基于TensorFlow的LSTM简介:以股票市场文本情感分析为例
编者按:什么是LSTM?它的基本结构是什么?它能做哪些事?知名出版社O’Reilly和TensorFlow合作发表了一篇文章,讲述了利用TensorFlow搭建的多层LSTM,可以用来分析股票论坛中用户言论的情感,是LSTM在自然语言处理中的一个实例。本文作者为Garrett Hoffman。
近几年,有关长短期记忆(LSTM)网络的研究成果层出不穷,这一技术本身也日趋成熟,但事实上,LSTM网络自诞生至今已有20多年了。LSTM网络是循环神经网络(RNN)的一种,经常用于自然语言处理(NLP)的时序数据建模。相比传统的RNN,LSTM的优势在于它可以长时间保存信息,可以在序列前期学习获得重要的信息,从而在结尾模型决策时产生更大的影响。
本文将介绍LSTM网络的架构,并构建自己的LSTM网络,然后分析StockTwits网站上的股市情感文本信息。之所以使用TensorFlow,是因为它不仅提供了紧凑高级命令,而且TensorFlow的确深受大家的欢迎……
LSTM和网络架构
在开始搭建自己的网络之前,让我们先简单的介绍一下LSTM单元是如何工作的,以及LSTM网络的架构。
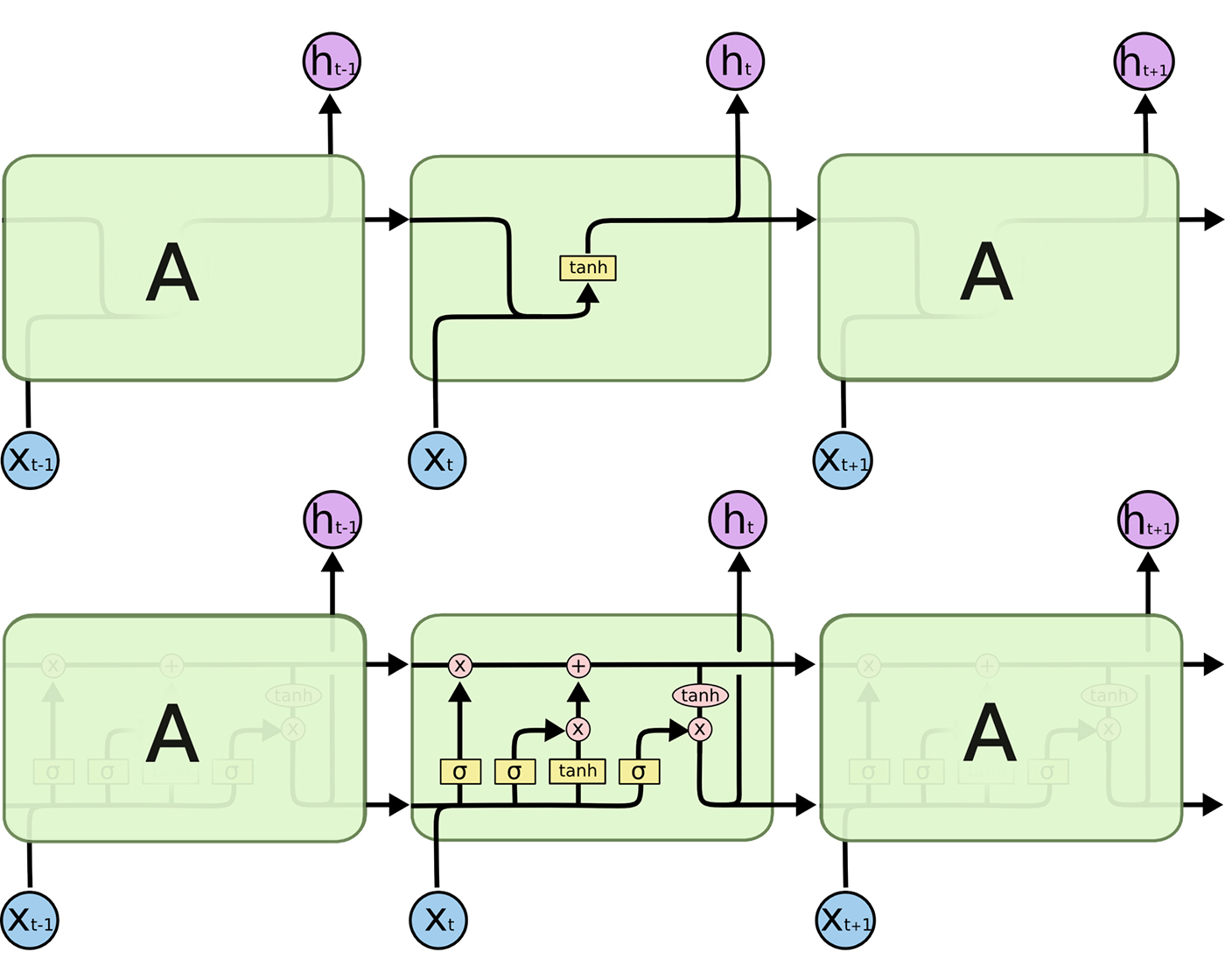
A表示一个完整的RNN单元,它接收序列的当前输入xi(在这一项目中,输入的是字),输出当前的隐藏状态hi,并将其传递到下一个RNN单元作为输入。LSTM单元的内部结构比传统的RNN单元复杂得多。传统的RNN只有一个“内层”,作为当前状态(ht-1)和输入(xt),而LSTM有三个。
首先是用于控制之前状态信息的“遗忘门”(forget gate)。遗忘门会读取之前层生成的ht-1并输入当前的xt,应用一个Sigmoid激活层,在每个隐藏层输出一个0到1之间的数值。接下来在当前状态进行对应元素相乘(上图中顶部第一个操作)。
第二个层被称为“更新门”(update gate),即基于当前输入更新状态。同样输入(ht-1)和(xt)到sigmoid激活层(σ)和tanh激活层(tanh),并将对应元素相乘。当“遗忘门”更新新信息后,用结果和当前状态让对应元素相加(上图中顶部第二个操作)。
最后是“输出门”(output gate),它可以控制哪些信息被传递到下一个状态,我们通过tanh激活层运行当前状态,并利用在sigmoid层上的单元输入(tanh)进行乘法运算,sigmoid层类似一个过滤器,决定我们输出什么内容。这个输出ht之后将作为输入传到下一个LSTM单元,也将传递到我们网络的下一层。
了解完LSTM单元的结构后,让我们看看LSTM网络的架构吧。
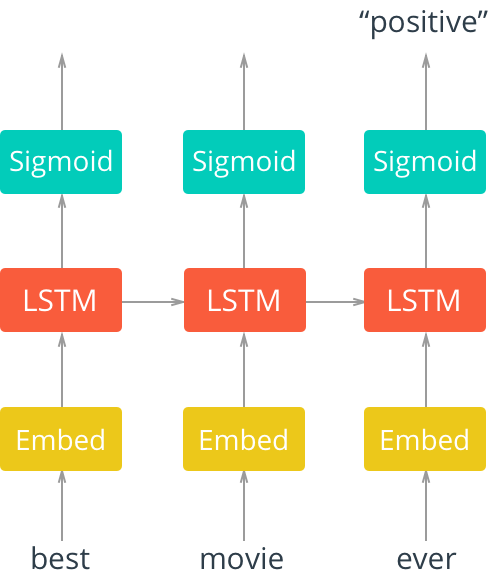
在图2中,我们看到一个“展开”的LSTM网络,里面有一个嵌入层、一个LSTM层和sigmoid激活函数。输入的是一个电影评论中的文字。
这些文字首先是被输入到嵌入层中,在大多数情况下,使用文本数据的语料库时,词汇库的规模都特别大。因此,在准确性和效率方面,使用单词嵌入通常是有利的。这是一个向量空间中多维分布的单词表示,这些嵌入可以使用其他深度学习技术(如word2vec)来学习,或者像我们在这里做的那样,我们可以用端到端的方式来训练模型,以便在训练时学习嵌入。
