谷歌提出:用于目标检测的数据增广新方法
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:我好菜啊
https://zhuanlan.zhihu.com/p/76446741
本文已由作者授权,未经允许,不得二次转载
前段时间比较忙,已经很没写文章了,最近集中来更新一下吧。今天要讲的是Google Brain带来的一篇关于Data Augmentation的文章,但是增广的数据是目标检测数据,仅需要Data Augmentation便可以达到SOTA的水平。文章的题目是Learning Data Augmentation Strategies for Object Detection,这个团队还有一个用NAS搜索目标检测网络的工作。

arXiv:https://arxiv.org/abs/1906.11172
Background
众所周知,深度神经网络是强有力的机器学习系统,在大量数据上能够取得非常好的表现。为了增加深度学习训练数据,很多工作提出了数据增广的策略。在图像领域,常见的增广包括平移、镜像等。在分类模型中,常见的数据增广策略有尺度、平移、旋转。在目标检测任务中,较多使用镜像和多尺度训练进行数据增广。除此以外,一些方法在图像上随机增加噪声、遮挡等,或者在训练图像上增加新物体。
当前大多数图像分类器使用人工数据增广方法,目前有一些工作不再使用人工数据增广方法,而是使用从数据中学习到的策略以提升图像分类模型的性能。对于分类模型,能够通过变换或生成的方式对数据进行增广。与分类任务不同,由于标注检测数据的代价比较大,用于检测的数据比较稀缺。同时,图像变形、检测框位置、检测数据集中物体的大小都使得找到合适的数据增广策略更加困难。基于此产生如下问题:是否直接使用图像分类任务的数据增广策略?对于检测框和检测中的内容如何处理?本文由此针对目标检测问题设计了一个方法,用于合并和优化数据增广的策略,来提升目标检测的效果。
Contribution
1. 针对目标检测问题设计了一个方法,用于合并和优化数据增广的策略
2. 验证了不同检测结构、数据集下,方法正确率的提升,特别是在COCO取得SOTA的结果,在PASCAL VOC上取得有竞争力的结果
3. 学习到的数据增广策略对小数据有较大帮助,避免过拟合
Method
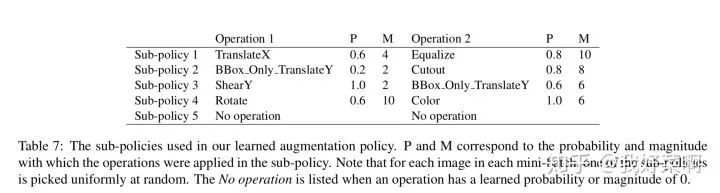
对于一个增广策略,将其分解成K个子策略,在训练过程中随机选择每个子策略,将该策略应用到当前图像上。其中,每个子策略包括N个图像变换。将搜寻最佳数据增广策略的问题就转换成在搜索空间中的离散优化问题。搜索结果最终包含5个子策略,每个子策略包含2个操作。对于每个操作,有两个超参数,包括执行该操作的概率和操作的大小(将超参数的值离散化到0-10之间,对于两个超参数分别在0-10之间取L和M个均匀间隔的值,在实际过程中L=M=6时,如0、2、4、6、8、10,取得计算复杂度和学习性能的平衡)。在实验中,对于目标检测任务,搜索空间中包含22种操作。整个搜索空间包含(22*6*6)^(2*5),约9.6*10^26种可能。(注:会在后面举例说明)
定义如下三类操作(一个策略包含K个子策略,每个子策略包含N个图像变换,这里的操作对应着图像变换):
颜色操作:改变颜色通道,不改变检测框的位置,如均衡Equalize、对比度Contrast、亮度Brightness(使用PIL库中的颜色转换)
几何操作:对图像做几何改变,同时会改变检测框的位置的大小,如旋转Rotate、平移Translation
检测框操作:只改变检测框内的像素,如BBox_Only_Equalize、BBox_Only_Rotate

