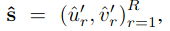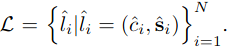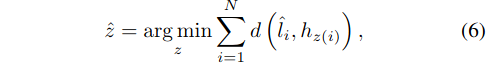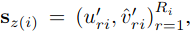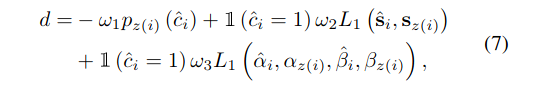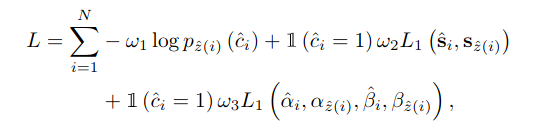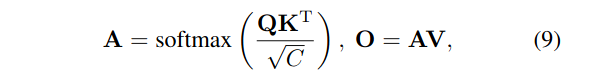西安交通大学等发布最新论文End-to-end Lane Shape Prediction with Transformers。使用Transformer捕获道路中细长车道线特征和全局特征,性能优于PolyLaneNet等网络,速度可高达420 FPS!>>加入极市CV技术交流群,走在计算机视觉的最前沿
1 摘要
车道线检测是将车道识别为近似曲线的过程,被广泛用于自动驾驶汽车的车道线偏离警告和自适应巡航控制。流行的分两步解决问题的pipeline:特征提取和后处理。虽然有用,但效率低下,在学习全局上下文和通道的长而细的结构方面存在缺陷。
本文提出了一种端到端方法,
该方法可以直接输出车道形状模型的参数
,使用通过transformer构建的网络来学习更丰富的结构和上下文。车道形状模型是基于道路结构和摄像头姿势制定的,可为网络输出的参数提供物理解释。
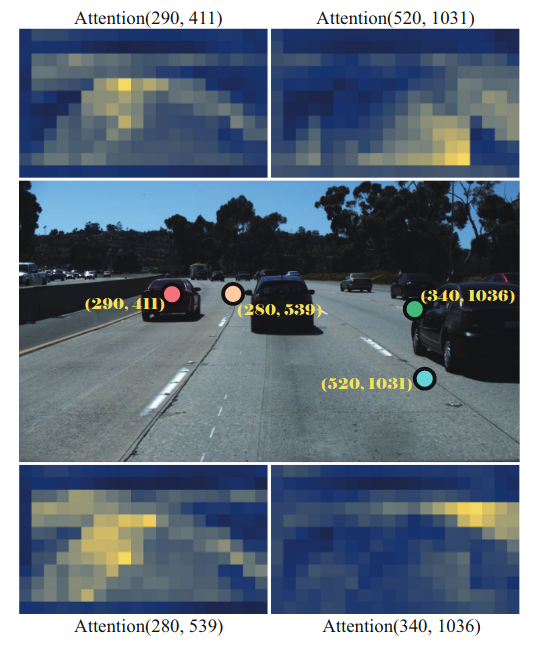
transformer使用自我注意机制对非局部交互进行建模,以捕获细长的结构和全局上下文
。
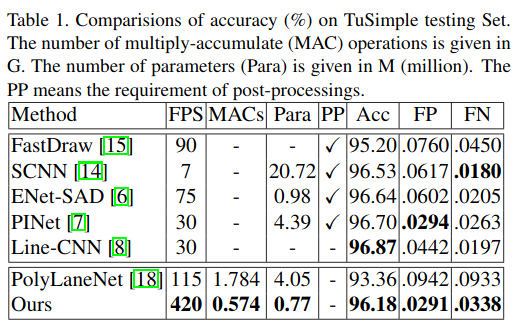
该方法已在TuSimple基准测试中得到验证,并以最轻巧的模型尺寸和最快的速度显示了最新的准确性。
此外,我们的方法对具有挑战性的自收集车道线检测数据集显示出出色的适应性,显示了其在实际应用中的强大部署潜力。
论文地址:
https://arxiv.org/pdf/2011.04233.pdf
代码地址(即将开源):
https://github.com/liuruijin17/LSTR
2 本文思路
为了解决效率和车道线结构的问题,
建议将车道检测输出重构为车道形状模型的参数,并开发一个由非局部构件构建的网络,以加强对全局背景和车道细长结构的学习。
每个车道的输出是一组参数,这些参数通过从道路结构和摄像机姿态推导出的显式数学公式近似于车道标记。在给定摄像机固有参数等特定先验条件下,无需任何3D传感器,这些参数就可以用于计算道路曲率和摄像机俯仰角。
其次,受广泛使用transformer块来显式建模语言序列中的长期依赖关系的自然语言处理模型的启发,我们开发了一个基于transformer的网络,
该网络从任何成对的视觉特征中总结信息,使其能够捕获通道的狭长结构和全局隐含文本
。整个体系结构立即预测输出,并采用匈牙利损失进行端到端训练。损失模型采用预测与真值之间的二部匹配,保证一对一的无序分配,使模型消除了显性的非极大抑制过程。
在常规的多车道检测基准上验证了该方法的有效性。此外,
为了评估对新场景的适应性,我们在多个城市收集了大量具有挑战性的数据集,称为前视车道(FVL),跨越各种场景(城市和高速公路、白天和夜晚、各种交通和天气条件)。
该方法在复杂数据集不包含夜景等场景的情况下,对新场景具有较强的适应性。
•提出了一种车道形状模型,其参数作为直接回归输出,反映道路结构和摄像机姿态。
