学界 | NCSU&阿里巴巴论文:可解释的R-CNN
选自arXiv
机器之心编译
参与:Nurhachu Null、刘晓坤
由于深度学习已经在需要做出重大决策的领域如安防和自动驾驶中得到越来越广泛的应用,深度网络的可解释性称为愈加迫切的需要。北卡罗来纳州立大学与阿里巴巴 AI 实验室的研究人员近日提出了一种聚焦于目标检测的定性可解释的 R-CNN 网络,实现了未来人机对话的开端。
论文:Interpretable R-CNN

论文链接:https://arxiv.org/abs/1711.05226
这篇论文使用流行的两阶段基于区域的卷积神经网络的目标检测系统(即 R-CNN)展示了一种学习定性可解释模型的方法。R-CNN 由一个区域建议网络和一个感兴趣区域预测网络(RoI,Region of interest)组成。通过使用可解释的模型,我们可以聚焦于弱监督的提取基本原理生成(extractive rationale generation),即在检测中(对任何部分都不使用监督的情况下)自动地、同步地学习展开目标实例的隐藏部分结构。我们在使用了自顶向下的分层综合语法模型(嵌入于有向无环的与或图,AOG),以探索并展开 RoI 中的隐藏部分结构。我们提出了一种 AOG 解析算子(AOG parsing operator)来取代 R-CNN 中常用的 RoI 池化算子(RoI Pooling Operator),因此我们提出的方法可以适用于很多基于卷积神经网络的顶尖目标检测系统。AOG 解析算子的目标是同时利用自顶向下的分层综合语法模型的严密可解释性,以及以自底向上的端到端形式训练得到的深度神经网络的判别能力。在检测中,将使用从 AOG 中实时得到的最佳解析树(parse tree)来解释边界盒(bounding box),这个边界盒可以看做为解释检测而生成的提取基本原理。在学习过程中,我们提出了一种折叠-展开(fold-unfolding)的方法来端到端地训练 AOG 和卷积网络。在实验中,我们在 R-FCN 之上创建模型并测试了我们提出的方法,测试是在 PASCAL VOC 2007、 PASCAL VOC 2012 数据集上进行的,最终的性能与目前最先进的方法有可比性。
1.1. 动机和目标
