谷歌、CMU重磅论文:Transformer升级版,评估速度提升超1800倍!

新智元报道
新智元报道
来源: arxiv
编辑:肖琴
【新智元导读】CMU、谷歌大脑的研究者最新提出万用NLP模型Transformer的升级版——Transformer-XL。这个新架构在5个数据集上都获得了强大的结果,在评估中甚至比原始Transformer快1800+倍。研究人员公开了代码、预训练模型和超参数。
Transformer是谷歌在2017年提出的一个革新性的NLP框架,相信大家对那篇经典论文吸睛的标题仍印象深刻:Attention Is All You Need。
自那以来,业内人士表示,在机器翻译领域,Transformer 已经几乎全面取代 RNN。总之 Transformer 确实是一个非常有效且应用广泛的结构,应该可以算是自 seq2seq 之后又一次 “革命”。
最近,CMU的Zihang Dai,Yiming Yang,Jaime Carbonell,Ruslan Salakhutdinov,以及谷歌的Zhilin Yang(杨值麟),William W. Cohen和Quoc V. Le等人提出了Transformer的升级版——Transformer-XL。这篇论文最初投给ICLR 2019,最新放在arXiv的版本更新了更好的结果,并公开了代码、预训练模型和超参数。

论文地址:
https://arxiv.org/pdf/1901.02860.pdf
Transformer网络具有学习较长期依赖关系的潜力,但是在语言建模的设置中受到固定长度上下文(fixed-length context)的限制。
作为一种解决方案,这篇论文提出一种新的神经网络结构——Transformer-XL,它使Transformer能够在不破坏时间一致性的情况下学习固定长度以外的依赖性。
具体来说,Transformer-XL由一个segment-level的递归机制和一种新的位置编码方案组成。这一方法不仅能够捕获长期依赖关系,而且解决了上下文碎片的问题。
实验结果表明, Transformer-XL学习的依赖关系比RNN长80%,比vanilla Transformer长450%,在短序列和长序列上都获得了更好的性能,并且在评估中比vanilla Transformer快1800+倍。
此外,Transformer-XL在5个数据集上都获得了强大的结果。研究人员在enwiki8上将bpc/perplexity的最新 state-of-the-art(SoTA)结果从1.06提高到0.99,在text8上从1.13提高到1.08,在WikiText-103上从20.5提高到18.3,在One Billion Word, 上从23.7提高到21.8,在Penn Treebank上从55.3提高到54.5。
他们公布了代码、预训练模型和超参数,在Tensorflow和PyTorch中都可用。
为了解决前面提到的固定长度上下文的限制,Transformer-XL这个新架构(其中XL表示extra long)将递归(recurrence)的概念引入到self-attention网络中。
具体来说,我们不再从头开始计算每个新的段(segment)的隐藏状态,而是重用(reuse)在前一段中获得的隐藏状态。被重用的隐藏状态用作当前段的memory,这就在段之间建立一个循环连接。
