【开源】基于Keras的知识图谱处理实战
【导读】近日,Daniel Shapiro博士利用开源的图结构卷积网络进行知识图谱处理,并应用于交易数据的欺诈检测,其知识图谱处理相关源码也开源出来,并且Daniel Shapiro博士写了一个基于Keras的知识图谱处理实战的博客,内容浅显易懂,是一篇想了解知识图谱实战的好文,让我们来看下。
想了解知识图谱相关概念和内容,请阅读专知以前推出的报道:
kegra: Deep Learning on Knowledge Graphswith Keras
基于Keras的知识图谱深度学习
作者:Daniel Shapiro
译者:专知内容组
▌引言
大家好。我在过去的文章中提到过,我正在基于企业数据集做感知计算。本文就是基于这个工作来写的。学习这篇文章要求您对深度学习有一定的了解,但是如果您对数据科学稍微有些了解应该可以跟上本文的节奏。
我一直致力于在图结构上研究深度学习的检测模型。Thomas Kipf 写了一个用Keras实现的关于图节点分类的比较好的库。本文是基于他的作品“用图卷积网络进行半监督分类”(Semi-SupervisedClassification with Graph ConvolutionalNetworks)。
下面让我们来看一下。
▌详细内容
首先,什么是图(知识图谱)?
我们在工作中按照如下考虑知识图谱,这些知识图谱以“白宫”和“唐纳德·特朗普”这样的实体作为节点,像“工作”这样的关系是图中的边。我们如何构建这些图表是另一回事。在本文中,我正在研究交易数据以训练分类器来识别诈骗交易。如果你更喜欢顶点和圆弧而不是节点和边,那么阅读这篇文章
(https://math.stackexchange.com/questions/31207/graph-terminology-vertex-node-edge-arc)。
我对图结构数据的处理非常感兴趣,我关于图的研究工作可以追溯到我的硕士论文。在那项工作中,我想要在有向无环图中找到共同元素(凸子图)。我正在确定如何将定制指令添加到软件的处理程序中,让它能过运行起来。我用整数线性规划来解决这个问题。在大图上,求解器可能需要数小时甚至数天运行时间。
研究的相关链接:
A Case Study on Hardware/Software Codesign in Embedded Artificial Neural Networks
(一个硬件/软件协同设计的嵌入式人工神经网络的案例研究)
Tunable Instruction Set Extension Identification
(可调指令集扩展识别)
ASIPs for artificial neural networks
(用于人工神经网络的ASIP)
Artificial neural network acceleration on FPGA using custom instruction
(基于定制指令的FPGA人工神经网络加速)
Improved ISE Identification Under Hardware Constraint
(硬件约束下改进的ISE识别)
Parallel instruction set extension identification
(并行指令集扩展识别)
Static task scheduling for configurable multiprocessors
(针对可配置多处理器的静态任务调度)
Design and implementation of instruction set extension identification for a multiprocessor system-on-chip hardware/software co-design toolchain
(多处理器片上系统硬件/软件协同设计工具链的指令集扩展识别的设计和实现)
SING: A multiprocessor system-on-chip design and system generation tool
(SING:多处理器系统芯片设计和系统生成工具)
以下是OrientDB中知识图谱拓扑结构的一个例子:
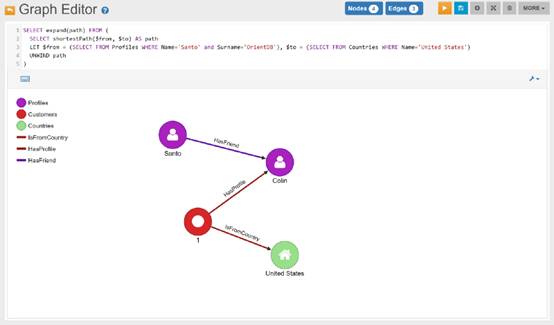
第二,我们能发现什么模式?
我们要标记节点。图中的每个实体都有一些我们想要的分类特征,而且我们只有一些节点的标签。有我们可以预测的简单的布尔标签,如“是人”或“不是人”,或更复杂的标签,如节点被分成几个类别之一。然后我们可以做更复杂的回归,比如根据图表的实体数据来预测实体所带来的风险。这包括一个节点到其他节点的连接。让我们用本文中的布尔标签研究分类问题,以保持简单。我们想要用大约4,000个银行账户标记594,643笔交易,确定要么是可疑的,要么是不可疑。我们希望在很快的一分钟之内完成该任务,而不是几小时或几天。
第三,我们如何定义一个kegra能够理解的图?
