Hot Chips 30 - 巨头们亮“肌肉”
本次Hot Chips贡献内容最多的是三家:Google是互联网巨头,芯片领域的后来者;Nvidia是目前最热的芯片公司;而FPGA巨头Xilinx,这次是新CEO亲自上阵。可以说三家是各秀肌肉。
•••
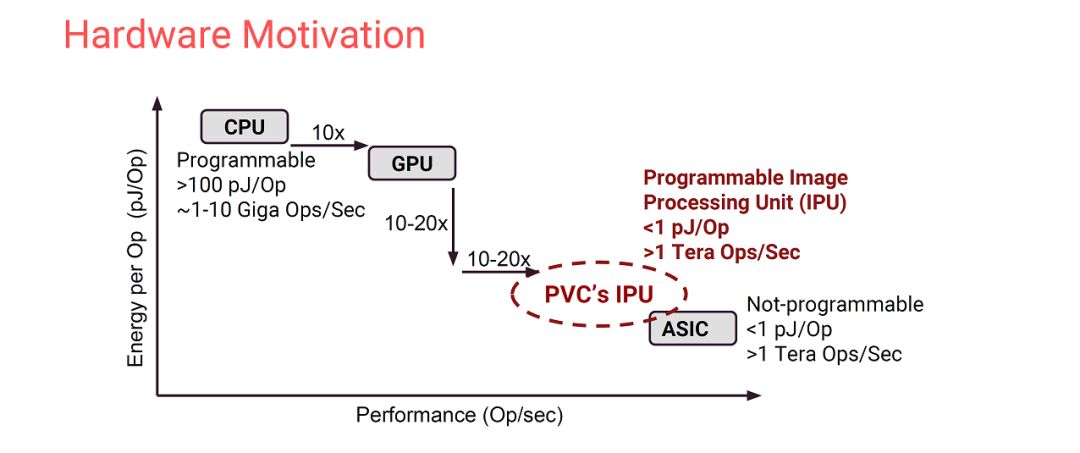
Google在本次会议上的重头戏是“Spectre/Meltdown The era of security: Introduction”,这个我们在之前的文章已经做了比较详细的介绍(Hot Chips 30,黄金时代的缩影)。另一个关于安全芯片的talk也不再赘述。下面重点看看他们的“ThePixel Visual Core: Google’s Fully Programmable Image, Vision and AI Processor for Mobile Devices”。Google的VPU是我一直想详细讨论一下的内容,只是一直没有找到时间。之所以对它有很大兴趣,是因为它是Domain-SpecificArchitecture非常典型的,写进了教科书(体系结构经典书“Computer Architecture: A Quantitative Approach”最新版帝章)的例子。简单来说,1. 它有明确的应用场景;2.