强化学习 DQN 初探之2048

文章作者:张小凡
编辑整理:Hoh Xil
内容来源:作者授权发布
出品平台:DataFunTalk
注:欢迎转载,转载请留言。
导读:强化学习也火了好久,最近才有空来充充电。老实说,最开始强化学习的知识点还挺多的,看了好久也没太弄清楚几个算法的关系,所以本着实践出真知的想法,找个案例做下。2048小游戏感觉本身复杂度还可以,又是个 model-base 的模型,检查起来比较方便,并且可以简化到2x2,3x3,所以感觉是个很不错的 demo 案例。顺便学习下传统的 DP 那一套东西,所以也做了一些很简单的实验来巩固下知识。本文还是会参杂很多个人想法,很多想法来自一些实验测试结果。关于理论的东西网上讲的已经很多了。因为查阅资料的时候,看到很多人在尝试 DQN on 2048 的时候遇到了不少问题,所以和大家进行下分享。
▌最终效果
大概率能玩出2048
最高可以玩 3w 多分
均值 1w 多分
仍有上升空间 ( 可能有啥 bug,跑久了容易挂,就没继续跑了 )
网上能查到的比较厉害的差不多到4096 (AI),比例也比较小。
▌实验过程
1. 随机测试:
定义:
max_tile:4x4格子中最大方块数
max_score:n局下来最大总分数 ( n in 50-100 )
avg_score:n局平均分数 ( n in 50-100 )
4x4的游戏中随机算法评测:
max_tile:256
avg_score:700+
max_score:2k+
这里大概评估下随机水平,方便后面评估。
2. DQN 初探:
按照自己的想法构建了一个最初版本的 DQN
net:4*4直接reshape(-1,16) - dense_layer(128) - dense_layer_(4)
memory_sie:100w
lr:0.001(固定)
reward:每次运行后得分
gamma(延迟衰减):1
e-greedy:指数衰减,最小0.1
结果:网络到 max_score:3000 之后,好像跑不动了。这里一脸蒙,不知道有啥可以改的。于是发现这个事情并不简单,就想简化问题到2x2看看能不能有啥收货,顺便补习下传统的一些 RL 算法,验证下最优原理。
▌值迭代、策略迭代、蒙特卡洛、Q-learning
1. 值迭代:

2. 策略迭代:

值迭代、策略迭代、蒙特卡洛、Q-learning:2*2上可以快速收敛。
Q-learning 感觉会稍微有点波动。
3. DQN 在2x2
当用值迭代、策略迭代得到了理论最优值之后,又用 DQN 测试了一把。发现 DQN 结果比最优值总是差点,这就说明网络和学习策略确实有点问题,但同时侧面又反映了,2x2的时候能很接近最优策略,4x4差的比较远,那么很大部分问题可能来自参数化和探索方面。(空间变大会涉及到的点)
总结几个提升慢原因:
没有找到足够高分的点训练
-
e-greedy -
游戏本身随机性
找到高分点后,没有训练到
被训练数据淹没-memory_size
lr 和高分没有匹配上,太小了
reward 设计不合理
4. DQN-2013 + 网络层迭代、bug 修复
从2x2的地方看出,参数化有问题,那么第一个想法就是优化下网络,dnn 还是太粗暴了,还是得 cnn,这里就有几个方案:
原始值 + cnn
one-hot + cnn
emb + cnn
cur + next-step + cnn(github上看到别人的做法,借鉴的alphaGoZero)
新版本改进:修复了探索的 bug,reward 做了 log 变化,网络换成了 emb+cnn,新结果如下:
max_score:6000
max_tile:1024
但是问题也暴露的很明显:
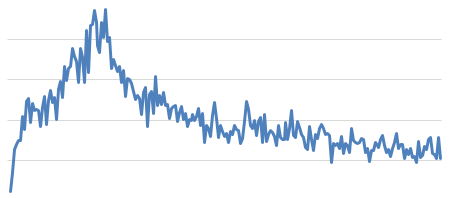
loss 出现了非常夸张的发散问题,预测值过估计严重。如下图,大概意思就是 loss 变得巨大无比之后,效果就开始变差,loss 也下来了。
5. DDQN/DQN2015
一般讲 DQN 的三个优化:DDQN/Prioritized Experience Replay/dueling-DQN
DDQN/DQN2015 的两个方案在2048的案例中都没有啥效果,过估计仍然很严重。
后面两个没有提到对过估计的问题,所以没有尝试。
dueling-dqn 在别人的一篇文章中有测试,dueling-dqn 比 ddqn 的上限要高,早期好像差别也不大。
到这里,其实有点调不下去了,后来在网上翻到了一个代码。能跑出2048,天呐,发现宝了,做了很多测试,发现我和他的方案上差异还是蛮大的,然后就开始了一点点比较的阶段。
6. 复现 Github 方案
先提出别人和我方案的差异点:
lr别人用了离散衰减,start-lr = 0.0005
reward:用了max_tile增量+合并单元数
memory_size:6000!!!
更新方案:dqn2013,没用target
gamma:0.9
egreedy:0.9,10000步后快速收敛到0
net:一个比较定制化的one-hot + cnn
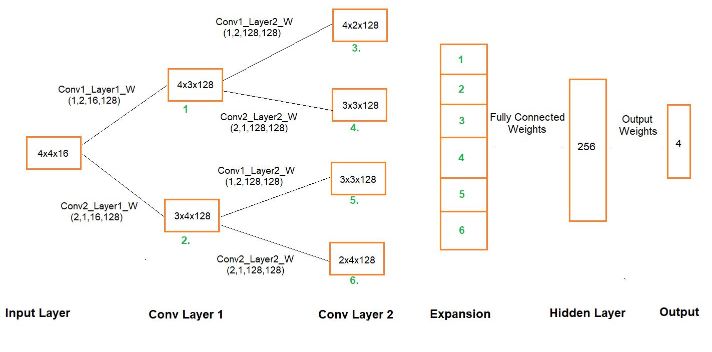
我在他的方案上做了一系列实验:
实验1:把 e-greedy 改成最小0.1
实验结果:
max_score 到 1w+ 后开始增长变得很慢,很久都没有提升。说明该任务本身具有比较强的前后相关性和随机性,最终还保持较高的探索难以发现最佳值。
实验2:用数值网络代替 one-hot+cnn
实验结果:
提升没有之前快了,这个实验没跑完就挂了,但是 raw 的效果不如 cnn。说明网络结构影响比较大
实验3:reward 改成每步获取 score
监控几乎和之前差不多,说明两个 reward 设计都可行。
实验4:在原基础上只用 max_tile 来作为回报,拿掉合并分数
无法达到2048,在1024前就好像不涨了。说明 reward 也不能设计的太随意,要保持和训练方案比较高的协调性,只用 max 的话,reward 会比较稀疏。
在做完上述一系列实验后,我大致有了个数,然后对自己的实验进行了优化。
优化方案:
lr设计成离散衰减
gamma:1 (没变)
reward:score (没变)
更新方案:dqn-2013(没变)
memory_size:6000
egreedy:0.9指数衰减,10000步后快速收敛到0
net:emb+普通2*2的cnn2层 (不变)
结果:
max_score:3.4w
max_tile:2048
avg_score:10000
截张图看下:
2048
之后测试了下 ddqn,发现收敛比较。本身把 memory_size 设置小了之后,过估计就没有这么严重了。这里简单分下,过估计本身在 Q-learning 中就存在,回访池过大之后,训练越多,过估计越严重,在没有很好的高分数据前,就给搞过估计了,所以后面就不好迭代了。反而用小点的话,过估计不严重,在高分出现后也不会淹没在数据中,对于这个任务可能更好一点。很多结论可能都与这种需要长期规划的性质相关。
▌蒙特卡洛树搜索探索
出于对 alphaGo 的膜拜,我也想过,dqn 很多时候不好训练,就是很难拿到高分训练数据,能不能和 alphaGo 一样,用个 mcts,就简单做了下。结果如下:
纯蒙特卡洛树搜索的方案:每步模拟100-200,可以轻松到达2048,均值 2w+ ( 这里测试数据不多,跑的很慢,所以想用mcts来训练dqn的方案也被 pass 了 )。
1. 需要监控的点
loss:DQN 过估计严重,需要密切关注 loss 情况
max-label:如果没有出现过大值,看看探索过程是不是有问题。后期探索不能太大。
e-greedy:关注探索程度
episode:关注大致进度和速度
lr:这个和loss配合着看
评估指标:avg/max score
RL的任务感觉需要监控的内容更多,不光是监督学习的部分,探索的部分也很重要。
2. 训练情况
训练出2048,要2个小时左右。大概 2w episode 这个样子。
▌小结
到此,2048的探索可能就先告一段落,虽然很多事情并没有研究太明白。但是对于整个算法有了个基础的认识。并对算法中可能存在的优化点有了一些了解。后续可能会尝试下策略梯度那一趴的东西。
▌相关资料
对本文感兴趣的同学,欢迎点击文末阅读原文与作者交流。

文章推荐:

DataFun:
专注于大数据、人工智能领域的知识分享平台。

一个「在看」,一段时光!👇

