据说以后在探头下面用帽子挡脸没用了:SymmNet遮挡物检测的对称卷积神经网络

摘要
从立体图像或视频帧中进行遮挡物的检测,对许多计算机视觉应用而言都是非常重要的。先前的研究重点主要是将其与视差或光流的计算捆绑在一起,这导致了严重的 chicken-and-egg 问题。在本文中,我们利用卷积神经网络来解决传统交错的计算框架中遮挡物检测问题。
我们提出一个对称的卷积神经网络结构 (SymmNet),它能够直接利用图像对的信息,而无需提前估计视觉差异或动作的影响。我们所提出的网络是一种左右的对称结构,在学习双目下的遮挡问题的同时,旨在共同改善检测结果。
我们通过综合的实验分析来验证我们模型的有效性:实验结果表明,在立体图像和运动遮挡问题中,我们的模型能够取得当前最先进的检测表现。
简介
对多视角图像或视频序列数据的遮挡或无遮挡区域的定位问题,一直以来是许多计算机视觉任务中非常感兴趣的研究方向。解决这个问题我们需要考虑与其最相关的两个任务:立体图像计算和视频光流估计。
图像中被遮挡的像素是违反了图像内部的对应约束,从而导致像素匹配的模糊性。当前最先进的处理立体图像和光流方法都是基于对遮挡物的检测:通过在视差和运动计算过程中排除遮挡物的像素,或通过修复这些被遮挡的区域。
因此,遮挡物检测也被应用于帮助改善诸如动作识别、目标追踪和 3D 重建等任务的表现。 现有的大多数方法都是视差或光流估计来解决遮挡物的检测问题。最简单也是最广泛使用的方法是左右交叉检查 (left-right-cross-checking,LRC),这种方法直接通过预先计算的视差结果来推断遮挡的位置。然而,LRC 方法中未引入遮挡物的先验知识,这将无法精确地计算出视差结果,影响后续的检测结果。
其他一些研究提出通过交替改进视差和运动准确性,来迭代地改善遮挡物的映射图。总的说来,先前研究中对遮挡物的检测依赖于预先计算的视差或光流估计,这种方法容易受到噪声、低或重复的纹理特征的理影响,具有很大局限性。
这促使我们探索一种检测立体图像或视频连续帧中遮挡物的解决方案。在本文中,我们主要关注的是立体图像的遮挡物检测问题。随着卷积神经网络 (CNN) 在单目深度和相机定位方面的成功应用,我们利用 CNN 结构来解决遮挡物检测中的视差估计问题。
我们将遮挡检测视为二元分类问题,并提出一种对称卷积网络 (SymmNet) 作为分类器。SymmNet是一种利用双目图像信息的沙漏架构 (hourglass architecture)。利用左右对称的网络结构,我们能够推断出双眼条件下遮挡物的情况,从而同时同步改善左右的检测结构。
本文的贡献主要包含以下三个方面:
这项工作是第一个无需利用视差和运动估计的先验知识,而直接对遮挡物进行检测的研究
提出了一个对称卷积神经网络结构 SymmNet,它能直接以图像对作为输入并进行协同工作
进行综合的实验以验证模型设计,实验结果表明该方法在立体图像和运动遮挡的检测方面有着非常有前景的表现
模型结构
我们提出了一种对称结构的卷积神经网络 (SymmNet),通过左右对称结构来预测堆叠双目图像流的遮挡问题。
