its challenges, and then reviews key concepts such as generative adversarial networks (GANs) and deep convolutional encoder-decoder neural networks (DCNN). After that, we propose a taxonomy to summarize GAN based text-to-image synthesis into four major categories: Semantic Enhancement GANs, Resolution Enhancement GANs, Diversity Enhancement GANS, and Motion Enhancement GANs. We elaborate the main objective of each group, and further review typical GAN architectures in each group. The taxonomy and the review outline the techniques and the evolution of different approaches, and eventually provide a clear roadmap to summarize the list of contemporaneous solutions that utilize GANs and DCNNs to generate enthralling results in categories such as human faces, birds, flowers, room interiors, object reconstruction from edge maps (games) etc. The survey will conclude with a comparison of the proposed solutions, challenges that remain unresolved, and future developments in the text-to-image synthesis domain.
翻译:文本到图像合成是指以关键词或句子的形式将人类书面文字描述转换成具有类似文字语义含义的图像的计算方法。在早期的研究中,图像合成主要依靠文字到图像的关联分析,同时依靠监督的方法找到与文本相匹配的视觉内容的最佳匹配。在深层次学习(DL)方面最近的进展带来了一套不受监督的深层次学习方法,特别是深层次的基因化模型,这些方法能够利用经过适当培训的神经网络模型生成现实的视觉图像。在本文中,我们审查了文本到模拟合成合成研究领域的最新发展情况。我们的调查首先介绍了图像合成及其挑战,然后审查了关键概念,如基因对抗网络(GANs)和深层次变异的视觉内容网络(DCNNN)等。 之后,我们提出一个分类,将基于GAN的文本到图像合成归纳归纳成四大类: 语义增强GANs, 增强GANs, 多样性增强GANSANs, 增强GANs 和 Motionalation GANs。我们详细解释了每个类的模型,最终都通过GANs 和GANs 的分类, 来得出了GNALs 和GNLs 。