它支持专门的语言Halide(DSL:Domain-SpecificLanguage);3. 它设计了专门的架构(包括专门的指令集和微结构);4. 它开发了专门的编译工具。第一点的应用场景比较简单,就是智能的照片处理,即Google的HDR+。下面两页slides分别从软件和硬件的角度介绍了设计VPU的动力所在。

在架构层面,VPU采用两级指令集架构,virtual ISA(vISA)和physical ISA(pISA),对应两级编译流程。具体的指令集并没有在这个talk里介绍,大家可以参考“量化”里更具体的讨论。


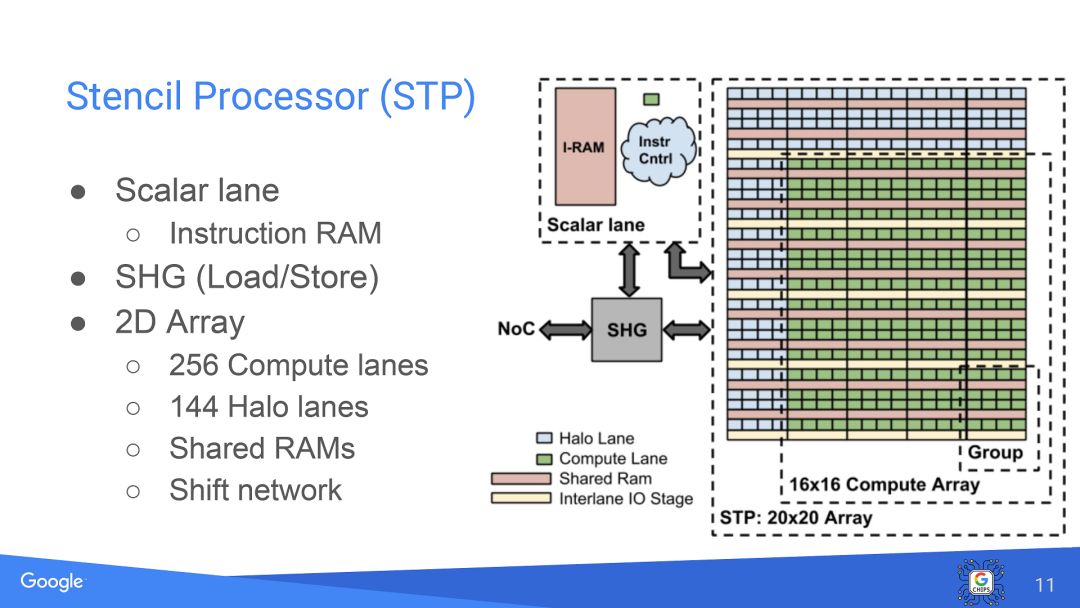
硬件架构方面,VPU采用了很多专门的设计,比如下图这个Stencil Processor就是完全根据2D图像特点设计的。
再比如下图互联网络也是根据图像处理特点设计。类似的还有运算通道(Compute lane),Line Buffer Pool和Virtually Tall Line Buffer等等。
在问答环节中回答问题的时候,讲演者也提到,为了实现可编程性,需要专门的工具链,而开发工具链往往比硬件还要耗时。