近年来,由大数据驱动的深度神经网络取得了惊人的成功 [45, 40],深度神经网络能够显著地提升预测准确率,甚至在图像分类任务 [27,69] 中超越了人类的表现 [27, 69]。在目标检测的相关文献中,有一个很关键的方法转变:从更明确的表征和模型,例如可变形的组件模型 DPM[18] 的集合体、它的众多变体以及分层综合与或图(AOG)模型 [66, 82, 73, 74],向不够透明但是更加准确的基于卷积神经网络(ConvNet)方法的转变 [61, 9, 60, 50, 26, 10]。同时,已经证明,深度神经网络可以很轻易地遭到所谓的对抗攻击(adversarial attacks)的欺骗,这些攻击利用人类视觉无法察觉的、精心设计的微扰动(甚至是单像素攻击 [67])使网络对输入以无法预料的方式进行误分类 [57, 2]。此外,还证明深度学习能够轻易地拟合随机标签。由于目前缺乏理论基础 [1],很难分析目前最先进的深度神经网络起作用或失败的原因。从认知科学的角度来看,目前最先进的神经网络或许不是以人类的思维方式来工作,人类知道「为什么」并且知道如何解释 [43]。然而,在越来越多的应用中,基于深度神经网络的计算机视觉和机器学习模型需要对有潜在严重后果的场景做出决策,例如,安防视频监控和自动驾驶。
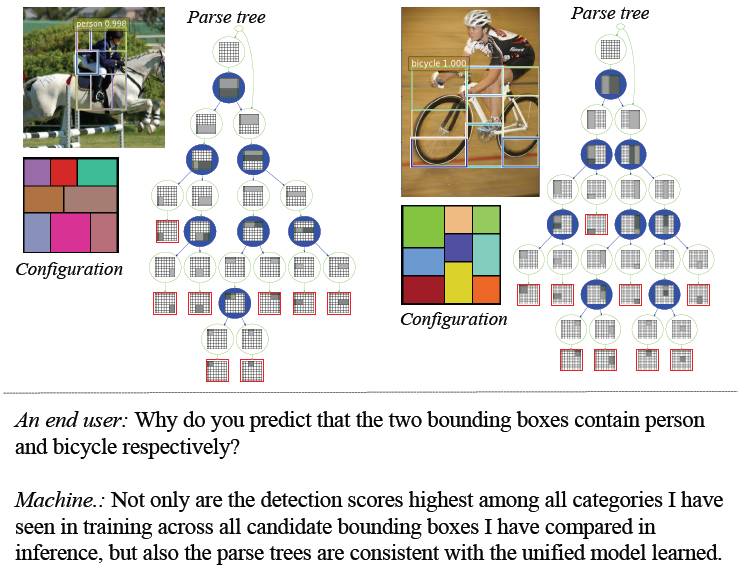
图 1:上方:通过论文提出的方法在 PASCAL VOC 2007 测试集上的检测例子。除了预测边界盒和检测得分之外,我们的方法还输出了隐藏判别解析树和部分结构,后者作为检测中的定性提取基本原理,是通过弱监督的方式计算得到的,就是说训练中只能得到边界盒。解析树从隐藏完全结构的空间中实时推理得到,隐藏完全结构是由自顶向下的分层综合语法模型来表征的。下方:是一个想象的存在于算法和终端用户之间的对话,终端用户正在尝试着理解预测结果。你可以阅读文本内容了解更多细节。
没有可解释的正当理由的预测最终的可应用性都是受限的。因为一个基本的直觉就是,如果我们身边的人做了一些事但是不能给出令人信服的解释,是很令人沮丧的。人犹如此,更不用说机器了。所以,解决机器无法解释其预测和行为的问题是非常关键的(例如 DARPA 提出的可解释 AI[12]),解决这个问题是为了提升准确率和透明度:不仅仅是一个能对随机样本计算得到高概率预测结果的可解释模型,还能够完美地以一种可解释形式向终端用户推理它的预测。通常而言,学习可解释的模型就是让机器去理解人类,这通常包含很多方面。