因此,建模非常长期的依赖关系成为可能,因为信息可以通过循环连接传播。同时,从上一段传递信息也可以解决上下文碎片(context fragmentation)的问题。
更重要的是,我们展示了使用相对位置编码而不是绝对位置编码的必要性,以便在不造成时间混乱的情况下实现状态重用。因此,我们提出了一个简单但更有效的相对位置编码公式,该公式可以推广到比训练中观察到的更长的attention lengths。
原始Transformer模型
为了将Transformer或self-attention应用到语言建模中,核心问题是如何训练Transformer有效地将任意长的上下文编码为固定大小的表示。给定无限内存和计算,一个简单的解决方案是使用无条件Transformer解码器处理整个上下文序列,类似于前馈神经网络。然而,在实践中,由于资源有限,这通常是不可行的。
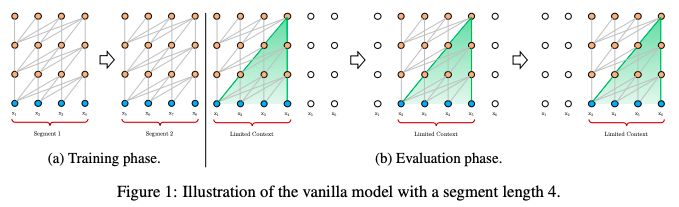
图1:一个segment长度为4的vanilla model的图示
一种可行但比较粗略的近似方法是将整个语料库分割成可管理大小的更短的片段,只在每个片段中训练模型,忽略来自前一段的所有上下文信息。这是Al-Rfou et al(2018)提出的想法,我们称之为原始模型(vanilla model),它的图示如图1a。
在评估过程中,vanilla 模型在每个步骤都消耗与训练期间相同长度的一个segment,但是在最后一个位置只是进行一次预测。然后,在下一步中,这个segment只向右移动一个位置,新的segment必须从头开始处理。
如图1b所示,该过程保证了每个预测在训练过程中利用的上下文尽可能长,同时也缓解了训练过程中遇到的上下文碎片问题。然而,这个评估过程成本是非常高的。
接下来,我们将展示我们所提出的架构能够大大提高评估速度。
Transformer-XL
为了解决固定长度上下文的局限性,我们建议在Transformer架构中引入一种递归机制(recurrence mechanism)。
在训练过程中,对上一个segment计算的隐藏状态序列进行修复,并在模型处理下一个新的segment时将其缓存为可重用的扩展上下文,如图2a所示。
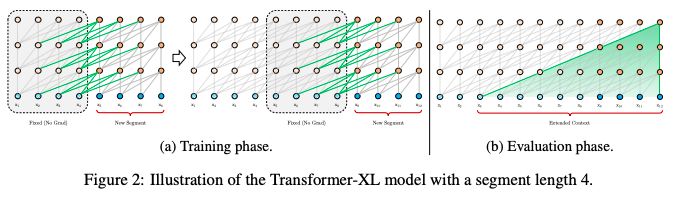
图2:一个segment长度为4的Transformer-XL模型
这种递归机制应用于整个语料库的每两个连续的segment,它本质上是在隐藏状态中创建一个segment-level 的递归。因此,所使用的有效上下文可以远远超出两个segments。
除了实现超长的上下文和解决碎片问题外,这种递归方案的另一个好处是显著加快了评估速度。
具体地说,在评估期间,可以重用前面部分的表示,而不是像普通模型那样从头开始计算。在enwiki8数据集的实验中,Transformer-XL在评估过程比普通模型快1800倍以上。
我们将Transformer-XL应用于单词级和字符级语言建模的各种数据集,与state-of-the-art 的系统进行了比较,包括WikiText-103 (Merity et al., 2016), enwiki8 (LLC, 2009), text8 (LLC, 2009), One Billion Word (Chelba et al., 2013), 以及 Penn Treebank (Mikolov & Zweig, 2012).