下图说明我们所提出的网络的简要架构,我们遵循 FlowNet 的结构来构建一个完整的卷积网络,其中包含一个收缩部分 (contractive) 和扩展部分 (expanding),以跳跃连接的方式连接这两部分。
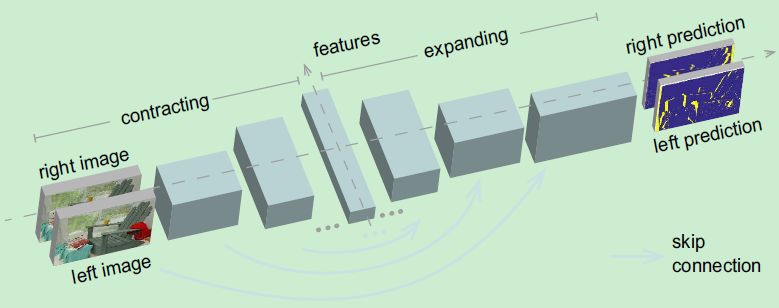
图1 SymmNet 网络结构
中间层和残差连接在图中省略。网络以双目图像对作为输入,输出的是双目图像中的遮挡物。沿着特征通道,网络整体呈一种左右对称的结构。
下表1中列出了详细的逐层定义。由于遮挡物检测可能依赖于来自广阔视野的信息,因此网络的收缩模块通过特征子采样来编码大型结构。它包含6个步长为2下采样层来逐步增加接收域,并且将特征映射图的空间大小缩小64倍。
为了在扩展模块中获得原始输入分辨率的逐像素预测,我们使用6个反卷积层进行上采样特征。
在每个下采样或上采样层后都连接一个卷积层来平滑结果输出。为了保留更多的局部细粒度信息,低层次的特征通过跳跃连接进行解码。每层后采用 ReLU 作为层激活函数,以更好应对梯度消失问题。
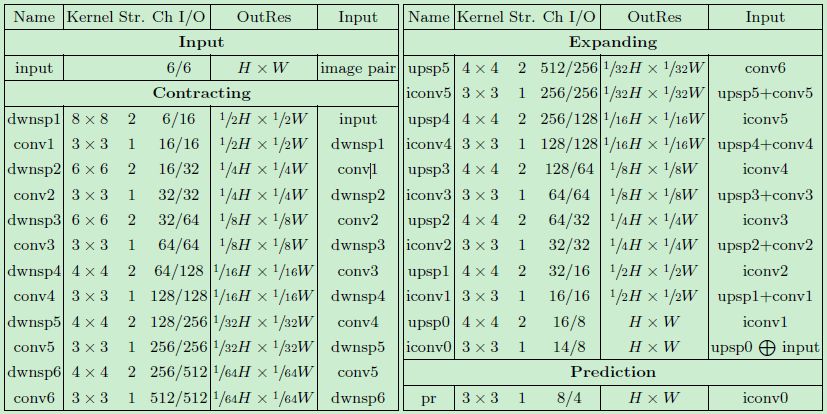
表1 SymmNet 结构参数
除预测层 pr,其余每一层后都接上一个ReLU 函数,而 pr 层后激活函数采用的是 softmax 函数以输出检测概率。表格的排列方式是从上到下,从左到右的,其中 + 代表加法运算,⊕ 代表的是跳跃连接中的串联操作。
与 FlowNet 结构不同,我们的 SymmNet 模型采取了几种网络修剪策略以提高网络的计算效率。首先,我们对特征通道的数量进行压缩。第一层有16个过滤器。每次对特征映射图的空间大小进行下采样时,网络的特征长度都将翻倍,并在收缩模块的最后一层达到最大值,该层包含512个过滤器。
然后,我们更换了跳跃连接中的连接方式,并相应地减小扩展模块的特征长度以匹配收缩模块。另一个修改是我们的网络在扩展模块后又包含一个额外上采样模块,以获得全分辨率的输出。由上采样到全分辨率,原始图像的特征将与最后一层的卷积层特征相连接。这是出于图像低层次特征可以帮助定位遮挡物的考虑而做的处理。
实验
我们在 SceneFlow 数据集上训练我们的模型,该数据集由合成序列渲染后的立体图像构成。该数据集的规模足够大,共包含35454对训练数据和和4370 对测试数据,以此训练的模型不会产生过拟合现象。此外,该数据集还提供了密集而完美的地面实况差异的两种视图,可用于生成双目图像中真实的遮挡物。我们首先进行对比实验以验证我们模型的有效性,接着在 SceneFlow 和 Middleburry 数据集上对比其他方法。然后,我们在 MPI Sintel 数据集上测试模型学习运动遮挡物的容量。最终,我们还测试了我们结构的效率,包括运行的时间和内存使用。
值得注意的是,我们采用三个在遮挡物检测任务中广泛使用的评估指标,包括精度值 P,回召值 R 以及 F 分数。在预测遮挡物时,我们将阈值设置为0.5。
结构分析
为了验证模型设计的有效性,我们在 SceneFlow 数据集上测试了SymmNet 及其一些变体。在图2我们提供了示例结果,并在图4中可视化 PR 曲线结果。

