Spark精华问答 | 为什么要学Spark?

Hadoop再火,火得过Spark吗?今天我们继续关于Spark的精华问答吧。

Q:什么是Spark?
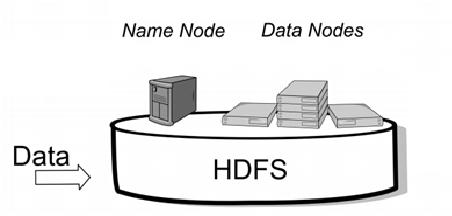
A:简单理解,Spark是在Hadoop基础上的改进,是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于map reduce算法实现的分布式计算,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出和结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的map reduce的算法。
Q:为什么要学Spark?
A:基于MapReduce的计算引擎通常会将中间结果输出到磁盘上,进行存储和容错。出于任务管道承接的,考虑,当一些查询翻译到MapReduce任务时,往往会产生多个Stage,而这些串联的Stage又依赖于底层文件系统(如HDFS)来存储每一个Stage的输出结果。
Spark是MapReduce的替代方案,而且兼容HDFS、Hive,可融入Hadoop的生态系统,以弥补MapReduce的不足。
Q:Spark有什么特性?
A:1、高效性
运行速度提高100倍。Apache Spark使用最先进的DAG调度程序,查询优化程序和物理执行引擎,实现批量和流式数据的高性能。
2、易用性
Spark支持Java、Python和Scala的API,还支持超过80种高级算法,使用户可以快速构建不同的应用。而且Spark支持交互式的Python和Scala的shell,可以非常方便地在这些shell中使用Spark集群来验证解决问题的方法。
3、通用性
Spark提供了统一的解决方案。Spark可以用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLlib)和图计算(GraphX)。这些不同类型的处理都可以在同一个应用中无缝使用。Spark统一的解决方案非常具有吸引力,毕竟任何公司都想用统一的平台去处理遇到的问题,减少开发和维护的人力成本和部署平台的物力成本。
4、兼容性
Spark可以非常方便地与其他的开源产品进行融合。比如,Spark可以使用Hadoop的YARN和Apache Mesos作为它的资源管理和调度器,器,并且可以处理所有Hadoop支持的数据,包括HDFS、HBase和Cassandra等。这对于已经部署Hadoop集群的用户特别重要,因为不需要做任何数据迁移就可以使用Spark的强大处理能力。Spark也可以不依赖于第三方的资源管理和调度器,它实现了Standalone作为其内置的资源管理和调度框架,这样进一步降低了Spark的使用门槛,使得所有人都可以非常容易地部署和使用Spark。此外,Spark还提供了在EC2上部署Standalone的Spark集群的工具。
Q:Spark生态圈介绍
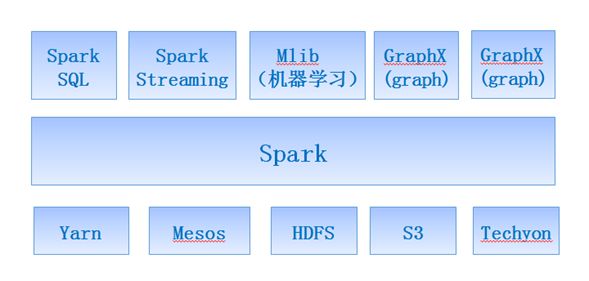
A:Spark力图整合机器学习(MLib)、图算法(GraphX)、流式计算(Spark Streaming)和数据仓库(Spark SQL)等领域,通过计算引擎Spark,弹性分布式数据集(RDD),架构出一个新的大数据应用平台。
Spark生态圈以HDFS、S3、Techyon为底层存储引擎,以Yarn、Mesos和Standlone作为资源调度引擎;使用Spark,可以实现MapReduce应用;基于Spark,Spark SQL可以实现即席查询,Spark Streaming可以处理实时应用,MLib可以实现机器学习算法,GraphX可以实现图计算,SparkR可以实现复杂数学计算。
Q:Spark与Hadoop的对比
A:Spark的中间数据放到内存中,对于迭代运算效率更高。Spark更适合于迭代运算比较多的ML和DM运算。因为在Spark里面,有RDD的抽象概念。所以,Spark比Hadoop更通用。

小伙伴们冲鸭,后台留言区等着你!
关于Spark,今天你学到了什么?还有哪些不懂的?除此还对哪些话题感兴趣?快来留言区打卡啦!留言方式:打开第XX天,答:……
同时欢迎大家搜集更多问题,投稿给我们!风里雨里留言区里等你~
福利
1、扫描添加小编微信,备注“姓名+公司职位”,加入【云计算学习交流群】,和志同道合的朋友们共同打卡学习!

2、公众号后台回复:白皮书,获取IDC最新数据白皮书整理资料!
推荐阅读:
微服务进阶避坑指南 | 技术头条
2019年技术盘点微服务篇(二):青云直上云霄 | 程序员硬核评测
“入职 6 年,新人工资高我 2 千”:老板不加钱,不是嫌你老
从沉迷游戏到沉迷编程,16 岁赚 20 万美元!
南大和中大“合体”拯救手残党:基于GAN的PI-REC重构网络,“老婆”画作有救了 | 技术头条
救救中国 996 程序员!GitHub 近 230,000 Star、Python 之父伸张正义!
一个月修复20个漏洞获23675美元赏金, 原来是黑客队伍里出了无间道