Google的芯片实力是从TPU开始引起人们关注的,而VPU从另一个侧面展示了Google在DSA方面的“肌肉”。Google本来在DSL和compiler上都有很强的实力,目前又招募了大量芯片架构的人才(包括David Patterson这个级别的),未来有可能会在更多Domain发力。
•••
Nvidia在本次Hot Chips上的三个talk,NVDLA我们之前已经做了介绍。下面主要看看Xavier和NVSwitch。首先是“NVIDIA’s Xavier System-on-Chip”。Xavier是Nvidia专门面向自动驾驶的芯片,这次应该是第一次比较详细的透露相关信息。总结起来一句话,虽然是不是“ world first”有待商榷,可以肯定的是Xavier给自动驾驶芯片设定了一个新的标杆。
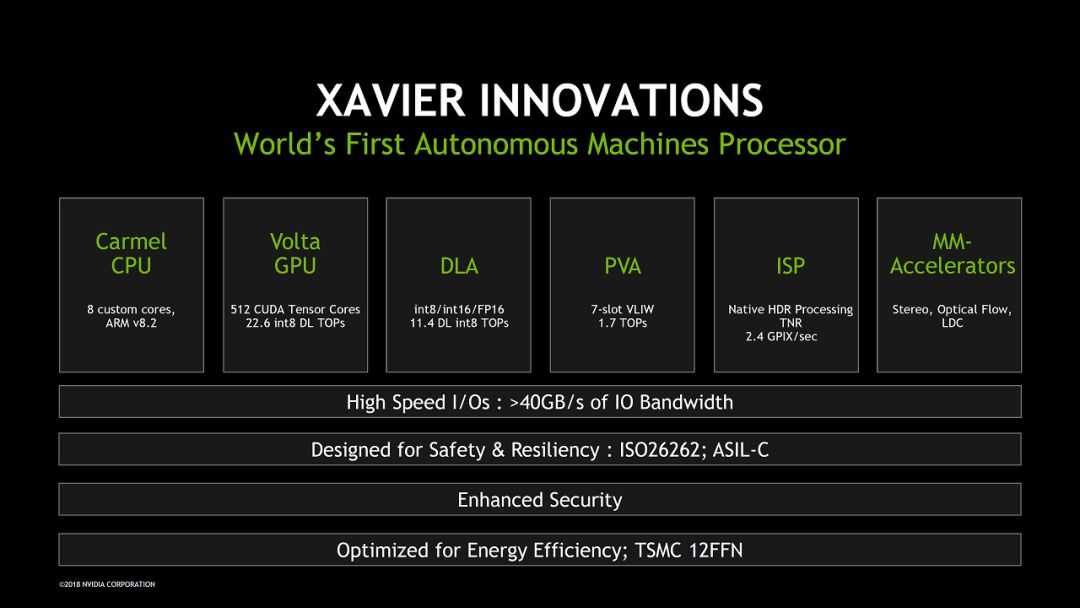
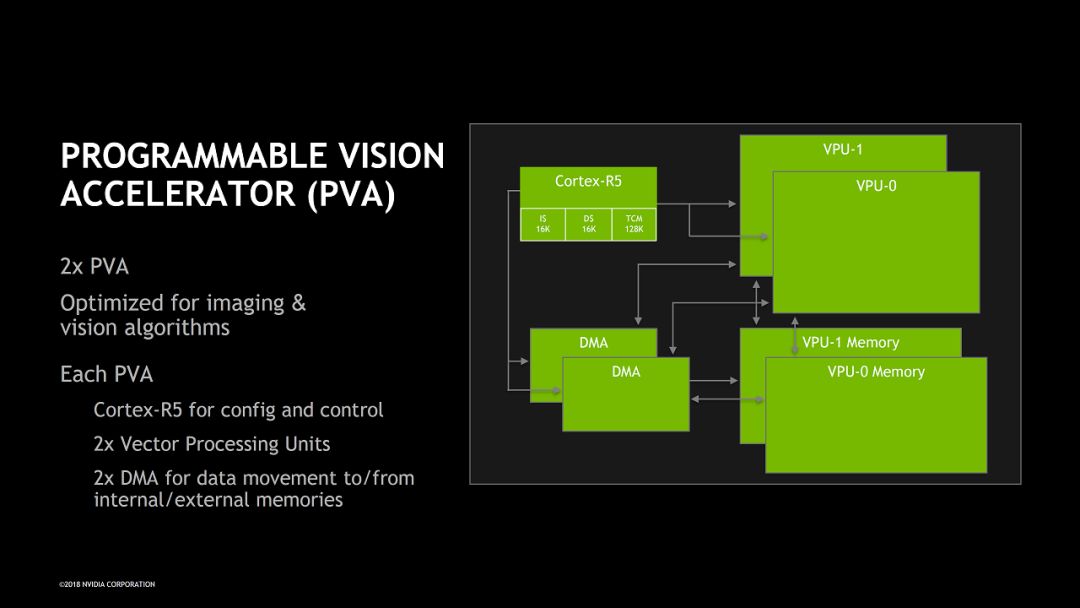
具体来看,CPU/GPU/DLA部分我们之前已经比较了解了,ISP和MM-Accelerator是专门的硬件加速,也没有太多可说的。PVA(Programmable Vision Accelerator)比较新鲜一些。如下图所示,PVA主要包括了两个VPU(Vector Processing Unit),是比较典型的VLIW/SIMD向量处理器,VLIW支持7条指令并行。另外PVA里还有一个ARM Cortex-R5 CPU实现配置和控制功能。PVA应该主要用来处理传统的CV算法。