所以,对模型的可解释性一直都没有一个被广泛接受的定义。尤其是,长期以来,以量化的形式去衡量可解释性一直是一个开放性问题。这篇文章聚焦于在目标检测问题中学习定性可解释的模型。我们的目标是,在不损失检测性能的前提下,用简单的扩展方法定性地解释常用的两阶段基于区域的卷积检测系统(即 R-CNN[22,61,9])。图 1 展示了通过我们提出的弱监督训练来计算解释性的一些例子。
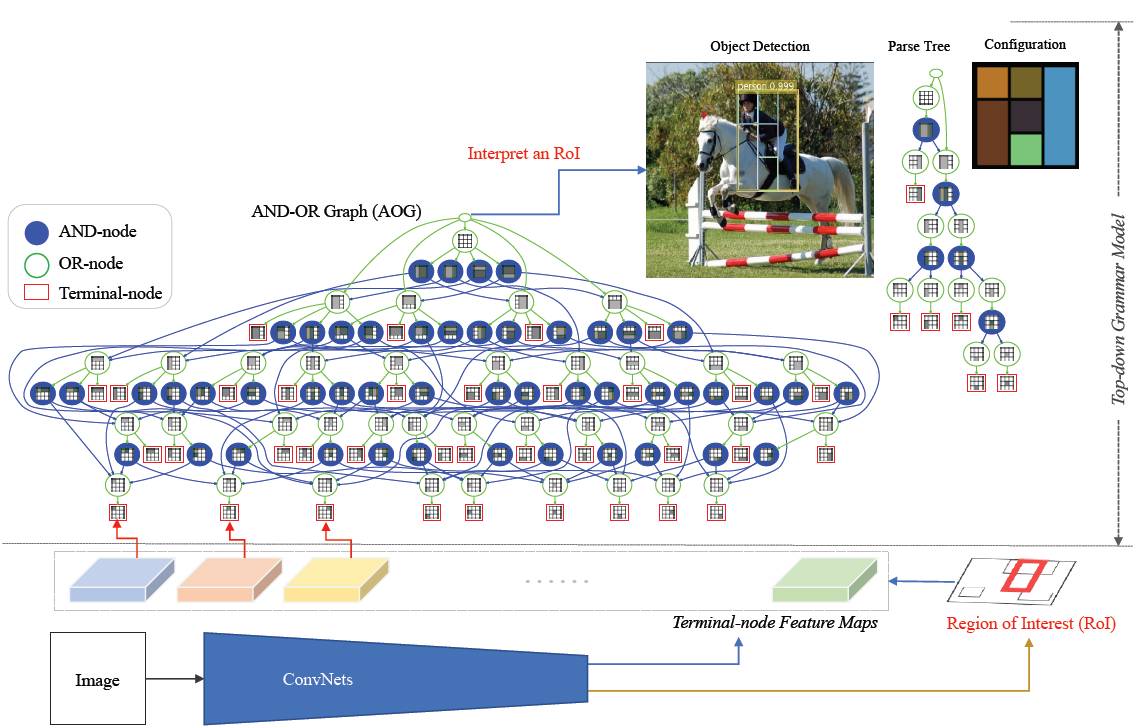
图 2:将通用的由有向五环 AOG 表示的自顶向下的语法模型,和自底向上的卷积神经网络端到端地集成到一起。为简单起见,我们展示了使用文献 [66] 中提出的方法(利用 3x3 网格)构造的 AOG。上图中的 AOG 展开了所有可能存在的隐藏部分结构(使用矩形组件和二分规则)。我们在 R-FCN 方法 [9] 的基础上创建模型。基于 AOG,我们使用终端节点感知地图(Terminal-node sensitive maps),并提出了一个 AOG 解析算子去替代 R-FCN 中的对位置敏感的 RoI 池化算子,它能够为 RoI 实时推理出最佳解析树,以及最佳的部分结构。我们将边界盒的回归分支保持不变,这一点在图中没有展示出来。
1.2. 方法概览
如图 2 所示,这篇论文提出了一种能够在目标检测中定性学习可解释模型的方法,这个方法以端到端的形式集成了通用的自顶向下的分层综合语法模型以及自底向上的卷积神经网络。我们在检测中采用了 R-CNN[22,61,9],它由两部分组成:(i)一个用于目标检测的区域建议组件。像 RoI 一样的类未知目标边界盒建议通常由两种方式生成:要么是利用现成的目标检测器(如选择性搜索 [70]),要么是以端到端的形式学习一个集成的区域建议网络 (RPN)[61]。(ii)RoI 预测组件。它基于 RoI 池化算子来分类或者回归边界盒的建议。RoI 池化算子计算等尺寸的特征地图,以适应不同类型的建议。通过可解释的模型,我们聚焦于在 RoI 预测组件中的弱监督提取基本原理生成,也就是不为部分结构使用任何的监督,在检测的过程中实时地、自动地学习展开 RoI 中的隐藏判别部分结构。最后,我们利用嵌在一个有向五环 AOG[66,74] 中的通用的自顶向下的综合语法模型来探索并揭示 RoI 中的隐藏部分结构中的空间(图 2 的上半部分是一个相关的例子)。