之后,这些嵌入被输入到LSTM层,其中输出则进入sigmoid输出层和LSTM单元,处理序列中的下一个字。在本例中,我们只关心整个序列评估后的模型输出,所以我们只考虑序列中最后一个字的sigmoid激活层的输出。
设置
你可以参考GitHub中给出的代码进行安装(地址:https://github.com/GarrettHoffman/lstm-oreilly)。
StockTwits信息数据库
这一项目的目标是利用LSTM网络分析网友在网站上的留言,进行文本情感分析。
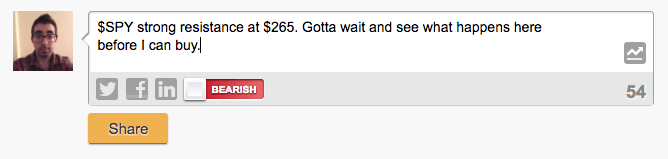
我们从StockTwits网站选取了所有带有“$SPY”(标准普尔500指数)标签的信息作为训练样本。StockTwits是美国一个关于股票买卖的社交论坛。当用户发布消息时,他们会标记相关的股票交易代码(本例中是标普500),如果他们认为股票会上涨,则会发表有关“看涨”的言论,看跌的情况也是如此。图3则是一个例子。
最终,研究人员收集了2017年的将近10万条带有“$SPY”的留言,试图对用户的留言进行分析。
建模数据处理
在建模之前,我们需要对数据进行一些处理。GitHub库中有一个utils模块,内含预处理和批量处理数据的代码。这些函数对教程中的数据提取非常有帮助。但请仔细阅读“util.py”,以更好地了解如何对数据进行预处理以供分析。
首先要对消息数据进行预处理,以便对StockTwits中的字符实体进行标准化,例如股票代码、用户名、链接或数字的引用。这里,我们也删除了标点符号。
接下来,我们将消息和情感数据进行编码。看跌信号为0,看涨为1。为了编码信息数据,我们首先要收集所有信息的全部单词,然后将每个单词映射到唯一的索引上,从1开始。
我们希望所有输入的数据大小相同,所以我们需要找到最大的序列长度然后填充数据。在这里,我们让所有信息序列达到最大(本例中是244个字)。“left pad”较短的信息为0。
最后,我们将数据集分成三部分:用于训练、用于验证以及测试模型。
网络输入
建立神经网络的第一件事就是定义网络输入。在这里,我们简单地定义一个函数,为消息序列、标签和一个名为“保持概率”(keep probability)的变量建立TensorFlow占位符。
def model_inputs():
"""
Create the model inputs
"""
inputs_ = tf.placeholder(tf.int32, [None, None], name='inputs')
labels_ = tf.placeholder(tf.int32, [None, None], name='labels')
keep_prob_ = tf.placeholder(tf.float32, name='keep_prob')
TensorFlow占位符只是数据的“pipes”,在训练时将输入到网络中。
嵌入层
接下来,我们定义一个函数来构建嵌入层。在TensorFlow中,“嵌入”这个词表示一个矩阵,每行是单词,每列是嵌入(见图4)。每个值都是在训练过程中学习的一个权重。
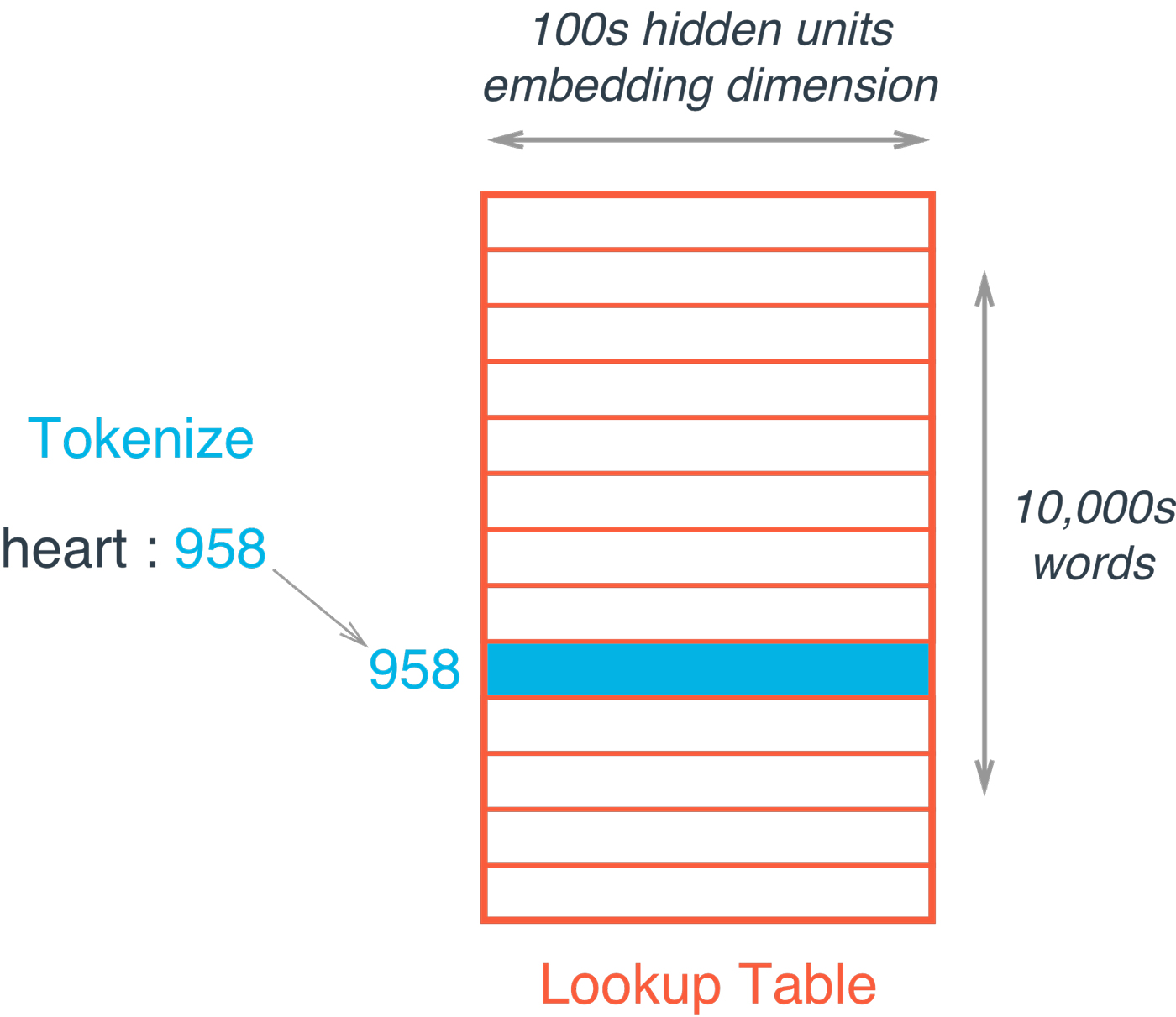
嵌入查找就是根据当前单词的索引从嵌入矩阵中简单查找。
def build_embedding_layer(inputs_, vocab_size, embed_size):
"""