•开发了一个基于transformer的网络,该网络考虑了非局部的相互作用,以捕获车道和全球背景下的细长结构。
•本文方法以最少的资源消耗达到了最先进的精度,并对具有挑战性的自采集车道检测数据集显示了良好的适应性。
3 具体实现
本文端到端方法将输出重构为车道形状模型的参数。通过基于transformer的网络和匈牙利拟合损失对参数进行预测。
车道形状的先验模型被定义为多项式。通常,三次曲线用来近似平地上的单车道线:
(X,Z)表示地平面上的点。当光轴平行于地平面时,从道路投影到像平面上的曲线为:
对于一个光轴与地平面成φ角的倾斜相机,从untilted像面到tilted像面转换的曲线为:
-
Curve re-parameterization
此外,还引入了垂直起止偏移量α、β来参数化各车道线。这两个参数提供了基本的定位信息来描述车道线的上下边界。
在真实的道路条件下,车道通常具有全局一致的形状。因此,近似圆弧从左到右车道的曲率相等,因此k′′,f′′,m′′,n′将被所有车道共享。因此,t-th车道的输出被重新参数化为gt:
3.2 Hungarian Fitting Loss
匈牙利拟合损失在预测参数和车道真值之间进行匹配,
采用匈牙利算法有效地解决了匹配问题,然后利用匹配结果优化路径相关回归损失。
我们的方法预测了一个固定的N条曲线,其中N被设置为大于典型数据集图像中的最大车道数。让我们来表示预测曲线
![]() (0: non-lane, 1: lane)。
由于预测曲线的数目N大于ground truth lane的数目,我们也把ground truth lane看作是一组大小为N的非lane填充集
通过搜索最优单射函数z:L→H,我们将曲线集与地面真道标记集之间的二部匹配作为一个成本最小化问题,即z(i)是分配给拟合车道真值i的曲线的指标:
我们使用概率而不是[3]之后的对数概率,因为这使得分类项与曲线拟合项可通约掉。
ω1,ω2,ω3也调整损失项的影响,并设置为与Eq. 7相同的系数。
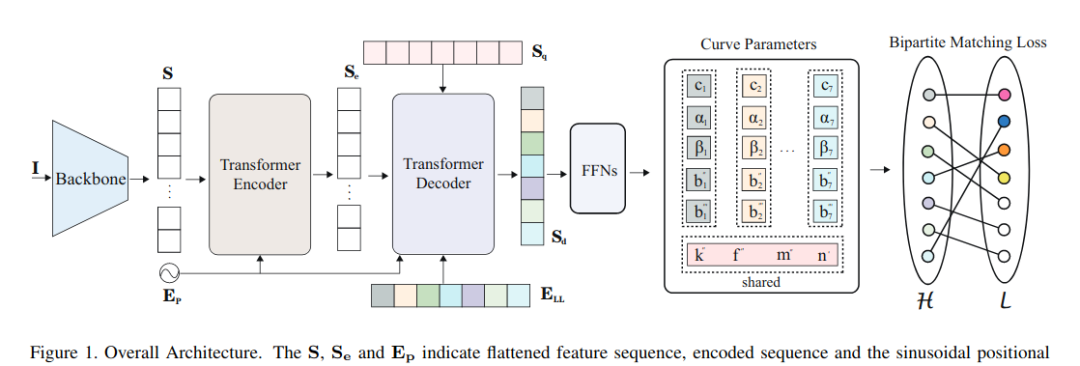
图1所示的体系结构包括一个主干、一个简化transformer网络、几个用于参数预测的前馈网络(FFNs)和匈牙利损失。
(0: non-lane, 1: lane)。
由于预测曲线的数目N大于ground truth lane的数目,我们也把ground truth lane看作是一组大小为N的非lane填充集
通过搜索最优单射函数z:L→H,我们将曲线集与地面真道标记集之间的二部匹配作为一个成本最小化问题,即z(i)是分配给拟合车道真值i的曲线的指标:
我们使用概率而不是[3]之后的对数概率,因为这使得分类项与曲线拟合项可通约掉。
ω1,ω2,ω3也调整损失项的影响,并设置为与Eq. 7相同的系数。
图1所示的体系结构包括一个主干、一个简化transformer网络、几个用于参数预测的前馈网络(FFNs)和匈牙利损失。
-
给定输入图像I,主干提取低分辨率特征,然后通过压缩空间维度将其压缩成一个序列S。S和位置嵌入Ep馈入transformer Encoder以输出表示序列Se。
-
然后,Decoder首先处理一个初始查询序列Sq和一个隐式学习位置差异的学习位置嵌入ELL生成输出序列Sd,计算与Se和Ep的交互以处理相关特征。
-
最后,有几种FFNs直接对所提出的输出参数进行预测。
主干是建立在reduced ResNet18的基础上。原ResNet18有4个block和16倍下采样功能。每个块的输出通道为“64、128、256、512”。这里,
我们简化 ResNet18将输出通道削减为“16、32、64、128”以避免过拟合,并将降采样因子设置为8以减少车道结构细节的损失。
