近13年无任何实际进展?Cornell&Facebook研究员剑指Deep Metric Learning领域
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
编辑|极市平台
Facebook AI 和 Cornell Tech 的研究人员近期发表研究论文预览文稿,声称近十三年 (deep) metric learning 领域的研究进展(ArcFace, SoftTriple, CosFace 等十种算法) 和十三年前的基线方法(Contrastive, Triplet) 比较并无实质提高,近期发表论文中的性能提高主要来自于不公平的实验比较,泄露测试集标签,以及不合理的评价指标。
论文链接:https://arxiv.org/pdf/2003.08505.pdf

摘要:Deep metric learning papers from the past four years have consistently claimed great advances in accuracy, often more than doubling the performance of decade-old methods. In this paper, we take a closer look at the field to see if this is actually true. We find flaws in the experimental setup of these papers, and propose a new way to evaluate metric learning algorithms. Finally, we present experimental results that show that the improvements over time have been marginal at best.
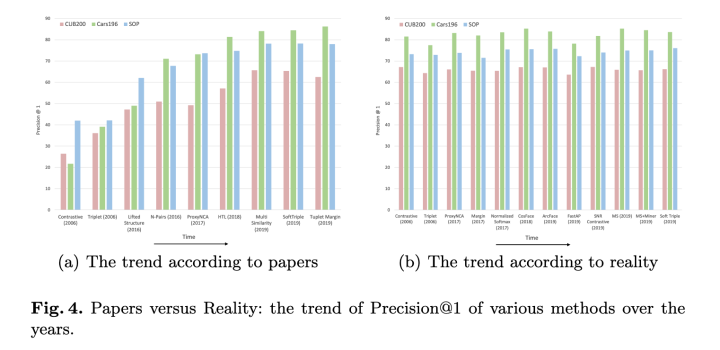
那么如何看待deep metric learning 领域的进展实际并不存在这一观点?本文对几位知乎大牛的观点进行了整合:
Deep Learning话题的优秀回答者 https://www.zhihu.com/question/394204248/answer/1217238695 本文来自知乎问答,回答已获作者授权,著作权归作者所有,禁止二次转载。
这个其实一点都不意外。
出去做报告的时候,经常有人问:这个loss在人脸上涨了这么多,那在其他的metric learning任务甚至是classification任务上有没有效果呢?一般我的回答是:值得尝试,但可能需要调调参数。
然而我没说的话是:我何尝不想让我做出来的loss可以应用在其他metric learning任务上呢?就算是为了增加引用,或者单纯为了凑页数,我做几个实验也不亏是吧?
但确实是不work,目前我试过的几个task,除了vehicle reid,其他都没有比baseline更好,其实vehicle reid上也只是高1-2个点而已,也不是很明显,是trick级别的提升。
我自己对这个现象也非常困惑,但论文还是得发是吧,于是就只报了人脸上的结果,然后在conclusion里说一句值得在其他任务上推广。
至于为何其他metric learning问题上没有比baseline更work?这个答案我也想知道,人脸到底具备什么特殊性,使得这些收缩类内距离的loss能取得很好的效果,而其他的person、bird就不具备呢?这其实是个值得研究的问题。
罗列一下可能的原因:
1. 数据量,尤其是id数量。这里其实有一个明显的分水岭:就是id数与embedded feature的维度,如果id数小于特征维度,那完全可以每个id各自占据一个或多个维度的subspace,那不需要收紧类内特征也可以work。
2. 外观特征。人脸首先是个刚体,其次人脸识别的角度最多也就到90°左右,更大角度的人脸识别其实没什么意义。而且人脸有一个关键步骤是对齐,在对齐之后,可以认为所有人脸呈现的appearance都是类似的,我们要找的区别主要在于内部细节上的区别,而不是整体外形的区别。
3. 数据噪声。人脸数据集里是有很多噪声的(包括当前模型无法建模的正确样本也可以算噪声),而margin的意义在于”牺牲一些本来可能可以分对的难样本,使得简单样本能够收缩得更紧“,而人脸里可能牺牲的难样本可能恰好是噪声?
