convlab2中强化学习方法之对话策略学习浅析

CrossWoZ是一个多轮对话的中文数据集。对应的github地址在这
https://github.com/thu-coai/ConvLab-2
论文里面为了解决多轮对话的对话策略问题,分别用了基于规则(RulePolicy)和多种强化学习方法(比如PPOPolicy)。结果如下。
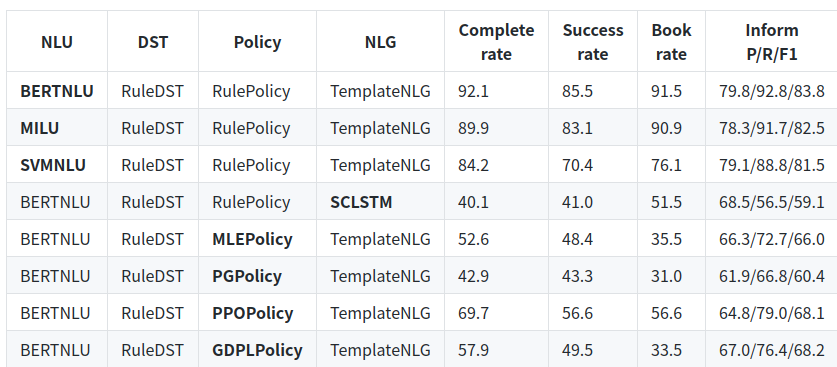
可以看到,Success rate 在RulePolicy中的表现远高于基于强化学习模型的policy。尽管如此,本文还是以学习的态度进入github地址分析了一下作者的代码。稍微还原一下强化学习PPOPolicy在多轮对话中建模的过程。
在具体的实现过程中,一共有以下几个重要概念
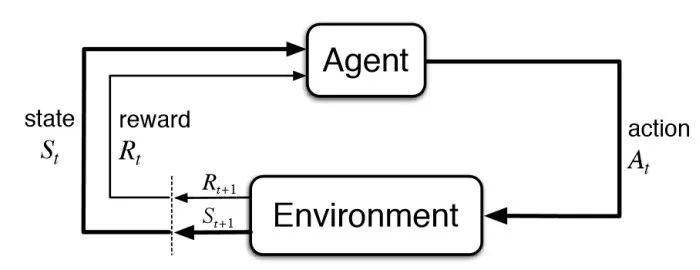
对话状态 s
动作 a
回报 r
以代码仓库中PPOPolicy中的参数为例,s 是340维的0/1分布的离散空间,分别对应着多领域对话过程中的340个状态;a 是209维0/1离散空间,分别对应着在状态s下所可能执行的对应动作;回报 r 是根据环境确定的,比如如果完成了对话,则回报会给予一个很大的数,如果没有任何增益,则为 -1。
下面是代码实现,简单易懂。
值函数
class Value(nn.Module):def __init__(self, s_dim, hv_dim):super(Value, self).__init__()self.net = nn.Sequential(nn.Linear(s_dim, hv_dim),nn.ReLU(),nn.Linear(hv_dim, hv_dim),nn.ReLU(),nn.Linear(hv_dim, 1))def forward(self, s):""":param s: [b, s_dim]:return: [b, 1]"""value = self.net(s)return value
当前状态对应的价值value,完全由状态s通过三层全连接确定。
动作函数a
self.net = nn.Sequential(nn.Linear(s_dim, h_dim),nn.ReLU(),nn.Linear(h_dim, h_dim),nn.ReLU(),nn.Linear(h_dim, a_dim))
状态s下的动作也是用全连接来生成。但是具体使用的时候会有采样输出
def select_action(self, s, sample=True):""":param s: [s_dim]:return: [a_dim]"""# forward to get action probs# [s_dim] => [a_dim]a_weights = self.forward(s)a_probs = torch.sigmoid(a_weights)# [a_dim] => [a_dim, 2]a_probs = a_probs.unsqueeze(1)a_probs = torch.cat([1-a_probs, a_probs], 1)a_probs = torch.clamp(a_probs, 1e-10, 1 - 1e-10)# [a_dim, 2] => [a_dim]a = a_probs.multinomial(1).squeeze(1) if sample else a_probs.argmax(1)return a
然后根据nn生成的价值函数v和环境给出的真实回报r,使用贝尔曼方程和优势梯度估计获取更新的价值函数v和优势。因为多轮对话是连续的,因此代码实现的时候通过mask来控制识别单轮和多轮。新生成的价值函数可以用来更新上面的价值网络Value。优势计算的结果则可以帮助更新策略网络net,以优化动作函数a。
def est_adv(self, r, v, mask):"""we save a trajectory in continuous space and it reaches the ending of current trajectory when mask=0.:param r: reward, Tensor, [b]:param v: estimated value, Tensor, [b]:param mask: indicates ending for 0 otherwise 1, Tensor, [b]:return: A(s, a), V-target(s), both Tensor"""batchsz = v.size(0)# v_target is worked out by Bellman equation.v_target = torch.Tensor(batchsz).to(device=DEVICE)delta = torch.Tensor(batchsz).to(device=DEVICE)A_sa = torch.Tensor(batchsz).to(device=DEVICE)prev_v_target = 0prev_v = 0prev_A_sa = 0for t in reversed(range(batchsz)):# mask here indicates a end of trajectory# this value will be treated as the target value of value network.# mask = 0 means the immediate reward is the real V(s) since it's end of trajectory.# formula: V(s_t) = r_t + gamma * V(s_t+1)v_target[t] = r[t] + self.gamma * prev_v_target * mask[t]# please refer to : https://arxiv.org/abs/1506.02438# for generalized adavantage estimation# formula: delta(s_t) = r_t + gamma * V(s_t+1) - V(s_t)delta[t] = r[t] + self.gamma * prev_v * mask[t] - v[t]# formula: A(s, a) = delta(s_t) + gamma * lamda * A(s_t+1, a_t+1)# here use symbol tau as lambda, but original paper uses symbol lambda.A_sa[t] = delta[t] + self.gamma * self.tau * prev_A_sa * mask[t]# update previousprev_v_target = v_target[t]prev_v = v[t]prev_A_sa = A_sa[t]# normalize A_saA_sa = (A_sa - A_sa.mean()) / A_sa.std()return A_sa, v_target
还有很多种强化学习方法,共同的目的都是学习更好的动作函数网络。如果对强化学习方法感兴趣可以继续深入仓库探索。
推荐阅读
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
深度学习如何入门?这本“蒲公英书”再适合不过了!豆瓣评分9.5!【文末双彩蛋!】
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。