我们需要指定两个文件。第一个有节点的描述,第二个说明节点如何连接。在kegra提供的cora例子中,有2,708个节点的描述和标签,有5,429个边(节点对)定义了节点之间的连接。
下图是每个文件的几行:
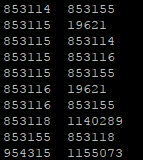
节点之间的连接

每个节点ID后面跟着特征(大部分是0),最后还有一个节点标签(例如Neural_Networks,Case_Based)。上面的截图中的功能大部分都是0。每个特征代表在某个单词在文档(节点)中的使用。更多信息在这里kegra描述
(https://github.com/tkipf/keras-gcn/blob/master/kegra/data/cora/README)。
▌让我们试试看
首先,你需要keras2,所以请输入下面命令:

假设你已经安装了Keras和TensorFlow,keras-gcn依赖于gcn,所以让我们复制并逐个安装它们。
首先让我们运行kegra所提供现成示例代码。我们在输出中看到cora已经从原始数据中检测并打印了节点和边的期望数量。
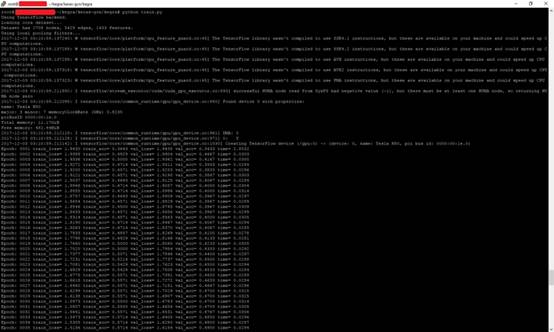
在cora数据集上训练:36%的准确性和持续上升。

对cora数据集的测试结果是:77.6%的精度。
我们现在对kegra对输入文件的理解方式做一些小的改动,改动只是为了让名字更好。在github的当前版本中,输入文件“*.cites”是描述节点之间的弧,描述节点的是“* .content”。相反,我改变了kegra阅读“* .link”和“* .node”文件。你的数据文件夹现在应该是这样的:

现在让我们用交易数据填写customerTx.node和customerTx.link。第一个文件是银行客户及其功能的列表,格式是:
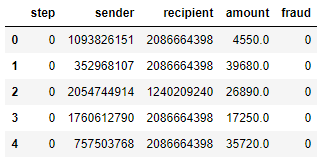
交易记录的快捷视图。图中有货币的发送者和接收者,发送金额的记录(金额栏),以及由审查交易人的分析员(欺诈栏)应用的标签。我们可以忽略前两列(索引和步骤列)。
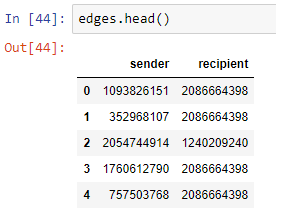
边文件(customerTx.link)记录双方在每次交易中的身份。
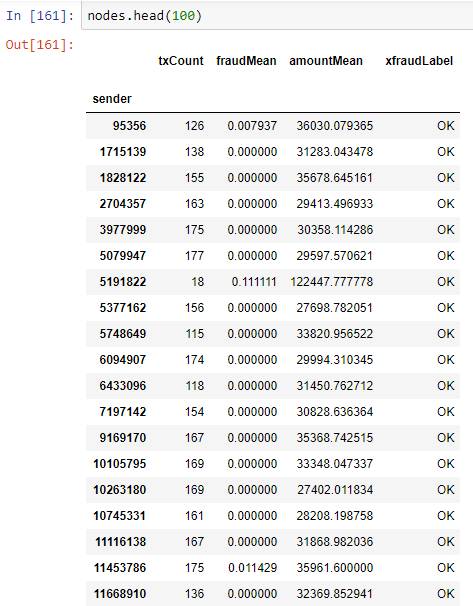
节点文件(customerTx.node)记录图中每个节点上的信息,作为每笔交易的资金发送者。 txCount列出了离开节点的事务(边)的数量。amountMean列指定平均事务大小。fraudMean列是此数据期间发送方帐户上标记的交易的平均值。请注意,绝大多数交易是正常的,而不是FRAUD,这是数据集的失衡问题。
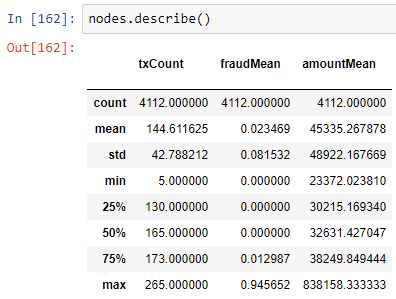