4. 类内类间分布。之前我发现loss里的margin在设置为当前模型统计出的margin值时,效果最佳,可能人脸天然就具备比较大的统计margin?详情请见https://zhuanlan.zhihu.com/p/62229855 。
有了假设,就可以设计实验来验证了,比如可以挑选较少的id增加特征维度来验证id数量的影响,可以不对人脸进行对齐来验证对齐的影响。感觉又能rethink出好几篇paper呀!
美团算法工程师 https://www.zhihu.com/question/394204248/answer/1219519263 本文来自知乎问答,回答已获作者授权,禁止二次转载。
任务不同差距很大。
person上work的,在其他metric learning上效果也不见得好。
我个人倾向于把目前的数据集分为两类:
face,vehicle,person是一类。
product,bird,clothing,flower,dog等等是另一类。
两者的区别在哪,前者存在一定意义上的对齐,比如人脸可以做关键点对齐,vehicle和person也有一定意义上的对齐,虽然没法做到face那么完美,但是类似于强行切part之类的方法,对于vehicle和person是有效果的。而后者,很难定义出什么是对齐,所以还要去捕捉所谓的细粒度信息。
对于网络而言,在face上,几乎只要完全关注特征提取就行了。在vehicle和person上,能做到一定的局部显著性寻找然后抽特征。对于其他类别,那基本得是在全图做区域寻找重要区域再提取特征。显然,先验不同,难度不同,效果自然不同,各个领域内的方法也不同。一如人脸关注loss,person和vehicle关注part和attention,其他则什么大杂烩方法都有。
本质上,还是根据数据集,给出直觉上最适合的先验,先验越少,自然方法能work的可能性越小。当然,数据集数量不够,导致泛化力较差,其实也是个客观存在的问题。
计算机视觉算法工程师 https://www.zhihu.com/question/394204248/answer/1219001568 本文来自知乎问答,仅用于学术分享,著作权归作者所有
MS Loss一作(CVPR-2019),不匿,前来狡辩。
reality check文章刚放arxiv的时候,我就给几个好朋友推荐,说是Deep metric learning的一股清流,并且https://github.com/bnu-wangxun/Deep_Metric的repo开头强烈推荐这个文章,希望能让做这个领域的人看到,引导新入这个坑的人向着正确的方向走。因为,我也曾是踩过这些坑过来的。
本人两年前为了做硕士毕设,单枪匹马入坑deep metric learning,然后在这个坑里摸爬了两年。其实这个文章里说的坑我也踩过大部分,我心里也是知道这个领域的大部分方法(包括我自己的MS Loss)提升没有文章里宣称的那么大,至于这些方法的“进步”到底来自哪里,直接说其实是以下三部分:
1. 调参技术或者说tricks (比如freeze bn,lr_mul等),但是这个其实只在CUB Cars196这两个特别小的数据集有用,在SOP, InShop 其实完全没有意义,我在开源的代码里写了这个点。
2. 方法本身的提高,即便是在这个check reality 论文列出的复现结果表格里,可以看到MS Loss确实是当时的SOTA。而且,我在ablation study并没有刻意压低结果,使用的都是自己复现的结果(都是一致的试验设置),提升也没有夸大,对比对象的代码我也基本开源。
3. 关键点是:Batch size, 这一点,我没有写在MS论文的正文里,只写在附录里了。其实batch size是方法提升的核心,越大的mini-batch size可以大幅提升大规模检索数据的结果。其他有些基于pair weighting 或者 sampling 文章,你稍微读读试验设置,也是如此,他说了一堆故事,最后做实验,为了在sop 和 inshop的效果,用的batch size很大。
该领域确实水文比例挺大的,有些文章为了中,确实会用特别低的baseline, 用resnet甚至densenet和别人googlenet的结果去比,或者用2048维特征去比过去方法的128维的结果。我也没有做这种比较出格的事情,我用的是bninception是当时最常用的backbone. 并且,我也在正文表明了维度的影响。基本可以做到当时的同样网络,同样维度的SOTA. 不过相当惭愧的是,为了outperform SOTA并中论文, 我主要依靠的并不是MS Loss的改进,而是依靠使用大batch size的训练方式,虽然我在附录列出了不同的batch size的效果。