Xavier中做视频处理的模块包括了PVA,DLA,GPU,SOFE和ISP&VIC,其视频处理能力非常强劲,下图对不同模块加速的任务和实现的吞吐率进行了总结。比较有意思的是在吞吐率部分还是比较清楚的区分了不同类型的处理能力。比如PVA就是CV TOPS。

虽然看起来Xavier中的各类加速器可以各司其职,发挥最大的效率,不过这么复杂的异构SoC 怎么编程还是个无法回避的问题。最近Nvidia已经开始了“NVIDIA Jetson Xavier Developer Kit”(外形如下图)的Pre-order,价格$2,499,我们还是看实际效果吧。

Source:Nvidia.com
最后用这张图总结一下,“~8,000 Engineering Years”是否也算给竞争者的压力呢。

第二个是“NVSwitch and DGX-2 – NVIDIA’s NVLink-Switching Chip and Scale-Up GPU-Compute Server”,覆盖的NVSwitch和DGX-2系统的内容。我们先看看Summary吧,毫不夸张的说,DGX-2确实是展示了“工程之美”。

具体到NVSwitch,这次公开了一些新的细节和设计理念。它解决的问题可以用下面两个图来说明。基本目标也比较简单,就是可以高效的让一个GPU访问另一个GPU存储空间,从而让多个GPU连接在一起构成一个“ONE GIGANTIC GPU”
