优化哈希策略
(点击上方公众号,可快速关注)
来源:ImportNew - fzr
概述
散列策略会对HashMap或HashSet之类的散列集合的性能产生直接的影响。
内置的散列(又称哈希)函数都是通用的,在大多数使用情况下都能表现很好。但是我们能不能做的更好呢,特别是当你对某个用例产生了很好的想法时?
测试一个散列策略
在先前的一篇文章中,我研究了一些测试散列策略的方法,其中特别注意了一种“正交位”优化的散列策略,它仅仅只是改变一个位就能确保每个散列结果尽可能的不同。
http://vanillajava.blogspot.co.uk/2015/08/comparing-hashing-strategies.html?view=magazine
然而,如果要对一个已知的元素或关键字集合进行散列,你就可以针对具体案例进行优化,而不是寻求一个通用方案。
减少冲突
一个散列集合中最主要的事情就是避免冲突了。所谓冲突,就是两个以上关键字映射到同一个散列槽中。这些冲突意味着当有多个关键字映射到同一个散列槽中时你必须要付出更多的努力来检查那些关键字是否是你想要的那个。理想状态下一个散列槽中最多有一个关键字。
我只需要唯一的散列码,是吗?
通常的误解是只要散列码唯一就可以避免冲突。虽然都希望散列码是唯一的,但它还不够。
假设现在有一些关键字,每一个都有唯一的32位散列码。如果你有40亿散列槽,每个关键字都有自己的槽,那就没有冲突了。对于所有的散列集合,这样大的数组一般是不太现实的。事实上,HashMap和HashSet的大小都收到机器内存的限制,一般为2^30,大概刚刚超过10亿。
当你只能有一个规模上比较实际的哈希集合时又该如何呢?散列槽的数目需要更小一些,而散列码需对散列槽数目取模。如果散列槽数是2的幂值,你可以用最低位当掩码。
来看个例子,ftse350.csv。如果把第一列作为关键字或是元素,就有352个字符串。这些字符串有唯一的String().hashCode()码,但是假设我们只取这些散列码的低位。会不会有冲突呢?
https://github.com/OpenHFT/Chronicle-Algorithms/blob/master/src/test/resources/ftse350.csv

一个装载因子是0.7(默认)的HashMap的大小是512,使用哈希码的低九位作为掩码。可以看到,尽管原始的哈希码是唯一的,仍然有大约30%的关键字会冲突。
HashTesterMain的代码在这里。