那这时候,我要讲讲我的paper, 其实那个ms loss 我认为并不是我的那个文章最有意义的点,我觉得最有意义的点,是我在这个文章的一个小段里的GPW,用梯度求导,讲了一个很简单的统一角度:pair weighting,其实这个领域大家做了(或者水了)这么多loss, 当时我也云里雾里,我就想,既然CNN 是基于SGD优化,是梯度反传,那么要知道不同的loss到底做了什么,看文章里"编"的motivation是没有意义的,(基本都是focus on hard negatives, 拉近同类,推远异类那一套),不如简简单单回归本质,就看看梯度,我发现,通过梯度一看,其实所有的loss 都可以变成非常统一的pairs的加权求和。详细推导过程可见我的论文:
https://arxiv.org/pdf/1904.06627.pdf
这个视角本身没有任何效果上的增益,推导上,也没有什么难度,没有什么花哨的技巧,就是简单地一阶导等价。不过提供了一个清晰统一的视角,是一把刀,可以拨开各种各样的loss的内在给你去看,给你拨开云雾,在SimCLR对loss进行分析的时候,用表格表达了类似的事情。
其实,metric learning 是机器学习一个很核心的基础问题,它的另一种说法,叫做embedding learning, embedding是啥,不严格的说,不就是representation吗. 也就是大佬们(Kaiming等, Hinton组等)最近又在搞的东西。MoCo,SimCLR是这个方向最近两个比较受关注的论文,不过人家机器多,做的是ImageNet dataset 上的 self-learning。从这两个论文,可以发现一个非常重要的点,就是mini-batch size大,真的效果好。SimCLR是直接上128 核TPU,Kaiming是设计了MoCo,其实这种思路也是可以沿用到deep metric learning(或者说 supervised representation learning)这个领域的。好的,插播一个广告:我们CPVR 2020在这个没有什么进展的领域发表了一篇Oral 论文, 做的就是和MoCo类似的思路,利用过去的iteration, 无痛的达到增大batch size的效果提升,论文:
https://arxiv.org/pdf/1912.06798.pdf
如果你不喜欢读论文,我也恰好为你准备了一个通俗解读文:CVPR2020 Oral|为度量学习插上翅膀,跨越时空的难样本挖掘
欢迎大家指导,另外,我这个方法,reality check一作也觉得很好,并且又复现了,他的夸奖在这里:
https://github.com/bnu-wangxun/Deep_Metric/issues/43#issuecomment-589537708
其实每个领域都有水文,绝不限于deep metric learning,没必要嘲笑。历史滚滚,百分之九十的顶会论文并不会激起波澜,终成废纸,很多时候,文章存在的意义也许是为了毕业,也许是为了工作,但并不是学术进步。因此,也没有必要对顶会论文有着统一的过高期望,顶会论文和顶会论文的差距也是很大的。想想Resnet, 一文胜千文。不过这样的打脸文确实比水文有意义的多,可以促进领域更加健康的发展,即便我的ms loss也是打脸对象之一。我也希望自己做论文,尽量做到诚实公正。做的工作虽浅薄,也希望可以给读者带来一些有益的启发,最起码不把读者带到沟里,无愧于本心。
我看评论里有人说做大的人脸数据集,说人脸才是真的metric learning,我没做过人脸,但是在公司内部也做过量级相当的图像检索项目。我的理解是机器学习方法的有效性是和数据分布相关的,人脸数据集,应该不能代表所有的数据分布情况。即便是不那么大的数据(车辆数据集也有20w的数据,或者imagenet也行),有好的方法,有趣的观点,也是可以的。
公众号王晋东不在家(ID:yourwjd),中国科学院大学计算机应用技术博士 https://www.zhihu.com/question/394204248/answer/1219383067 本文来自知乎问答,回答已获作者授权,禁止二次转载 的回答 - 知乎
其实大可不必心潮澎湃、攻击别人、对该领域前途失望。首先声明:本回答不存在任何洗地、拉偏架、或刻意抹黑的意思,只是在心平气和地探讨问题。
我的理解是,每当一个研究领域出现一些rethinking、revisiting、comprehensive analysis等类型的文章时,往往都说明了几个现象:
这个领域发展的还可以,出现了很多相关的工作可以参考;
这个领域的文章同质化太严重,到了传说中的“瓶颈期”;
研究人员思考为什么已经有这么多好工作,却好像觉得还差点意思,还“不够用”、“不好用”、“没法用”。
其实这对于研究而言是个好事。“Research”的这个"Re",说的就是这个意思啦。
我们在一条路上走了太久,却常常忘记了为什么出发。此时需要有些人(常常是大佬,普通人不敢,哈哈)敢于“冒天下之大不韪”,出来给大家头上浇盆冷水,重新思考一下这个领域出现了什么问题。哲学上也有“否定之否定”规律嘛。
回到metric learning的问题上来。我们吃瓜群众往往只看结果:哇,原来metric learning并不work-->metric没用,垃圾,灌水,骗人!