图中有4112个节点。一个分析员平均有2.3%被标记为有问题的。
我们现在可以用kegra来分析不同级别的分析师的准确性。如果系统训练是在由一个完美的分析师分析的数据上进行的,那么应该完美地学会如何分析图。但是,如果人类分析师错误的次数达到20%,那么kegra模型的预测能力同样应该被限制在80%。为了解决这个问题,我在图标签上添加了不同数量的随机噪声,看看当训练数据的质量越来越差时kegra如何处理。下面是图表和表格形式的结果展示:
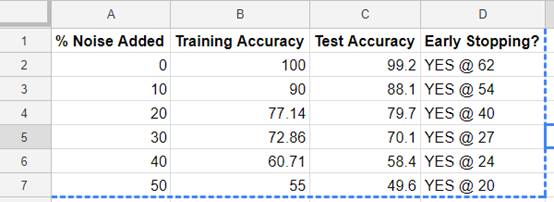
交易标签实验的原始结果,在知识图上进行深度学习。
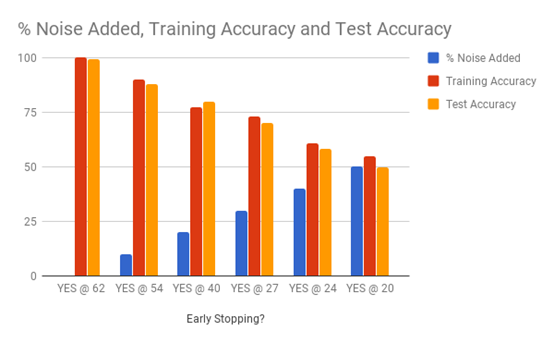
这与上表中的数据相同,但柱状图更易于理解。
这里有很多东西要理解。首先,我们看到在数据(蓝色)中的噪声增加时,提前停止(x轴上的标签)在训练中越来越早的发生了 。这告诉我们,特征数量太少(少量列)导致训练数据过度拟合。其次,我们看到测试的准确性一般低于训练的准确性。这在意料之中,因为分类器更熟悉训练数据而不是测试数据。第三,测试精度不为零。这意味着分类器可以仅使用每个节点的图和特征(txCount,amountMean和fraudMean)来重新生成OK / FRAUD标签。第四,分类器(橙色)的准确度随着注入噪声(蓝色)的升高而下降。这意味着结果不是随机的。第五,我们看到训练的准确性(红色)加上附加的噪音(蓝色)增加了大约100%,这意味着分类器与标注数据集的分析师保持一致,但是差不了多少。
总之,kegra在知识图谱分类上表现的非常好。与他们的论文中的结果相比,这些结果可能太好了。我将检查事务文件中的诈骗标签列是否有太好的解释性,然后用一些更难从广泛的数据集来预测的特征(如原产国,城市,邮编和更多其他的列)来替代它。
我的下一个行动是从更多列的源文件中重新生成事务数据集,然后查看kegra是否仍然执行得非常好。在cora数据集上,并没有提早停止,所以我怀疑交易数据对kegra来说并不具有挑战性,这是我之前提到的原因之一。也许我可以把更多的语义特征嵌入到生成的图表中.下一步我可以做很多有趣的事情。
特别感谢Thomas Kipf在出版之前对这篇文章进行检查。与我平时的高水平文章相比,这是一篇非常难懂的文章。如果你喜欢这篇关于知识图谱的深度学习的文章,那么请让我知道来写更多的这样的研究内容。我也很高兴在评论中听到您的意见。
你可以鼓掌、点赞,在媒体中Follow我们的工作,并分享这篇文章的链接。
参考链接
博文链接:
https://towardsdatascience.com/kegra-deep-learning-on-knowledge-graphs-with-keras-98e340488b93
代码地址:
https://github.com/tkipf/keras-gcn