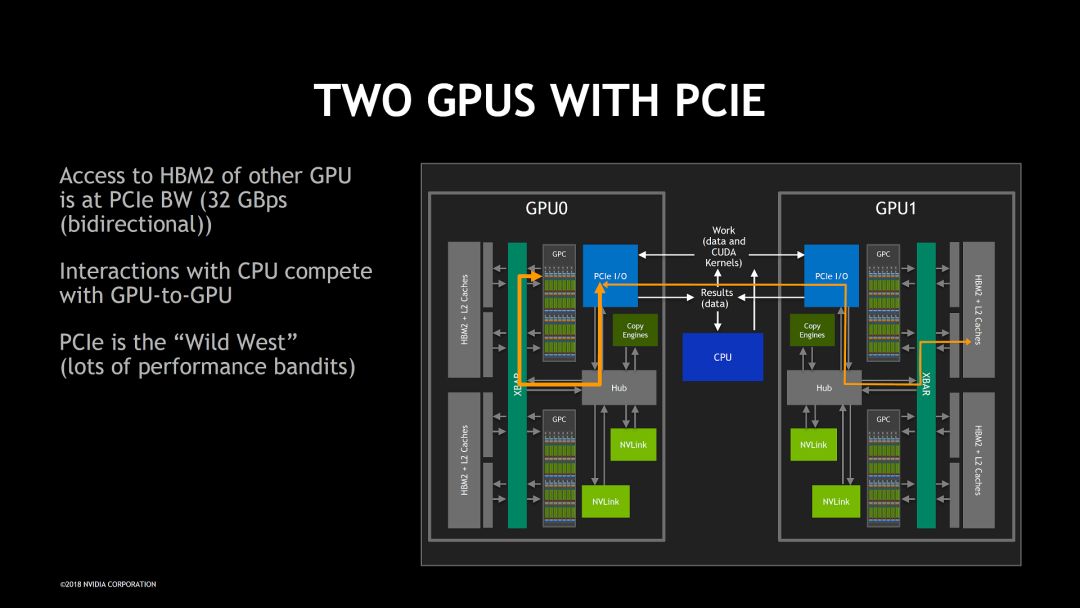
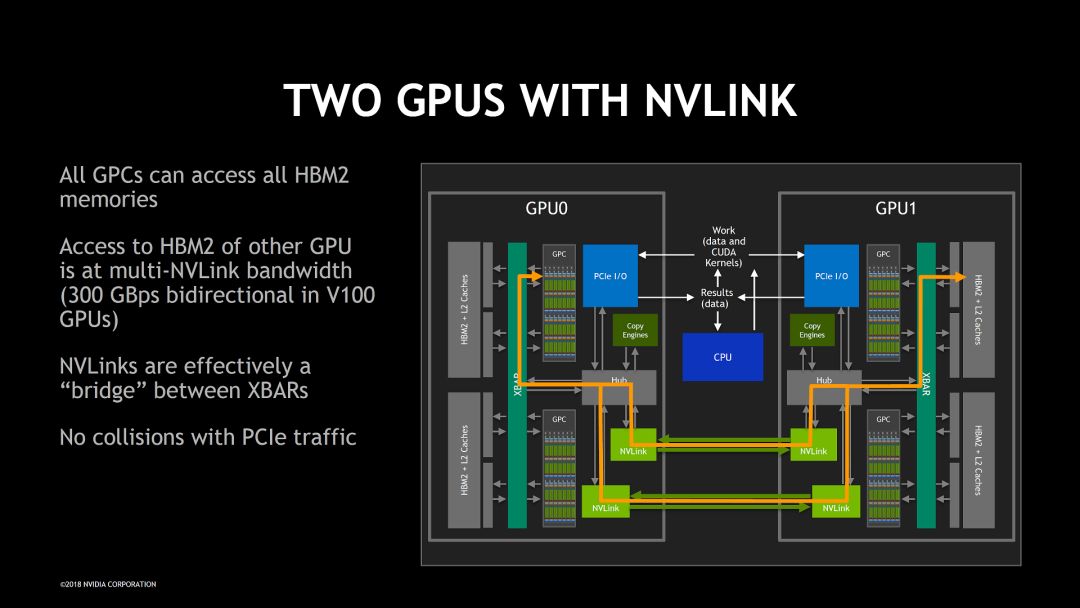
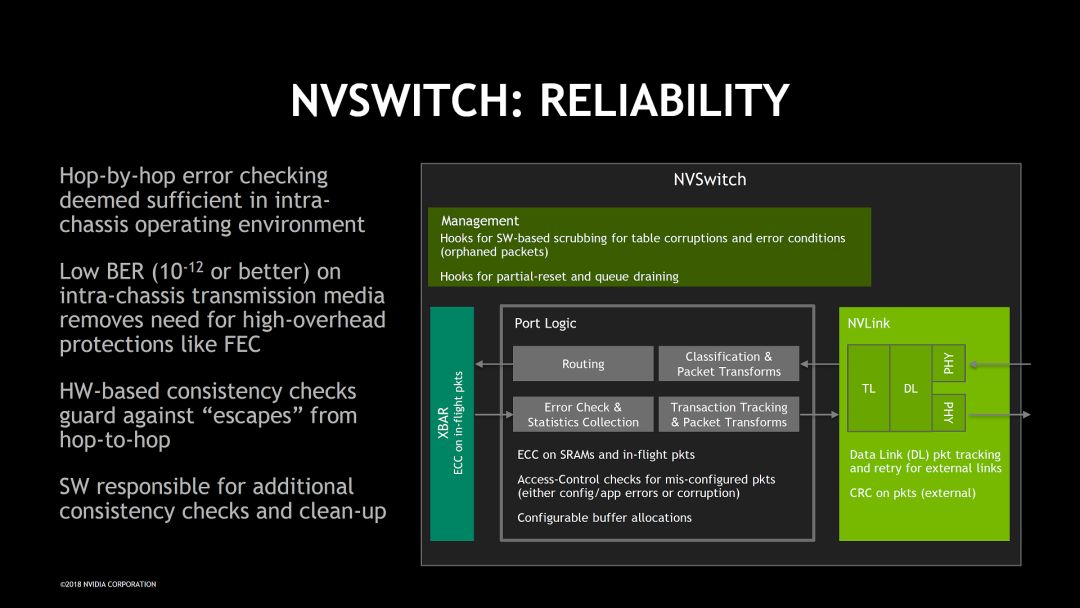
由于NVSwitch的目标非常明确,重点是高带宽,低延时和无阻塞,其它的问题尽量简单处理。比如在考虑可靠性设计的时候,根据机箱工作环境比较可靠的特点没有使用代价高的纠错方式。
讲演中关于DGX-2系统的介绍我就不多说了。在Nvidia展示部分收摊之前,我拍了HGX-2 baseboard的照片,大家可以感受一下。

总得来说,Nvidia在泛AI芯片,核心技术和软件工具上的优势还是非常明显的,甚至还有逐渐扩大优势的趋势。目前还没有看到能和Nvidia正面竞争的厂商,这可能也是其股票最近又创新高的原因。
•••
Xilinx在本次Hot Chips上贡献的内容也很多,之前的文章中我介绍了深鉴的工作和xDNN的工作。下面重点看一下在这次会议上首次公开细节的“Xilinx Project Everest: ‘HW/SW Programmable Engine’”。
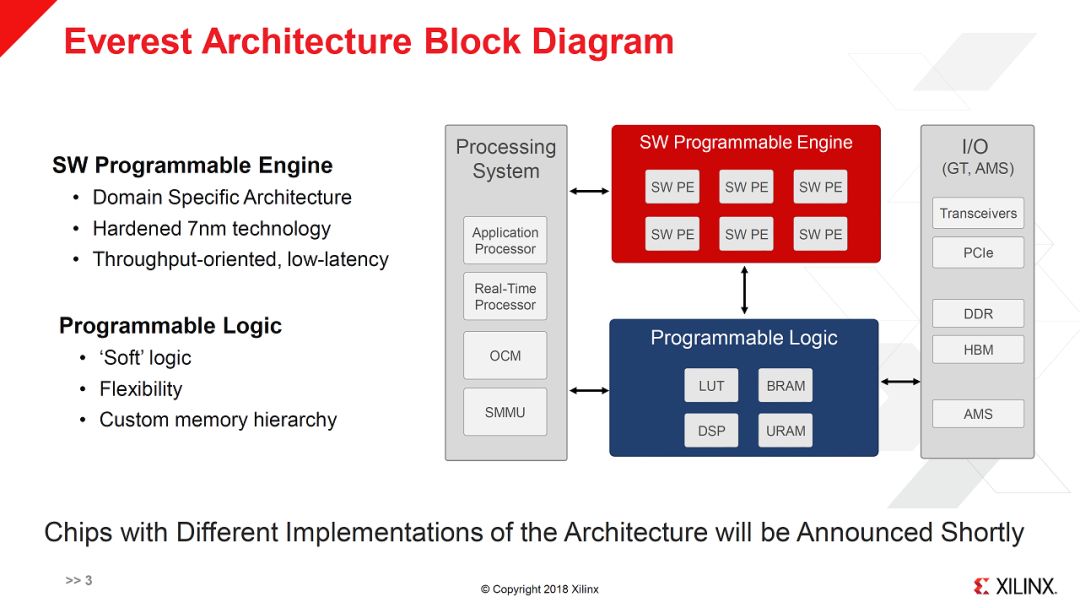
