你必须知道的六个深度炼丹好习惯
来源 | 极市平台
问:为什么训练不出一个好的模型?
答:从一开始就没有遵循科学的炼丹方法,可能哪个地方出了错你还没意识到。
写在前面:培养良好的工程习惯至关重要,前期可能需要一些学习成本,但到后期你会发现养成了好习惯反而能省很多时间,尤其是当任务量比较大或者是需要开展持续的工作的时候,你会发现之前的付出真的很有意义。
举个简单的例子,你如果研究目标检测,这是当前很热的领域哇,很多人都在做。要想突破可能需要更多的实验去尝试,在实验过程会用到COCO和Pascal VOC数据集,评价标准也相对复杂;同时目标检测的代码量又相对较大,为了提高运行效率部分代码甚至会用C++实现。拿到这么冗杂的一套系统,无论是用来做研究还是做工程,都需要一套科学严谨的准则,否则到最后发现会乱成一锅粥,不知道对错。
本文就是作者总结的一些在深度学习领域一些好的规则和习惯,都是自己的踩坑心路历程。记住,播种一个行为,收获一种习惯,日积月累,必有回响。
一、在开展工作之前先熟悉常用的工具指令
在实际开发过程中,往往是通过远程操作服务器,掌握基本的linux指令非常关键,前期如果没有这些基础后期再做一些复杂的研究或者工程会十分恼火。因为你要去改代码,研究数据,做很多对比试验。如果不能掌握基本的操作指令可能最后心乱如麻。不要期待使用图形界面化操作,首先我们通常用远程ssh连接服务器跑程序,接触到的只有黑黢黢的终端;还有图形界面化其实不方便处理复杂的批操作,还不如指令用起方便;再者就是去Github拉代码你会发现很多repo中都会让你运行一些Linux指令,不会肯定是不行的。
有人可能会说,pycharm可以远程操作呀,还自带Sftp,这里提一下,如果是在资源充足的条件下可以使用pycharm远程调试,但是在资源受限制的情况下不太稳定,正式训练调参不推荐使用pycharm。(预告:如果下周有空我会出一个pycharm详细教程,它可是非常NB的生产力工具)。总之,学会Linux指令可以提高开发效率,很有必要。前期不要着急去跑代码,花点时间研究一下基本的指令和IDE工具是很有帮助的。下面列举一些常用的指令:
文件操作
mv, cp, ln, rm, ls, mkdir, make, mount, nohup, >, tailf, cat, find,ifconfig, chmod, cat
远程控制
ssh, scp(远程文件传输)
系统资源查看管理
ps, top, free, nvidia-smi, df, fdisk, watch, kill
简单的正则
grep
实用工具
screen或tmux(多终端后台运行), vim(可当做IDE), wget(支持断点下载), conda, pip, apt-get, git
要尤其重视conda的使用,用来管理多个环境;使用Git管理你的代码版本
二、学会去查找资料和Solution
如果你有了初步的想法打算做某个研究或项目,该从何开始呢?
第一层境界:放心大胆的使用百度或Google吧,看看有没有前人做过类似的工作;其次去知乎,CSDN,简书上搜搜看,可能会有文章带给我们启发;如果是找一些学习资料或视频直接B站或者YouTube搜索;还有就是关注一些DL技术公众号等等。
第二层境界:等有一些基本的概念和了解之后就要去查阅相关领域的论文,去Google学术、百度学术或arxiv检索相关的文献,看论文是非常有必要和有用的,因为Paper也算是可信度高内容丰富的技术文档。
进阶:去github搜索相关论文的代码,论文和代码搭配使用效果更佳;大佬们的Github.io隐藏着很多干货;Kaggle或天池上面很多优秀的Kernel或许能够提供新的思路;一些大佬自己的网站上面也会有很多干货,说不定就能淘到我们想要的东西
遇到问题怎么办?
