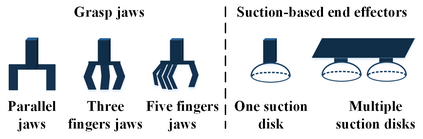
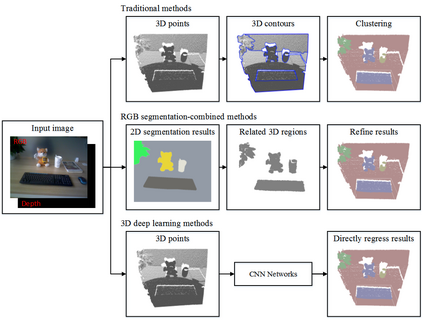
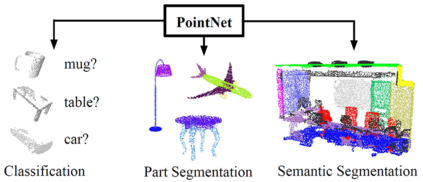
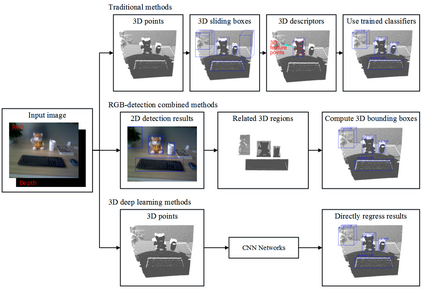
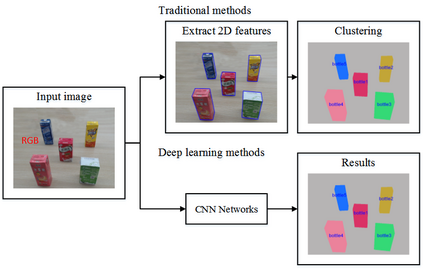
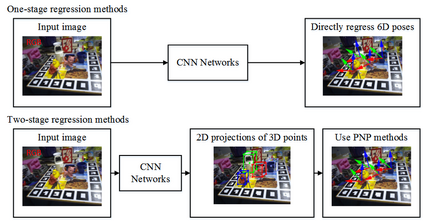
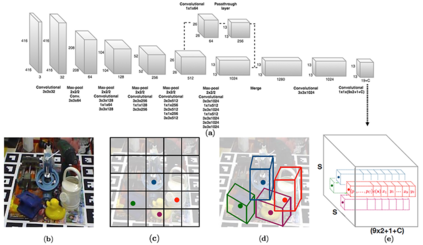
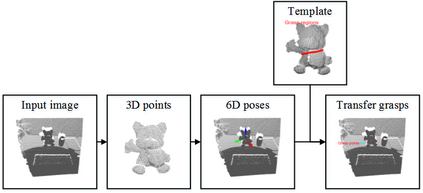
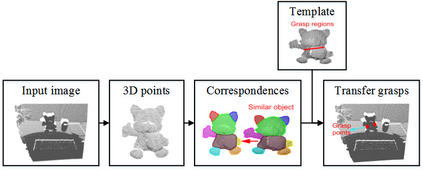
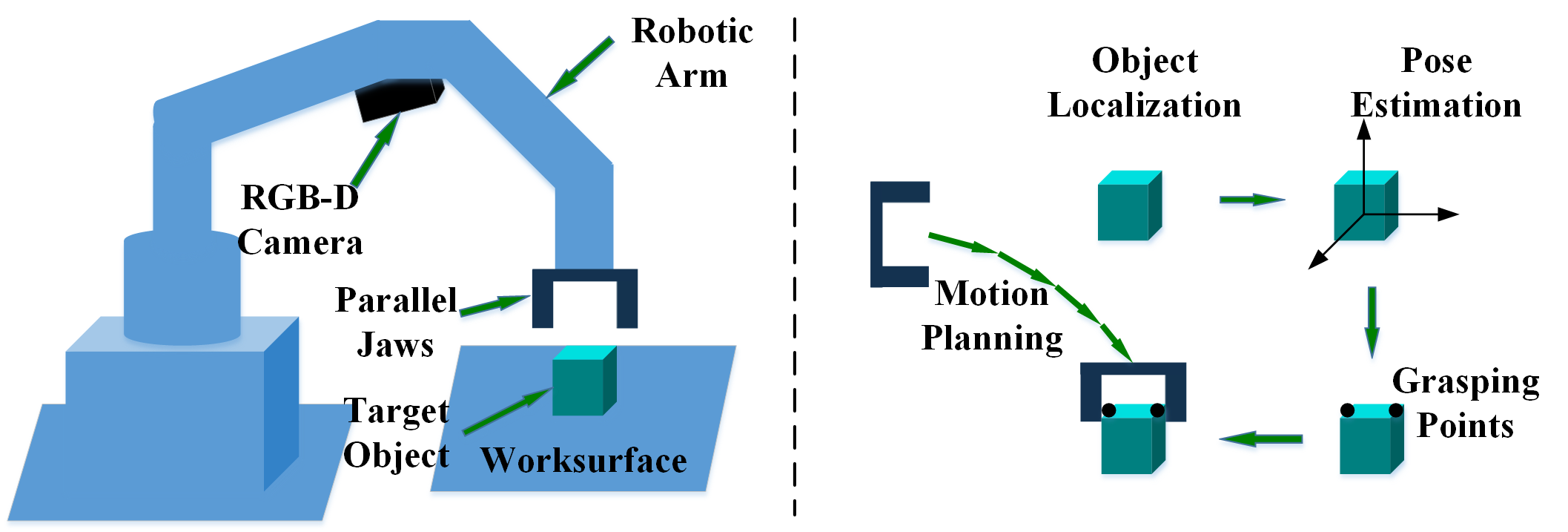
This paper presents a comprehensive survey on vision-based robotic grasping. We concluded four key tasks during robotic grasping, which are object localization, pose estimation, grasp detection and motion planning. In detail, object localization includes object detection and segmentation methods, pose estimation includes RGB-based and RGB-D-based methods, grasp detection includes traditional methods and deep learning-based methods, motion planning includes analytical methods, imitating learning methods, and reinforcement learning methods. Besides, lots of methods accomplish some of the tasks jointly, such as object-detection-combined 6D pose estimation, grasp detection without pose estimation, end-to-end grasp detection, and end-to-end motion planning. These methods are reviewed elaborately in this survey. What's more, related datasets are summarized and comparisons between state-of-the-art methods are given for each task. Challenges about robotic grasping are presented, and future directions in addressing these challenges are also pointed out.
翻译:本文介绍了关于基于愿景的机器人掌握的全面调查。我们在机器人掌握期间完成了四项关键任务,即物体定位、显示估计、掌握探测和运动规划。详细来说,物体定位包括物体探测和分离方法,包括基于RGB和RGB-D的方法,掌握探测包括传统方法和深层次学习方法,运动规划包括分析方法、模仿学习方法以及强化学习方法。此外,许多方法联合完成一些任务,例如物体探测-结合6D构成估计、在不构成估计的情况下掌握探测、端到端发现探测和端到端运动规划。在本调查中对这些方法进行了详细审查。更多的是,对相关数据集进行了总结,对每一项任务都进行了最新方法的比较。提出了机器人掌握方面的挑战,并提出了应对这些挑战的未来方向。