上图即为Everest项目(官方名称是ACAP:Adaptive Compute Acceleration Platform)的架构框图,其重点是在Xilinx传统的FPGA SoC基础上增加了“SW Programmable Engine”。换句话说,在未来的平台(2019年)中,除了现在有的CPU,FPGA logic(PL:Programable Logic),又有了一个新的可编程架构,SWPE。下面我们就来详细看看。
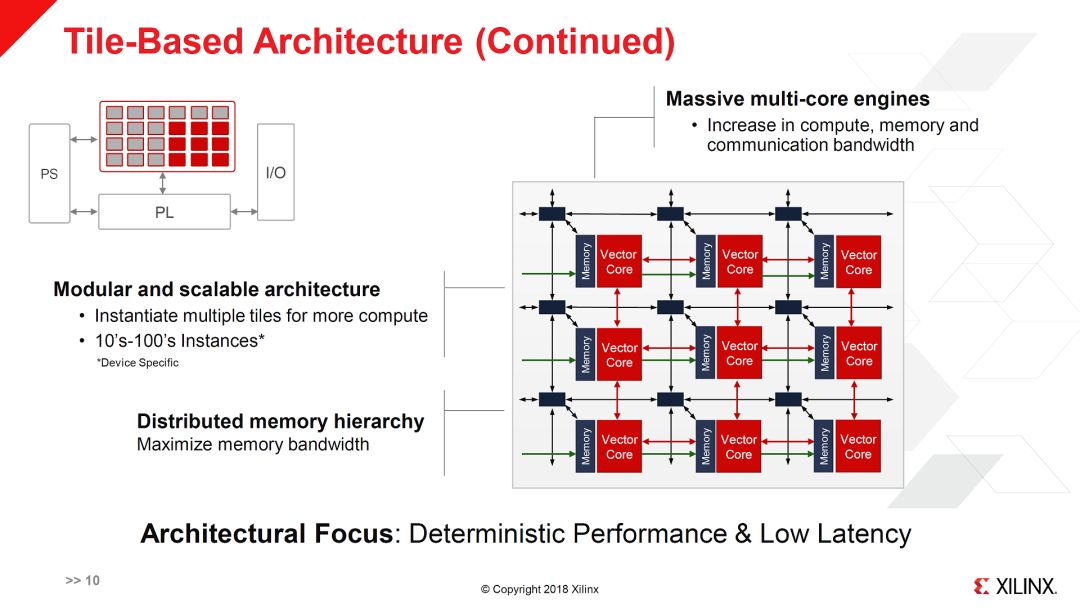
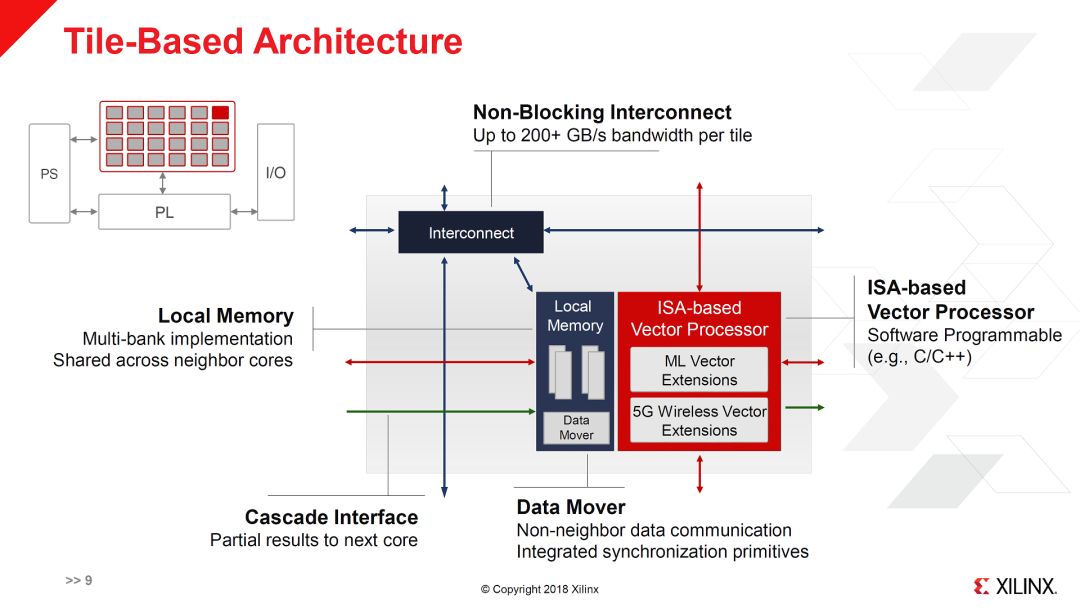
如上面两图所示,SWPE实际上是由多个Vector Core组成的2D Mesh网络。每个Vector Core有自己的指令集和本地存储以及DMA。其指令集应该包括基本指令集,机器学习指令集扩展和5G指令集扩展。目前还不知道Vector Core具体的数量,假设按不同级别的芯片,“10‘s-100’s Instances”,每个instance就是图中的3x3的配置,那么总的core数量大概是100-1000个(这也比较符合Massive multi-core的说法)。如果是这样的数量,每个core不太可能做的很大。因此,ML和5G的向量指令应该也不会很宽。