https://github.com/OpenHFT/Chronicle-Algorithms/blob/master/src/test/java/net/openhft/chronicle/algo/hashing/HashTesterMain.java
为了减少糟糕的散列策略造成的影响,HashMap使用了扰动函数。Java 8里的实现相当简单。
下面是来自HashMap.hash的源码。想了解更多细节,可以阅读Javadoc文档。
http://grepcode.com/file/repository.grepcode.com/java/root/jdk/openjdk/8-b132/java/util/HashMap.java#318
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
这个方法混合了原始哈希码的高位和低位,以此来提高低位的随机性。对于像上面的那样有相当高的冲突率的情况,这就是一个改善方法。请参看第三列。
初探 String类的散列函数
下面是String.hashCode()的代码:
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
String的哈希实现已经在Javadoc中规定好了,所以我们基本没有机会改动,但我们可以定义一个新的哈希策略。
散列策略的组成部分
我会留意散列策略中的两个部分。
魔法数字。你可以尝试不同的数字以取得最佳效果。
代码结构。你需要一个无论选取什么样的魔法数字都能提供一个好的结果的代码结构。
魔法数字固然很重要,但是你并不想让它过于重要;因为总是有些时候你选的数字并不适合你的使用场景。这就是为什么你同时还需要一个即使在魔法数字选取很糟糕的情况下其最坏情况依然不是特别差的代码结构。
用别的乘数代替31
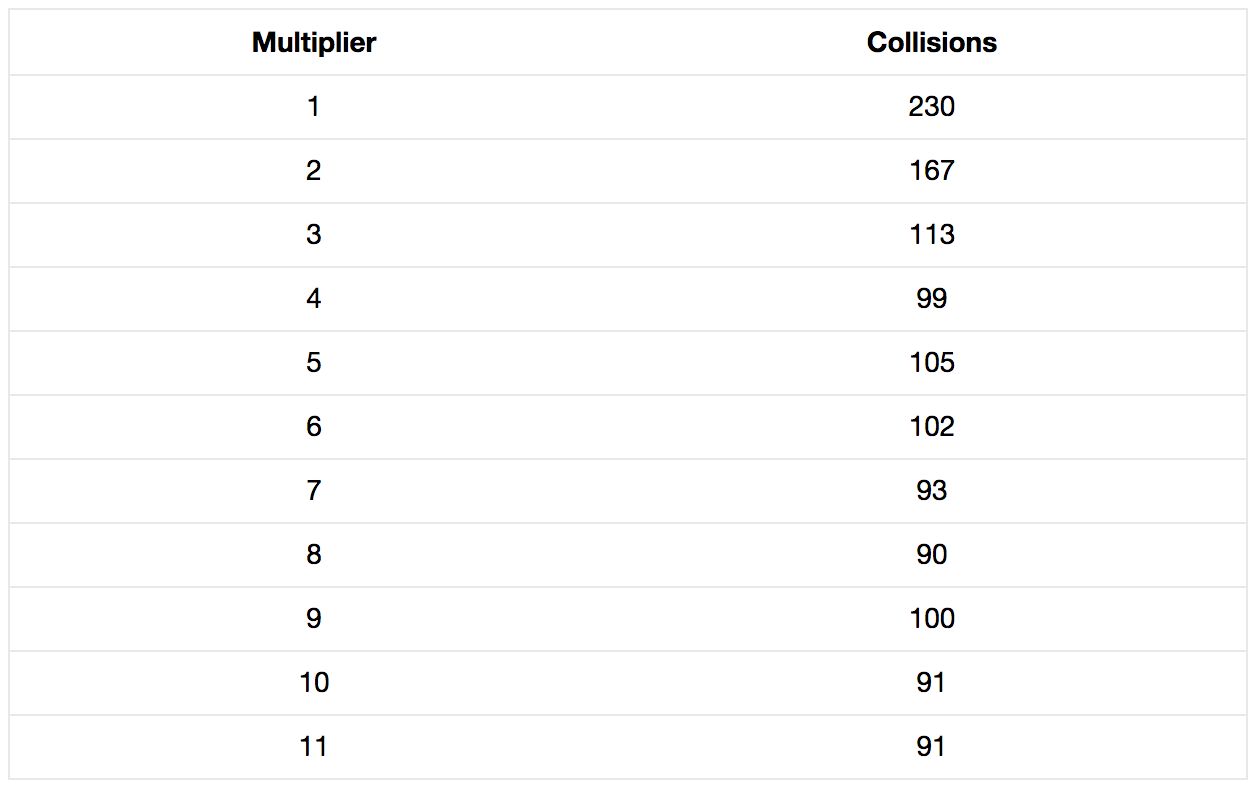
可以看到,魔法数的选取的确很重要,但需要尝试的数字太多了。我们需要写一个测试程序,测试出一个不错的随机选择。HashSearchMain的源码。
https://github.com/OpenHFT/Chronicle-Algorithms/blob/master/src/test/java/net/openhft/chronicle/algo/hashing/HashSearcherMain.java