首先当然是百度和google,github的issue,StackOverflow都是查找解决方案的好地方;如果身边有大牛的话也要虚心请教;一些技术交流QQ或微信群也是我们获取答案的好地方。比如我加了Pytorch交流群,里面很活跃,大佬们也不吝赐教,群里可能有人发一些最新资料,这对新手来讲是很好学习途径。多水一水群既可以开阔视野,同时又可以摸鱼闲聊。
三、良好的工程化习惯
在训练之前要合理规划文件夹的命名以及层级结构,使用简洁的英文单词命名文件(这里可以推荐一下我的另一篇文章——CV领域常用单词)。不要以为这是一个小事情,前期没有一个好的组织结构,没有规范的管理方式,等后期代码文件多了再想起重构是一件非常麻烦的事情。大家可以看一下Mask-RCNN仓库链接 的组织结构,虽然项目工程很大,但整体结构井井有条。这和初高中时成绩好的同学作业本写得工整,成绩差的同学写得潦草一个道理。(我也是看到大佬们的工作才认识到自身的不足,多看牛人的代码真的是一种洗礼)
你的工程中应该包含如下模块:
训练Loss日志:建议使用Tensorboard,因为现在tf和pytorch都支持这个工具,用起来也很简单,因此强烈推荐使用,我看到之前一些人的代码中可能写了log的方法,但现在官方提供了更强大的工具建议就不要用自己造的轮子了。注意,日志文件夹命名最好要有区别,建议使用时间戳命名,否则所有的日志混杂在一起将会乱成一锅粥。
模型存储:用一个文件夹来专门存放训练的模型,每个模型的命名建议花点心思,最好要包含有用的信息,方便查找使用
参数配置文件config:将训练网络的超参数和配置文件参数都放在专门的文件中统一管理,不要在训练主程序中东一坨西一坨,改来改去到最后很容易出现疏忽
数据集文件夹:此处建议所有的数据使用软连接的方式连接到工程文件夹,对原始数据加一些权限防止误删或更改;工程中的数据路径建议使用相对路径而非绝对路径!!绝对路径会导致你的工程文件夹换个地方就报错
函数工具包:把自己自定义的类和方法统一放到一个地方,增加模块的复用性。
训练和推断的程序:现在流行的做法就是把网络封装成一个训练器,在指定文件中配置好路径参数,直接运行程序就开始训练了,模型设计好了就专心训练和调参,可以看到keras训练和Detecron中都是这种设计模式,把数据灌进去就OK了。如果自己重新开始搭工程可以借鉴一下这种思路。
网络模型结构:当网络比较复杂的话,专门建一个包来存放网络结构
训练快照:也就是你当前训练出来模型对应的参数配置,个人觉得这点挺实用,防止最后训练了半天不知道用的啥参数啥数据集。
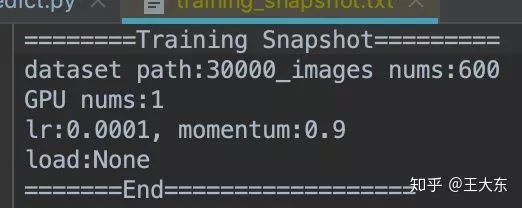
总之:清爽的工程使人愉悦,杂乱的工程使人爆炸
四、开发过程中的好习惯
我们开展一个任务,上手的第一个环节可能是clone别人的代码然后准备复现,Wait.第一步不要猴急猴急地去run人家的代码,我建议走下面的流程:
上手工程
1.理清任务和评价标准,对算法精度有一个宏观的理解,也就是知道人家差不多能做到啥程度
2.先去看一下训练的数据,如果是图片的话先用肉眼随机抽样看一看,人类是一种非常高级和敏感的动物,说不定就会有意想不到的发现;看完了之后如果有代码基础就做一下数据统计分布,数据探索分析。
3.看一下原作者写的Readme文件,里面会概述本工程的一些组织结构和使用方法,这是很重要的一个环节。根据作者的提示可以去Run程序,训练推断都玩一玩,这样很容易让自己有成就感。
4.代码跑起来了不代表这个工程就是对的,一定要仔细地检查原作者的代码细节和实现思路,防止代码有坑,这点很关键(不要认为人家是大佬还发过论文,放出来的代码就没毛病了!)。我个人喜欢边看边注释原代码核心算法,如果搞清楚了可以先给身边的同事讲一讲,讲懂了说明自己也会了。彻底核实清楚之后才能把这份Solution作为自己的Baseline,不要等到效果迟迟不见提升回过头来才发现,哦,原来这个代码有问题啊(也不一定是人家代码有误,很可能是自己没搞懂就用和自己的任务冲突),悔恨当时怎么没注意呢>_<。
懂你用的深度学习框架
为什么把这个看似无关紧要的部分提上议程呢,我们可是在搞学术哎喂ヾ(=・ω・=)o
嘻嘻,其实这一块用得熟不熟练直接影响最终训练出来的时间复杂度和精度。这不是开玩笑哦,公开数据集上精度提升一个点速度提升一丢丢可能就要出一篇文章了。稍微了解一下框架的原理和实现,不论是对写代码还是理解DL基础知识都是很有帮助的。举个例子,你知道BN是咋实现的?反向传播是怎么搞的?看一下框架中的代码实现会帮助我们理解其中的原理,在调用函数的时候也不会犯错。
现在DL框架基本上分两大阵营(Mxnet和PP用户勿喷)——Pytorch和TF。建议看官方Document和Tutorial,这是极好的入坑指南,有精力的同学可以看一下源码的实现代码,太底层C实现的东西不建议新手玩家体验,还是先攻关主要矛盾(逃),如果修炼到一定境界还是要广泛涉猎一些的。
算法改进优化
前期可以在baseline上做一些改动,然后看一下效果如何,分析问题出在哪里。譬如来一个连环问,是哪些类分不好?为什么分不好?是因为这个类特征难学吗?加一些什么模块或者机制能够更好的学特征?