图2 不同结构变体的示例结果
MonoNet (L/R) 的第一排是MonoNetL 的结果,而第二行是 MonoNetR 的结果。MonoNetL中的粉色箭头指向图像边缘发生的假遮挡现象,而 MonoNetR中的箭头指向错误的遮挡物形状。
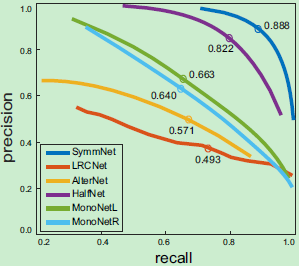
图3 PR曲线
在 PR 曲线上标注了最大 Fscore。曲线越靠近右上角代表该模型的表现更好。因此我们可以看到 SymmNet 的表现由于其他两种变体结构。
我们提出的 SymmNet 模型能够直接对输入图像的遮挡进行建模,无需基于视差计算的先验知识。从结果上看,我们的模型明显优于其他变体结构,验证了 SymmNet 模型结构的有效性。
整体性能
我们在 SceneFlow 和 Middlebury 数据集上验证 SymmNet 模型的整体性能,并其他两种检测器进行比较。定性结果及定量结果分别如下图4,图5及表2所示。

图4 SceneFlow 数据集的定性结果
真正的正样本 (true positive) 估计用青色标记,假阴性 (false negative) 用洋红色标记,假阳性 (false positive) 用黄色标记。绿色框标记错误发生在第一行中倾斜平面上以及第二行中无纹理区域。

图5. Middlebury 数据集的定性结果
真正的正样本 (true positive) 估计用青色标记,假阴性 (false negative) 用洋红色标记,假阳性 (false positive) 用黄色标记。
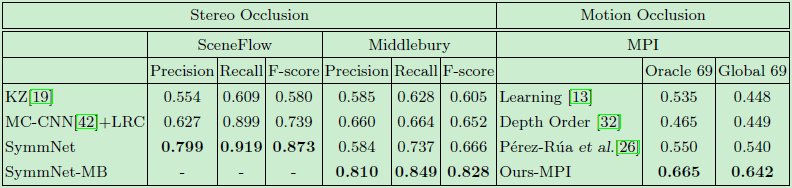
表2 定量估计结果
所有的评估结果中,值越高表示模型性能越好,在这里我们用粗体来突出显示最佳的表现。
运动遮挡检测
尽管 SymmNet 模型的设计是用于立体图像中遮挡物的检测,但它也可以应用于以两个连续帧作为输入的运动遮挡检测任务。我们在 MPI Sintel 数据集上验证并展示模型的表现。实验结果如下图6所示:在运动遮挡检测任务中,即使真实的遮挡区域比立体图像中的区域小得多,我们的模型仍然可以做得很好的预测。

图6 模型在 MPI 数据集上的定性结果
从左到右依次是:两个输入帧的平均图像;真实的遮挡物图像;我们模型预测的遮挡物图像。
运行时间和内存需求
我们在单个 NVIDIA Tesla M40 GPU 上,测试以 PyTorch 框架实现的运行时间。结果表明,我们的模型能够在 SceneFlow 数据集的训练时间只需两天。在预测一张 540×960 的图像对时,模型需要 0.07s 的运行时间和 651M 的显卡内存。总的说来,对时间和内存的低要求使我们的模型有很强的可用性,并能应用于其他任务的预处理模块,如目标追踪,人体姿势估计和行为识别等。
总结
我们提出了一种名为 SymmNet 的 CNN 模型来检测立体图像或视频序列中的遮挡。与传统方法通过预先计算的视差或光流估计结果来推断被遮挡的像素不同,我们的模型能够直接从原始图像中进行学习。SymmNet 模型是一种左右对称的结构,以协作的方式提取双目图像信息并学习图像中的遮挡。实验结果验证了我们模型具有良好的立体和运动遮挡检测的能力。