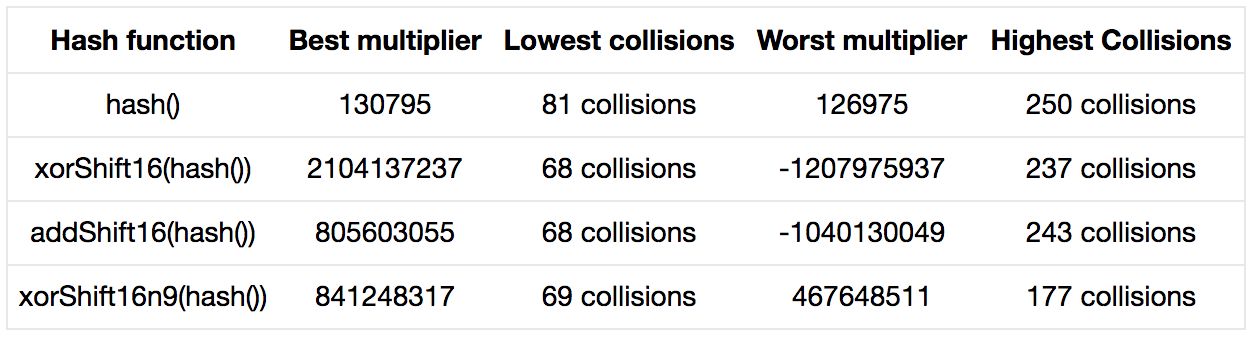
代码的关键部分:
public static int hash(String s, int multiplier) {
int h = 0;
for (int i = 0; i < s.length(); i++) {
h = multiplier * h + s.charAt(i);
}
return h;
}
private static int xorShift16(int hash) {
return hash ^ (hash >> 16);
}
private static int addShift16(int hash) {
return hash + (hash >> 16);
}
private static int xorShift16n9(int hash) {
hash ^= (hash >>> 16);
hash ^= (hash >>> 9);
return hash;
}
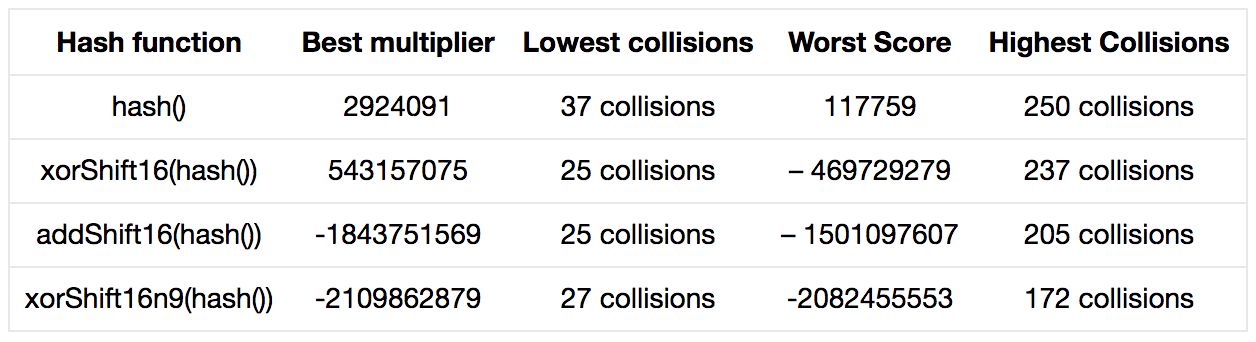
可以发现,如果提供了好的乘数,或是适合于你的关键字集合的乘数,那么重复乘上每个哈希值再加上下一个字符就很合理。对比分别以130795和31作乘数,对于测试的关键字集合,前者只有81次碰撞而后者有103次。
如果你再加上扰动函数,碰撞会减少到大约68次。这已经很接近加倍数组规模时的冲突率了:不占用更多内存,却可以降低冲突率。
但是当我们向散列集合中添加新的关键字时会发生什么呢?魔法数字还能表现良好吗?这使我不得不研究最坏冲突率,以决定在面对更大范围的输入时,哪种代码结构可能会表现得更好。hash()的最坏表现是250次碰撞,即70%的关键字发生冲突,确实很糟糕。扰动函数能稍稍提高性能,但作用也不大。注意:如果我们选择与偏移值相加而不是异或会得到更糟糕的结果。
然而,如果选择位移两次——不仅仅是混合高低位,还有从产生的哈希值的四个部分选择的位,结果发现,最坏情况的冲突率大大下降。这使我想到,在选择的关键字改变的情况下,如果结构足够好,魔法数的影响足够低,我们得到糟糕结果的可能性就会降低。
如果在哈希函数中选择了相加而非异或,会发生什么呢?
在扰动函数中采用异或而不是相加可能会得到更好的结果。如果我们将
h = multiplier * h + s.charAt(i);
变为
h = multiplier * h ^ s.charAt(i);
会发生什么呢?