主干网利用输入图像作为输入,提取低分辨率特征,对高分辨率车道空间表示进行编码。接下来,为了构造一个作为编码器输入的序列,将该特征在空间维度上进行平铺,得到一个长度为HW×C的序列S,其中HW表示序列的长度,C为信道数。
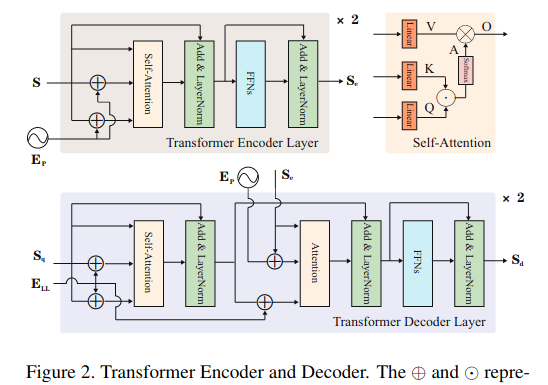
编码器有两个按顺序链接的标准层。它们分别由一个自注意模块和一个前馈层组成,如图2所示。
在抽象空间表示序列S的基础上,利用基于绝对位置的正体嵌入Ep对位置信息进行编码,以避免排列变化。
该Ep具有与s相同的尺寸。编码器通过下式执行缩放点积注意.
其中Q,K,V表示对每个输入行进行线性变换的查询、键和值序列,a表示度量非局部交互以捕获纤细结构和全局上下文的注意力映射,O表示自注意的输出。HW×C形状的编码器Se的输出序列是通过FNNs、层归一化的residual连接和另一个相同的编码器层得到的。
解码器也有两个标准层。
与编码器不同的是,每一层都插入另一个注意模块,该模块期望编码器的输出,使编码器能够对包含空间信息的特征执行注意机制,从而与最相关的特征元素相关联。
面对翻译任务,原转换器将地真序列移位一个位置,作为译码器的输入,使其每次并行输出序列中的每个元素
。在车道检测任务中,我们将输入的Sq设置为一个空的N×C矩阵,并直接一次解码所有的曲线参数。
此外,我们引入了一种N×C的学习车道嵌入算法,作为隐式学习全局车道信息的位置嵌入。注意机制与公式9相同,解码后的N×C形状的序列Sd与编码方法相似。训练时,在每一解码层之后进行中间监督。
预测模块通过三部分生成预测曲线H集合。单个线性操作直接将Sd投射为N×2,然后softmax层对其进行最后维运算,得到预测标签(background或lane)ci,i∈{1,…,N}。
同时,一个具有ReLU激活和隐C维的3层感知器将Sd投射为N×4,其中维4表示四组特定路径参数。另一个3层感知器首先将一个特征投影到N×4,然后在第一维取平均值,得到4个共享参数。
4 实验结果
4.1 Comparisions with State-of-the-Art Methods
-
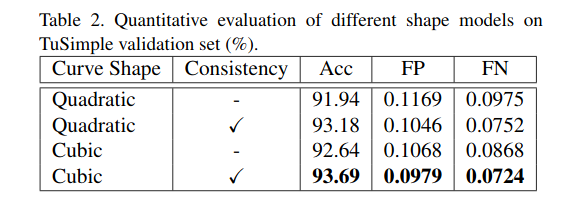
Investigation of Shape Model
-
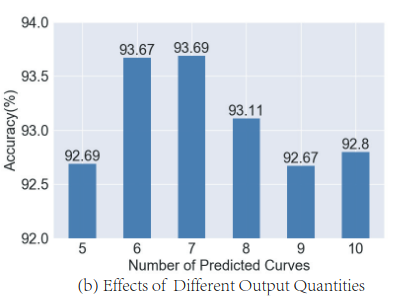
Number of predicted curves
4.3 Transfer Results on FVL Dataset
推荐阅读
![]()
添加极市小助手微信(ID : cvmart2),备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳),即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群:每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
觉得有用麻烦给个在看啦~
![]()


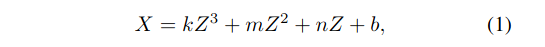
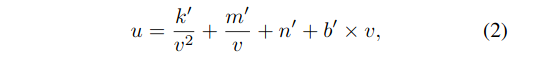

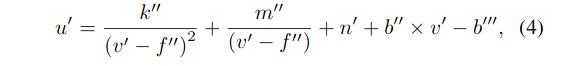
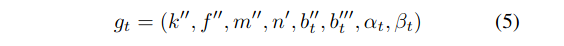
 (0: non-lane, 1: lane)。
(0: non-lane, 1: lane)。