实验结果表明, Transformer-XL学习的依赖关系比RNN长80%,比vanilla Transformer长450%,在短序列和长序列上都获得了更好的性能,并且在评估中比vanilla Transformer快1800+倍。
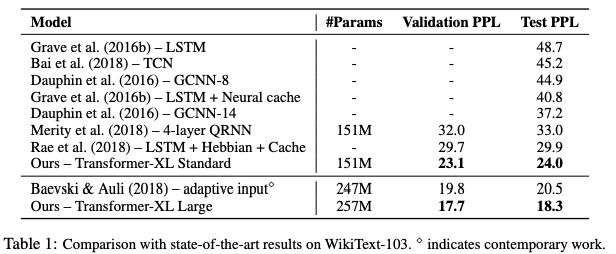
表1:在WikiText-103上与SoTA结果的比较
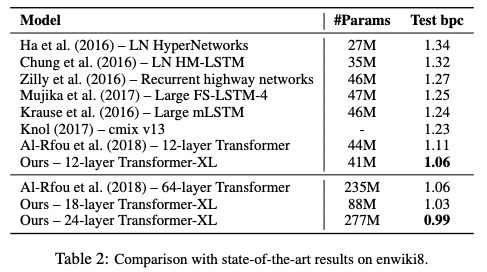
表2:在enwiki8上与SoTA结果的比较
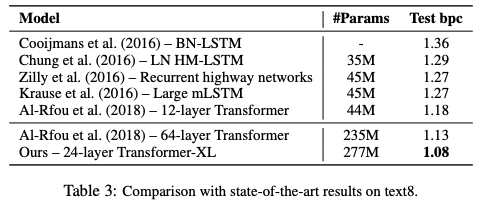
表3:在text8上与SoTA结果的比较
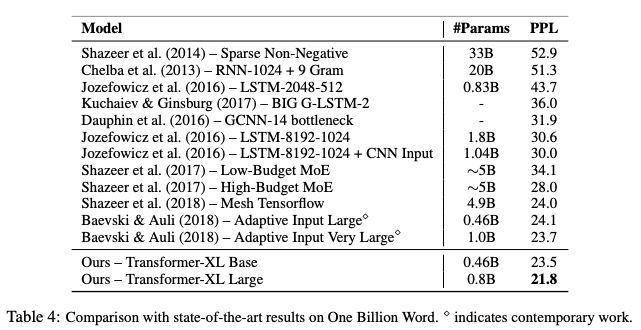
表4:在One Billion Word上与SoTA结果的比较
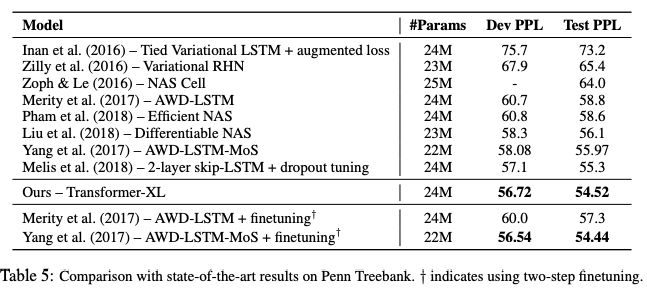
表5:在Penn Treebank上与SoTA结果的比较
Transformer-XL在5个数据集上都获得了强大的结果。研究人员在enwiki8上将bpc/perplexity的最新 state-of-the-art(SoTA)结果从1.06提高到0.99,在text8上从1.13提高到1.08,在WikiText-103上从20.5提高到18.3,在One Billion Word上从23.7提高到21.8,在Penn Treebank上从55.3提高到54.5。
评估速度
最后,我们将模型的评估速度与vanilla Transformer模型进行了比较。
如表9所示,与Al-Rfou et al. (2018).的架构相比,由于state reuse方案,Transformer-XL的评估速度加快了高达1874倍。
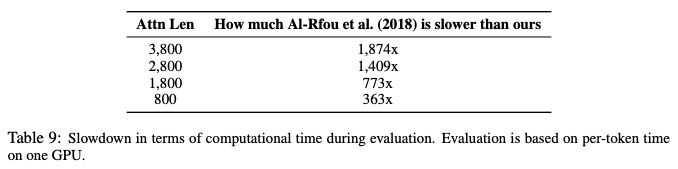
表9:评估时间比较
我们提出了一种新的架构,Transformer-XL,这是一个超出了固定长度的上下文限制的self-attention的语言建模架构。
我们的主要技术贡献包括在一个纯粹的 self-attentive 模型中引入递归的概念,并推导出一种新的位置编码方案。这两种技术形成了一套完整的解决方案,因为它们中的任何一种单独都不能解决固定长度上下文的问题。
Transformer-XL是第一个在字符级和单词级语言建模方面都取得了比RNN更好结果的self-attention模型。Transformer-XL还能够建模比RNN和Transformer更长期的依赖关系,并且与vanilla Transformers相比在评估过程中取得了显著的加速。
论文地址:
https://arxiv.org/pdf/1901.02860.pdf
【加入社群】
新智元AI技术+产业社群招募中,欢迎对AI技术+产业落地感兴趣的同学,加小助手微信号:aiera2015_2 入群;通过审核后我们将邀请进群,加入社群后务必修改群备注(姓名 - 公司 - 职位;专业群审核较严,敬请谅解)。