这就会有效率的问题,特别是对于ML应用。另外一个疑问是ML和5G的扩展硬件(对应于扩展指令集)是同时存在的?还是不同的芯片有不同的选择。虽然5G和ML在一些矩阵运算上有类似需求,但还有一些其它的运算,如果硬件不能重用,会产生一些浪费。
之所以增加SWPE,当然是因为ML和5G里有很多运算,用传统的Programable Logic加速的效率比较低。对此,Xilinx给出了典型应用,ML Inference和5G wireless映射到Everest架构上的例子。
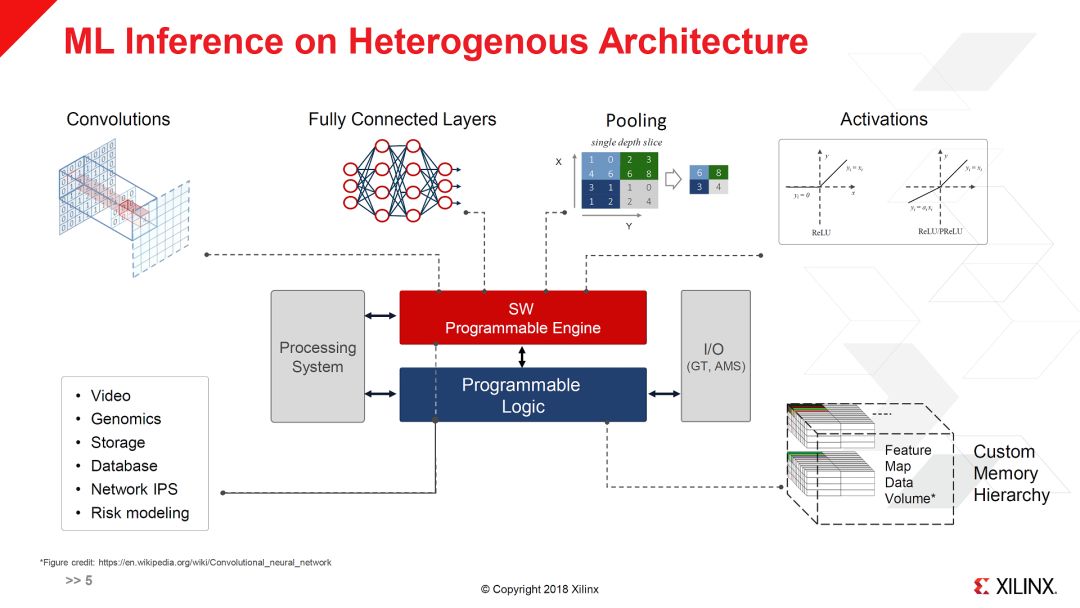
从上图看来,ML Inference的大部分运算都可以在SWPE中实现,此外相关的一些应用,比如图像处理等也可以放在SWPE。而Programable Logic则主要做I/O和数据操作。
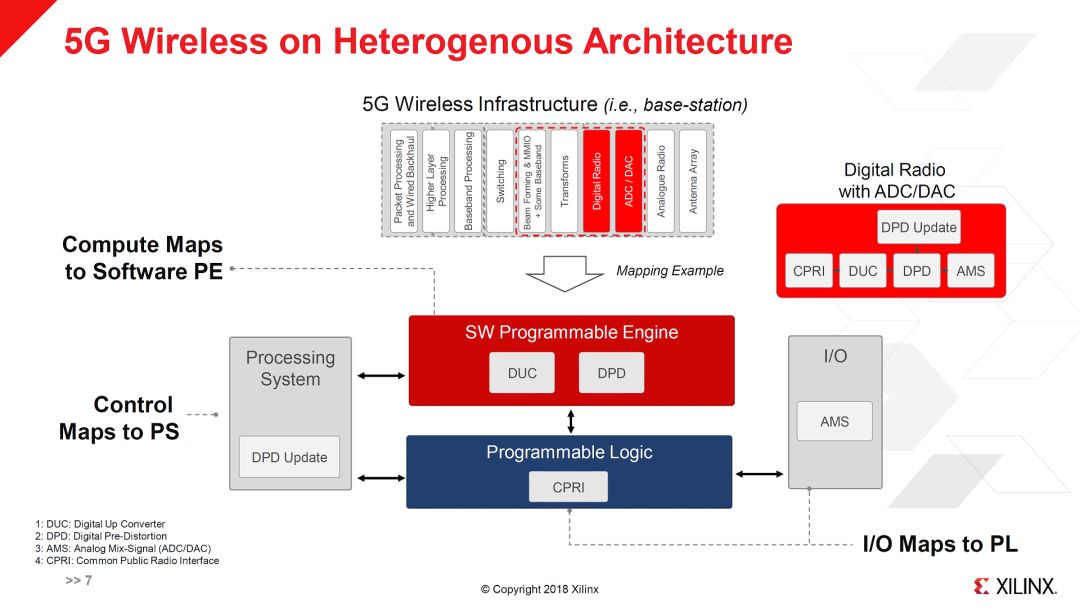
在5G Wireless中,值得注意的是Everest中有很多Digital Radio相关的资源,这个是比较有Xilinx特色的(目前Xilinx就有专门的RFSoC)。Xilinx的FPGA在无线基站中用的不少,从这里也可以看出Xilinx对5G的理解还是很深的。