然后多去看一些论文,汲取其中的精华,然后回来接着做实验,这是一种问题驱动型的思路。总之要养成多看论文的习惯,不论做检测、分割还是跟踪重识别,一些经典的DL论文是一定要看的,经典论文中有很多普适性的insight,多看论文才能拓宽思路有所启发。
确定好了思路开始跑实验验证,记住首先要小样本(少量的数据)测试自己的算法是否work,看一下有没有初步的效果。切忌一股脑成千上万开始训练,训了半天发现那个地方有疏忽又从头开始训练。
调参也是很重要的过程。深度学习训练说白了是一个数学优化过程,不要忽视了超参数对最终效果的影响,至于如何调参网上文章很多,比如过拟合怎么办,学习率怎么调,梯度爆炸咋处理?看再多理论没有亲身经历过永远是外行,我建议还是要亲自动手训练感受才深刻。结合数学理论宏观地分析原因,举个例子,mini-batch中的样本不平衡会如何影响优化方向?梯度爆炸的数学原因从何而来?如果Loss非凸会对优化带来什么影响?two-stage模型像不像是个条件概率?这样对自己的整体能力提升很有帮助。我个人认为,深度学习底层虽然不可知,但是从宏观上来讲还是服从统计学、优化理论的一些规则,善于从数学角度去分析模型很重要。
良好的代码风格以及版本控制
看大佬的代码你会发现人家不光是学术搞得好,代码敲得也贼666啊。多去看看名家的代码对自己是很有裨益的,甚至没事的时候可以跟着敲一敲练手。那么总结一下大佬的代码会发现人家的代码风格基本上遵循Google代码规范,而且有命名优雅、注释详细、函数之间耦合性低、逻辑清晰等优点。这些东西一时半会培养不来,但是平时注意培养代码风格习惯,日积月累肯定会有提高的。
说到版本控制,我本人在这一块做的比较差,到后期会发现不注意版本控制是风险系数很高的。常用的版本控制有Git,我本人用了可视化界面的SourceTree,有Mac和Win版本,推荐给大家使用。担心自己辛辛苦苦做的工作丢失,不妨在本地搭建一个gitlab仓库或者使用github private托管。
五、总结失误做好笔记
不要在同一个坑里面摔倒三次(允许多摔一次)!!遇到问题及时解决和并记录,不做重复性工作。这是我多次失败的一个教训,我之前也没有做笔记的习惯,但其实人脑很容易遗忘,做笔记是一件很有必要的事情。
推荐一个适合程序员做笔记的工具Leanote,如果使用官方提供的服务器需要每月交五块钱。如果不想花钱可以将Leanote开源的的代码部署到本地服务器上
使用Wiki系统进行知识库管理。每天做完工作都要有一定的收获。我使用的是confluence,每天坚持写一写,对自己既是督促也是提升。

六、培养耐心和细心
The last but not least, 深度学习本来就是一个玄学,暂时还没人揭开底层的奥秘。因此我们常称之为“炼丹”。既然是炼丹就要做好持久战的准备,多一些耐心多去尝试,失败再所难免。我记得有位大佬说过,“深度学习比得就是耐心”,越着急反而越做不好,多看论文多探究底层原理,每次失败之后做好记录并分析,不会了去问问群里的小伙伴,相信总有一天会有好的算法诞生。^_^
☞ OpenPV平台发布在线的ParallelEye视觉任务挑战赛
☞【学界】OpenPV:中科院研究人员建立开源的平行视觉研究平台
☞【学界】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集
☞【CFP】Virtual Images for Visual Artificial Intelligence
☞【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞【学界】Ian Goodfellow等人提出对抗重编程,让神经网络执行其他任务
☞【学界】六种GAN评估指标的综合评估实验,迈向定量评估GAN的重要一步
☞【资源】T2T:利用StackGAN和ProGAN从文本生成人脸
☞【学界】 CVPR 2018最佳论文作者亲笔解读:研究视觉任务关联性的Taskonomy
☞【业界】英特尔OpenVINO™工具包为创新智能视觉提供更多可能
☞【学界】ECCV 2018: 对抗深度学习: 鱼 (模型准确性) 与熊掌 (模型鲁棒性) 能否兼得