一个 AOG 中有三种不同的节点:「与」节点代表从大部分到两个小部分的二元分解;「或」节点代表分解的不同方式;终端节点代表的是部分实例。AOG 与通用图像语法框架是一致的 [21, 83, 17, 82]。在基于 R-CNN 的检测系统中,我们提出了用 AOG 解析算子代替 RoI 池化算子。在检测中,每一个边界盒都由一个最佳解析树来解释,这个解析树是从 AOG 中实时得到的,它是为检测生成的提取基本原理(如图 1 所示)。
在学习过程中,我们提出了一种折叠-展开(folding-unfolding)方法,用端到端的方式训练 AOG 和卷积神经网络。在折叠步骤中,AOG 中的或节点是通过 MEAN 算子实现的(也就是说,或节点计算了子节点的平均值)。在展开步骤中,它们是通过 MAX 算子实现的(也就是说,每一个与节点选择了最好的子节点)。折叠步骤就是要集成所有的隐藏部分结构。展开步骤就是要将隐藏部分结构最大化,为每一类的每一个 RoI 明确地推断出最佳解析树,然后基于推断得到的解析树的分数类为 RoI 分类。折叠步骤确保展开步骤中一个或节点的子节点之间的公平比较,因为用 AOG 中未充分训练的参数来决定最佳子节点的选择是不合理的,尤其是在随机初始化参数的开始阶段。最后的解析树被用作为检测到的目标提取的基本原理,它是对比性的(与 AOG 中所有可能的部分结构竞争),也是选择性的(仅仅使用从 AOG 中得到的所有部分结构)。
在实验中,我们在 R-FCN[9] 之上构建模型,并以在 ImageNet[63] 上预训练的残差网络 [27] 作为主干网络(backbone)。我们在 PASCAL VOC 2007 和 2012 数据集上测试了我们的方法,结果证明我们的性能能够和目前最先进的方法相媲美。我们还使用控制变量法从不同角度来研究了这个方法。
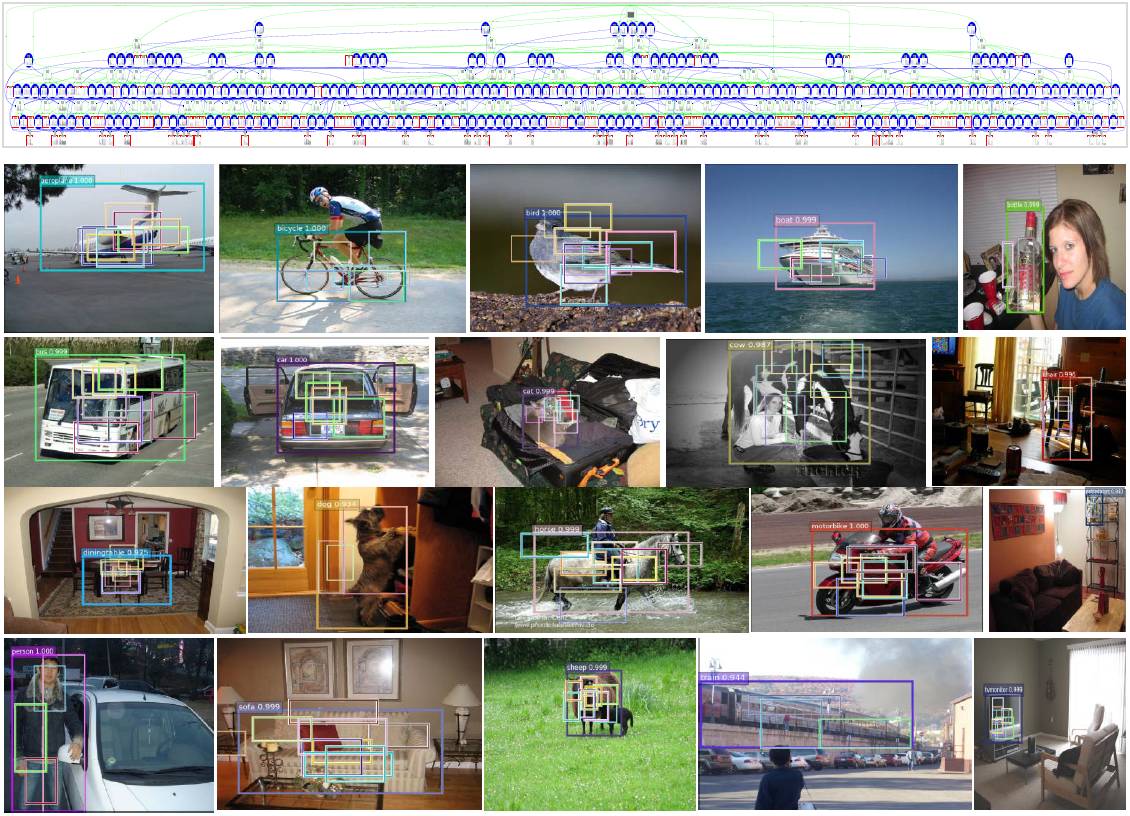
图 4:上方:PASCAL VOC 数据集(2007,2012)中学习到的 AOG,每一个节点的类分布都被画了出来。下方:使用学习到的模型 AOG「AOG772-d-1」来展开隐藏部分结构的例子。我们展示了 VOC 2007 数据集中每一类的一个随机例子。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com
点击「阅读原文」,在 PaperWeekly 参与对此论文的讨论。