此外,在这个talk里还强调了数据搬移的效率,包括SWPE中的vector core之间的数据搬移以及SWPE和Program Logic之间的数据搬移。还是那句话,在多核异构系统中数据流动的效率才是关键。从这一点来说,Xilinx的优势是可以用Program Logic来做Glue logic,可以实现很灵活的重构。比如下图就是一个PL和SWPE配合的例子。
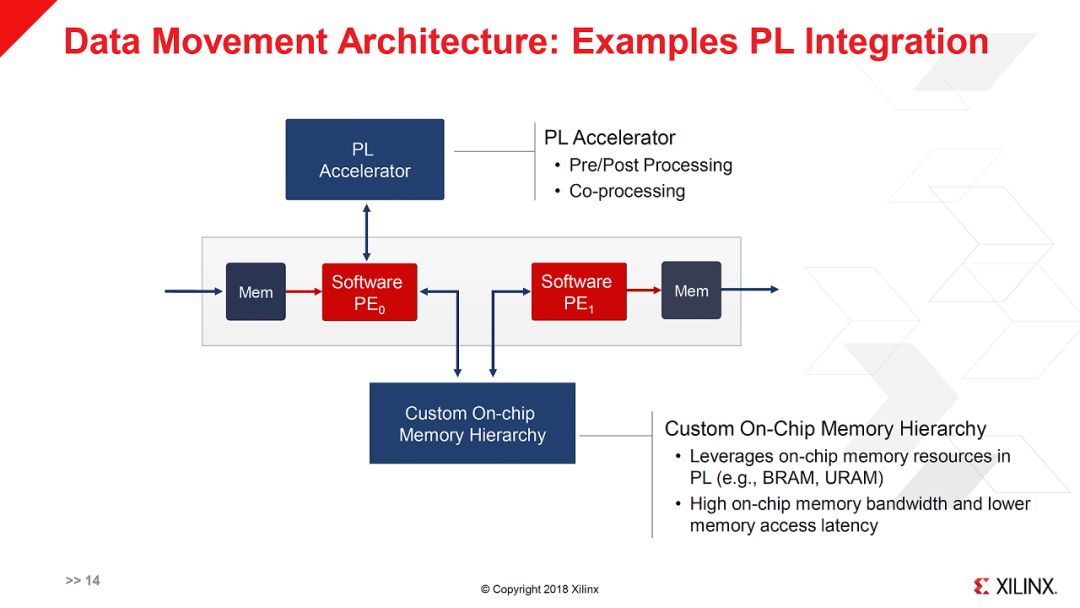
相应的,要实现对这样一个异构系统的编程,就需要完整的工具链,如下图所示。
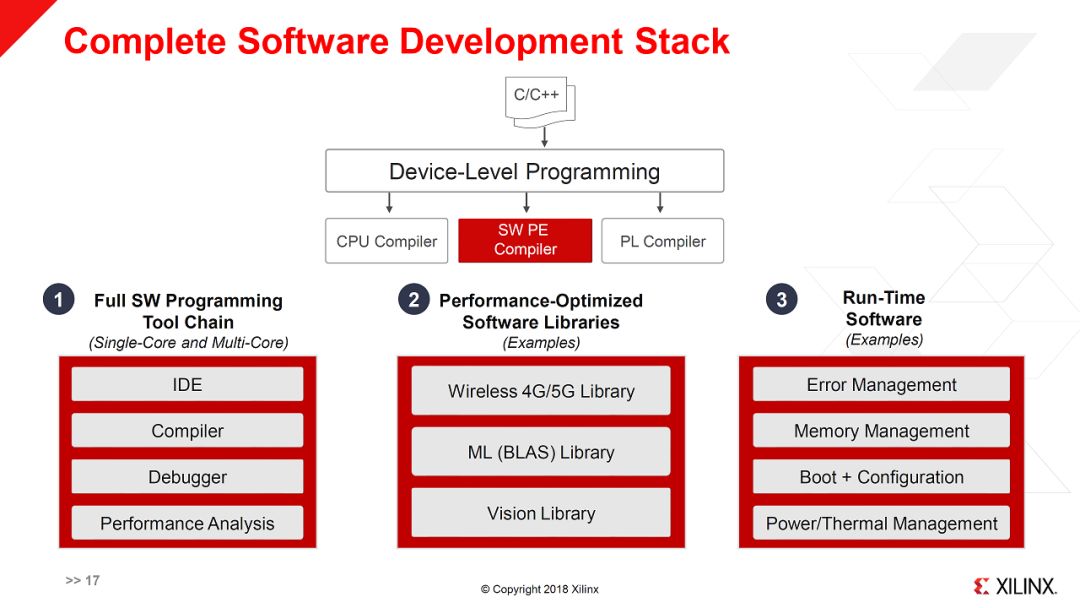
总得来说,这次Hot Chips会议上,Xilinx展示出来很大的野心。其新推出的Everest架构试图通过增加更粗粒度的Multi-core编程架构,解决传统FPGA逻辑针对特定应用效率较低问题,形成灵活的异构可重构系统,覆盖更多的应用场景。理想看起来美好,实际操作还是有很大挑战的。本来FPGA就有一定的“编程”门槛,现在又增加了新架构,使用这个系统的门槛就更高了。如何让用户有效利用这些资源是个大问题。如果做不到,“肌肉”就会变成“赘肉”,优势反而可能变成劣势。
- END-
题图来自网络,版权归原作者所有
本文中引用的幻灯片均来自Hot Chips 30,仅供学术讨论
本文为个人兴趣之作,仅代表本人观点,与就职单位无关