Create the embedding layer
"""
embedding = tf.Variable(tf.random_uniform((vocab_size, embed_size), -1, 1))
embed = tf.nn.embedding_lookup(embedding, inputs_)
结果词嵌入向量是我们的分布式表示,即多维向量,将被传递给LSTM层的当前词。
LSTM层
我们将设置一个函数来构建LSTM层以动态处理层数和大小。该函数将对LSTM的大小列表排名,这也将根据列表长度决定LSTM图层的数量(例如,本例中将使用长度为2的列表,其中包含大小为128和64的两个图层)。
首先,我们使用TensorFlow contrib API的BasicLSTMCell构建我们的LSTM图层,并将每个图层包裹在一个dropout图层中。
请注意,我们在这里使用BasicLSTMCell仅用于说明目的。除此之外还有其他高性能的方式来定义网络,例如tf.contrib.cudnn_rnn.CudnnCompatibleLSTMCell,比现有方式快20倍,同时能减少3~4倍使用内存。
Dropout是深度学习中使用的正则化技术,在迭代学习期间,任何单个节点都有“退出”(drop out)网络的概率。在处理现实问题时,使用正则化技术是一个很好地做法,它让模型不依赖于任何给定的节点,从而让模型更加通用化,并且能适用于看不见的数据。
def build_lstm_layers(lstm_sizes, embed, keep_prob_, batch_size):
"""
Create the LSTM layers
"""
lstms = [tf.contrib.rnn.BasicLSTMCell(size) for size in lstm_sizes]
# Add dropout to the cell
drops = [tf.contrib.rnn.DropoutWrapper(lstm, output_keep_prob=keep_prob_) for lstm in lstms]
# Stack up multiple LSTM layers, for deep learning
cell = tf.contrib.rnn.MultiRNNCell(drops)
# Getting an initial state of all zeros
initial_state = cell.zero_state(batch_size, tf.float32)
lstm_outputs, final_state = tf.nn.dynamic_rnn(cell, embed, initial_state=initial_state)
接着,dropout列表将传递到TensorFlowMultiRNN单元,以将这些层堆叠在一起。最后,我们创建一个初始状态,并将堆叠的LSTM层、之前定义的嵌入层的输入以及创建网络时的初始状态应用于此。
损失函数、优化器和准确性
最后,我们要创建函数,来定义模型的损失函数、优化器和准确度。即使损失和准确性只是基于结果的计算,TensorFlow中的所有内容都是计算图谱的一部分。因此,我们需要在图谱的语境中定义三要素。
def build_cost_fn_and_opt(lstm_outputs, labels_, learning_rate):