将搜寻最佳数据增广策略的问题就转换成在搜索空间中的离散优化问题,当前存在许多解决离散优化问题的方法,包括强化学习,基于序列模型的优化等。本文选择在先前工作的基础之上,将离散优化问题构建为RNN的输出空间,并采用强化学习来更新模型的权重(。实验选取ResNet-50作为主干网络、RetinaNet作为检测器,使用400 TPU训练48小时,图像训练5K张,最终得到最佳的目标增强策略,并在7392张图像上进行测试。
Result
本文实验表明,使用一个优化的数据增广策略能够提升2.3mAP,并且达到SOTA的50.7mAP。同时,在COCO数据集上学习到的最佳策略能够迁移到其他检测数据集,使得模型在PASCAL-VOC数据集上提高2.7mAP。
在搜索空间good policies中出现比较多的是旋转Rotation(旋转之后检测框为了包含目标物体,检测框通常会变大),其次出现比较多的两个操作分别是均衡化Equalize(直方图均衡化)、检测框内像素在Y方向的平移BBox_Only_TranslateY(上下平移概率相同)。
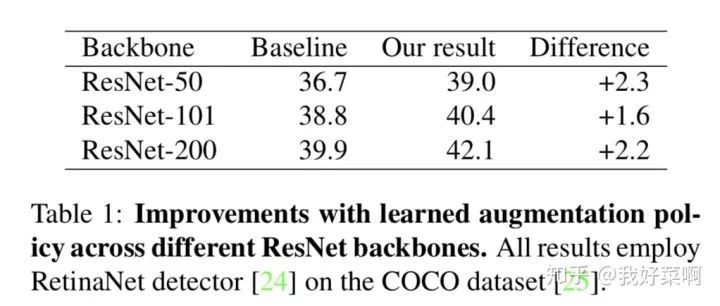
针对不同的backbone,目标检测性能均有提升
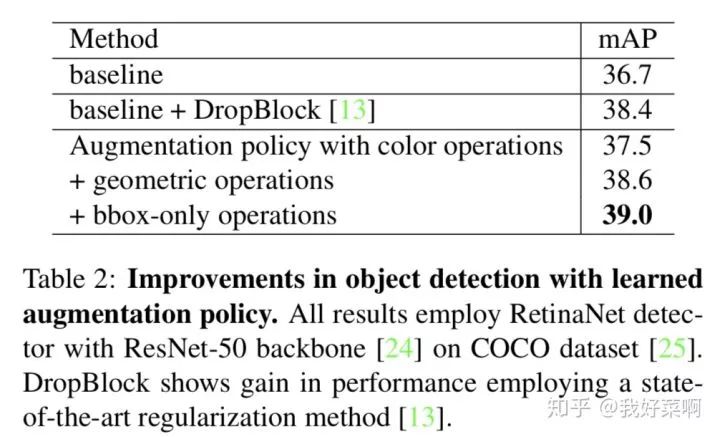
三类不同操作(颜色操作、几何操作、检测框操作)对目标检测性能提升的单独影响
本文将主干网络换成用ImageNet数据集预训练的AmoebaNet-D模型,将检测器换成NAS-FPN,将图像尺寸由640提升到1280,选取4个目标检测策略,即包含20个子策略,在COCO数据集上取得50.7 mAP的结果,达到SOTA
同时还有在不同样本和尺寸以及在不同AP下的结果,这里就不再赘述
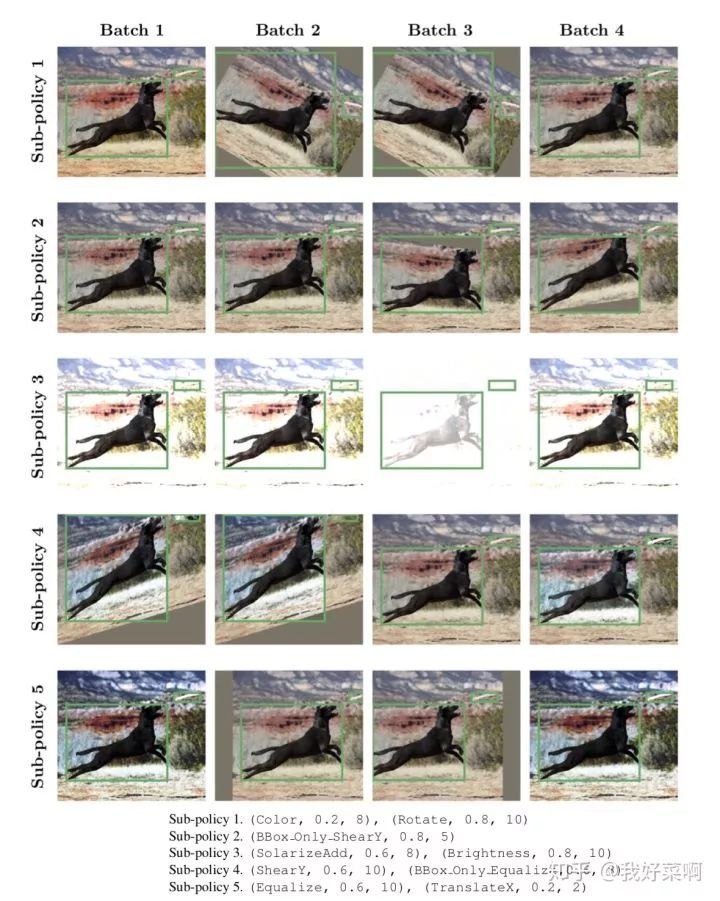
下面简要讲解一下附录7中的策略:
子策略1 沿X轴方向的平移,发生概率0.6,程度为-30像素(文中将平移的程度范围[-150 pixels, 150 pixels]对应到[0, 10],对应地,4代表-30像素,依此类推);均衡化,发生概率为0.8(由于直方图均衡化并没有程度,所以只有发生概率)
子策略2 检测框内像素沿Y轴方向的平移,发生概率为0.2,程度为-90像素;cutout,随机从图像中减去一个正方形区域(置灰),发生概率为0.8,程度为48像素
子策略3 shear,让所有点x轴不动,y轴坐标按比例平移,即x = x0,y = y0 + k*x0,发生概率为1.0,程度为-0.18,即k = -0.18;检测框内像素沿Y轴方向的平移,发生概率为0.6,程度为30像素
子策略4 旋转,发生概率为0.6,程度为30度;color,调整色彩平衡,发生概率为1.0,程度为1.18
子策略5 空操作;空操作
对于上述5个子策略,对于mini-batch里的每个图像都会随机从5个子策略中选择一个,基本这篇文章也讲述差不多了,立一个flag:在9月份之前复现这篇文章的策略部分,能够实际运用到实践中增加目标检测算法的性能,届时会开源到我的GitHub上,欢迎follow与star。https://github.com/MrPhD
重磅!CVer-目标检测交流群成立啦
扫码添加CVer助手,可申请加入CVer-目标检测交流群,同时还可以申请图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测和模型剪枝&压缩等群。一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡)

▲长按加群

▲长按关注我们
麻烦给我一个在看!