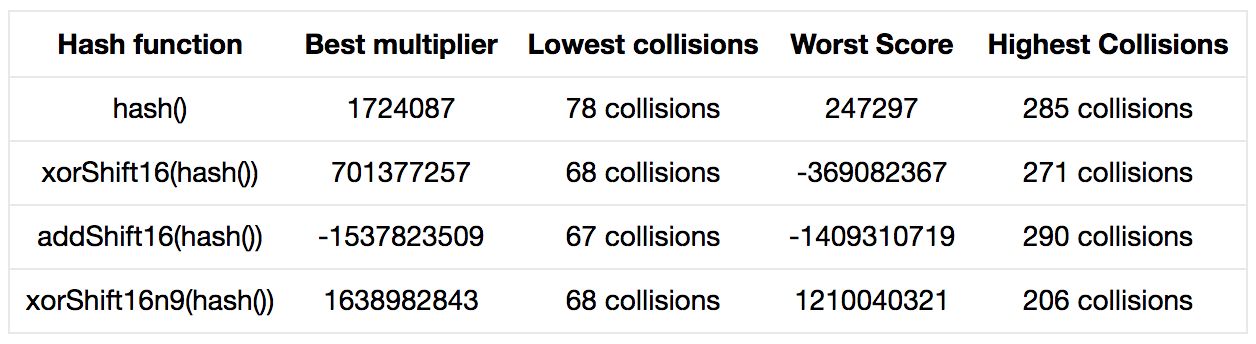
最佳情况下的表现变好了一些,然而最坏情况下的冲突率明显更高了。由此我看出,魔法数选取的重要性提高了,也意味着,关键字的影响更大了。考虑到关键字可能会随着时间改变,这种选择好像有些冒险。
为何选择奇数作为乘数
当与一个奇数相乘时,结果的低位是0或1的概率相等;因为0*1=0,1*1=1.然而,如果与偶数相乘,最低位一定是0.也就是说,这一位不再是随机变化的了。假设我们重复先前的测试,但是只采用偶数,结果会怎样?
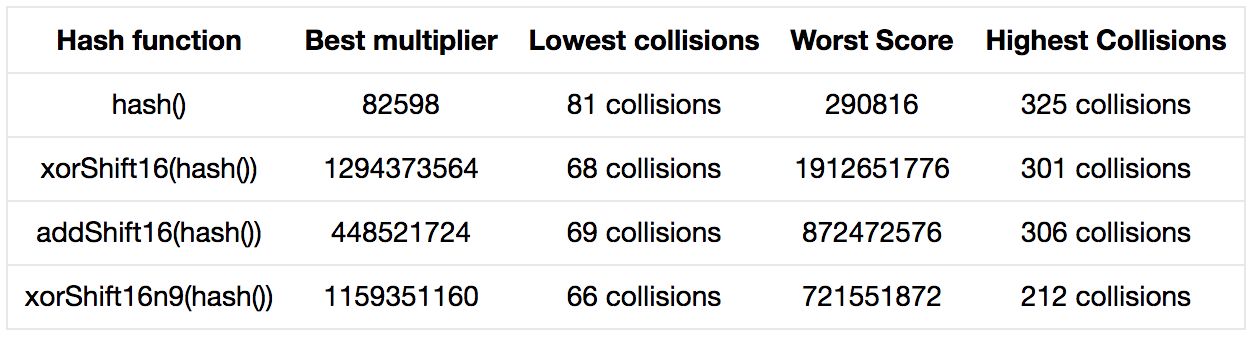
如果你很幸运,魔法数选对了,那么结果将会和奇数情况下一样好。然而如果不太幸运,结果可能会很糟糕。325次碰撞意味着,512个哈希槽中只有27个被使用了。
更高级的散列策略有何不同?
对于我们使用的基于City,Murmur,XXHash,以及Vanilla Hash(我们自己的)的哈希策略:
该策略一次读取64位数据,比一字节一字节地读快很多;
所得有效值是两个64位长的值;
有效值被缩短至64位;
结果使用了更多的常量乘数;
扰动函数更为复杂;
我们在实现中使用长哈希值是因为:
我们为64位处理器做了优化;
Java中最长的基本数据类型是64位的;
如果你的散列集合太大(比如百万以上),32位的散列值很难保证唯一性。
总结
通过探索哈希值的产生过程,我们找到了将352个关键字的冲突次数从103次降到68次的方法。同时,我们也相信,如果关键字集合发生变化,我们也能降低变化可能造成的影响。
这是在不占用更多内存,或更多处理器资源的情况下完成的。
我们也可以选择使用更多内存。
作为对比,可以看到,加倍数组规模可以提高最佳情况下的表现。但我们仍然要面对的问题是:当关键字集合和魔法数匹配的不好时,哈希冲突率依然很高。
结论
在你的关键字集合比较稳定的情况下,你可以通过调整哈希策略来明显改善冲突率。当关键字集合改变时,你还需要测试不优化的情况下结果会糟糕到什么程度。将这两种策略结合起来,你可以不占用更多内存和CPU就能得到提高性能的新哈希策略。
看完本文有收获?请转发分享给更多人
关注「ImportNew」,提升Java技能