"""
Create the Loss function and Optimizer
"""
predictions = tf.contrib.layers.fully_connected(lstm_outputs[:, -1], 1, activation_fn=tf.sigmoid)
loss = tf.losses.mean_squared_error(labels_, predictions)
optimzer = tf.train.AdadeltaOptimizer (learning_rate).minimize(loss)
def build_accuracy(predictions, labels_):
"""
Create accuracy
"""
correct_pred = tf.equal(tf.cast(tf.round(predictions), tf.int32), labels_)
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
首先,我们将LSTM的最终输出通过TensorFlow的完全连接层传递给sigmoid激活函数得到预测。注意,之前我们说过LSTM层输出的是序列中所有单词的结果。但是,我们只想用最终输入来进行预测。所以我们使用之前演示的[: , -1]来解决这一问题,并通过一个单独的完全连接层来传递这个索引,从而得到我们的预测结果。之后,这些预测被用于均方误差损失函数,并使用Adadelta优化器来减少损失。最后,定义准确性标准以评估我们的训练、验证和测试。
建立图表并训练
现在我们已经定义好了损失函数,现在还需再定义一个函数来创建计算图谱,并训练模型。首先,我们利用我们定义的每个函数来构建网络,并用TensorFlow会话训练模型。在每个训练阶段结束,我们都会计算损失、训练准确性和验证准确性,以监测训练结果。
def build_and_train_network(lstm_sizes, vocab_size, embed_size, epochs, batch_size,
learning_rate, keep_prob, train_x, val_x, train_y, val_y):
# Build Graph
with tf.Session() as sess:
# Train Network
# Save Network
然后,我们要定义模型的超参数。我们将建立一个两层的LSTM网络,其中有两个大小分别为128和64的隐藏层。我们将用300的嵌入训练大小为256的mini-batch。初始学习速率为0.1,Adadelta优化器会在训练过程中调整速率,同时保持0.5的概率。
输出显示,我们的LSTM网络开始学习的速度很快,第一次的准确度为58%,经过10次迭代后就升到66%。然后学习速率有所下降,经过50次迭代后,准确度为72%,最终达到75%的准确率。当模型训练完毕后,我们用TensorFlow储存器保存模型参数以备使用。
Epoch: 1/50... Batch: 303/303... Train Loss: 0.247... Train Accuracy: 0.562... Val Accuracy: 0.578