其实想想看,机器学习的核心问题之一便是距离。Metric learning这种可以自适应地学习度量的思想,真的是没用吗?还是说它只是被目前的方法、实验手段、评测数据集等等束缚了手脚,阴差阳错地导致了不好的结果?这也是这个问题的提出者原文作者质疑的问题。
因此,事情已经发生了,这时候最需要的是沉下心来思考为什么、怎么办,而不是上来就酸,上来就惶恐,上来就叫嚣顶会灌水、垃圾。
不能经受得住质疑和时间的洗礼的工作,不是好工作。事实上此类事情并不是第一次发生。人家meta-learning表示:小样,你这才到哪啊,根本不叫事儿!
不信你看,作为当下ICML、ICLR、NIPS等顶会的“宠儿”,meta-learning可谓风头一时无两。然而,大家都清楚,meta-learning的一大部分工作都是在few-shot的任务上进行算法开发和评测的。从18年开始到今年的ICLR,就已经不断地有人“质疑”其有效性了:
ICLR 2020: A Baseline for Few-Shot Image Classification
ICLR 2020: Rapid Learning or Feature Reuse? Towards Understanding the Effectiveness of MAML
arXiv 2020: Rethinking Few-Shot Image Classification: a Good Embedding Is All You Need?
arXiv 2020: A New Meta-Baseline for Few-Shot Learning
arXiv 1911: All you need is a good representation: A multi-level and classifier-centric representation for few-shot learning
……
上述“质疑”的核心问题之一是:用简单的pretrain network去学习feature embedding,然后再加上简单的分类器就可以在few-shot那几个通用任务上,打败很多“著名”的meta-learning方法。
所以到底是meta-learning的这种“学会学习”的思想没用,还是它只是被不恰当地使用了?或者说,meta-learning的正确用法是什么?我认为这也是要思考的。我个人是非常喜欢meta的思想的。
其实在transfer learning领域。我之前也有一篇看似“打脸”的paper:Easy Transfer Learning by Exploiting Intra-domain Structures。我们的实验同样证明了仅需简单pretrain过的ResNet50提取源域和目标域的feature embedding,然后加上简单的线性规划分类器,甚至是nearest centroid,就能取得当时(2018年底)几乎最好的分类结果。但是你能说transfer learning没用吗?显然这并不能掩盖transfer learning方法的光芒。所以我一直都在质疑自己:肯定是这些数据集不完善、精度不能作为唯一指标、其他方法需要再调参数,等等。
我觉得这可能是个实验科学的误区:我们实验设定本来就需要完善,并不能因此否定一类方法的有效性。深度学习大部分都是建立在实验科学的基础上,因此实验很关键。
有了广泛的质疑,才会有更广泛的讨论,于是会有更广泛的反质疑、新范式、新思想。从整个领域的发展来看,这无疑是好事。
所以这应该是“沧海横流,方显英雄本色”的时候了。加油吧!
关于「研究人员声称近13年来在 deep metric learning 领域的进展实际并不存在?」这一问题,你怎么看?欢迎在下方留言区抒发你的见解~
*延伸阅读

添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:AI移动应用-小极-北大-深圳),即可申请加入AI移动应用极市技术交流群,更有每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~