Epoch: 2/50... Batch: 303/303... Train Loss: 0.245... Train Accuracy: 0.583... Val Accuracy: 0.596
Epoch: 3/50... Batch: 303/303... Train Loss: 0.247... Train Accuracy: 0.597... Val Accuracy: 0.617
Epoch: 4/50... Batch: 303/303... Train Loss: 0.240... Train Accuracy: 0.610... Val Accuracy: 0.627
Epoch: 5/50... Batch: 303/303... Train Loss: 0.238... Train Accuracy: 0.620... Val Accuracy: 0.632
Epoch: 6/50... Batch: 303/303... Train Loss: 0.234... Train Accuracy: 0.632... Val Accuracy: 0.642
Epoch: 7/50... Batch: 303/303... Train Loss: 0.230... Train Accuracy: 0.636... Val Accuracy: 0.648
Epoch: 8/50... Batch: 303/303... Train Loss: 0.227... Train Accuracy: 0.641... Val Accuracy: 0.653
Epoch: 9/50... Batch: 303/303... Train Loss: 0.223... Train Accuracy: 0.646... Val Accuracy: 0.656
Epoch: 10/50... Batch: 303/303... Train Loss: 0.221... Train Accuracy: 0.652... Val Accuracy: 0.659
测试
最后,我们在测试机上检查模型结果,确保符合我们的期望。
def test_network(model_dir, batch_size, test_x, test_y):
# Build Network
with tf.Session() as sess:
# Restore Model
# Test Model
我们创建了计算图谱,但是并没有进行训练,而是从检查点目录恢复之前保存的模型,然后通过模型运行测试数据。测试的准确度是72%,这与之前验证的准确度一直,并且表明被分成三部分的数据是均匀的。
INFO:tensorflow:Restoring parameters from checkpoints/sentiment.ckpt
Test Accuracy: 0.717
结论
总之,LSTM网络是RNN的延伸,旨在处理长期学习的问题。LSTM在处理序列数据时用途广泛,经常用于NLP任务。研究人员已经通过训练一个多层LSTM网络、利用词嵌入分析社交网络上对股票市场的信息文本。
他们认为,这只是一个开始,希望今后继续努力提高模型的新能。以后可以更长时间的训练模型,建立一个更隐蔽的单元和更多LSTM层的网络,并调整超参数。
原文地址:www.oreilly.com/ideas/introduction-to-lstms-with-tensorflow






