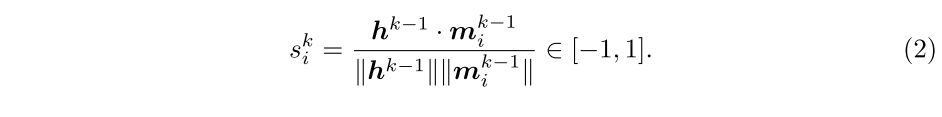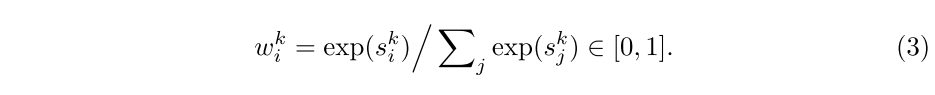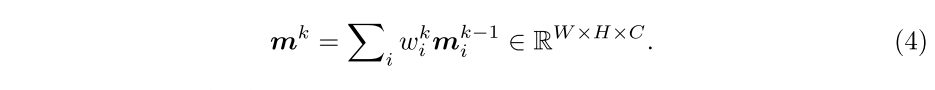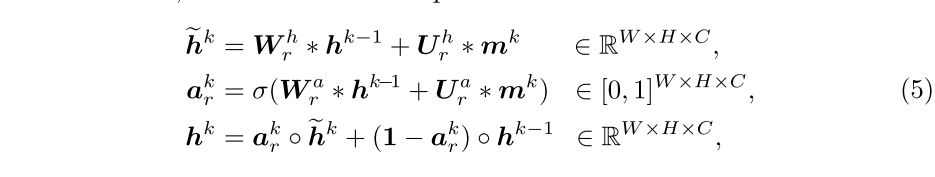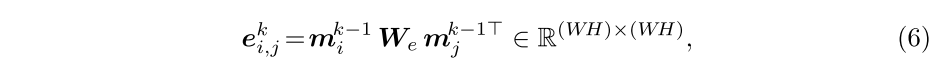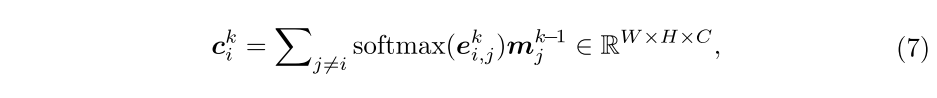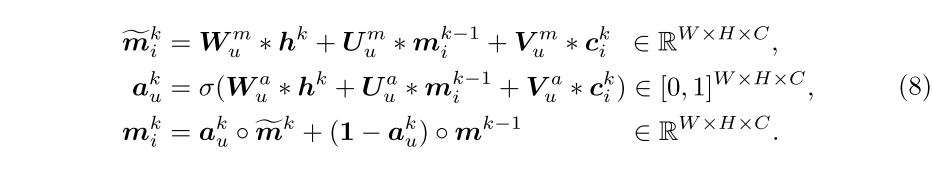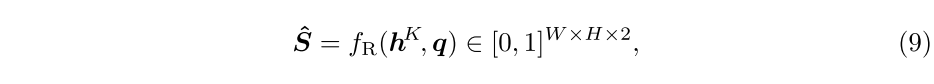点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达![]()
本文转载自:极市平台
本文着力于解决视频目标分割领域的一个基本问题:使分割模型有效适应特定视频以及在线目标的外观变化。提出了一种简洁快速的新图存储机制,显著改善了分割预测。此外,图存储网络产生的框架还可以推广到one-shot和zero-shot视频目标分割任务。
本文主要解决视频目标分割领域的一个基本问题:
如何使分割模型能够有效地适应特定视频以及在线目标的外观变化?
解决办法:提出一个
图存储网络来对分割模型进行“学习更新”。
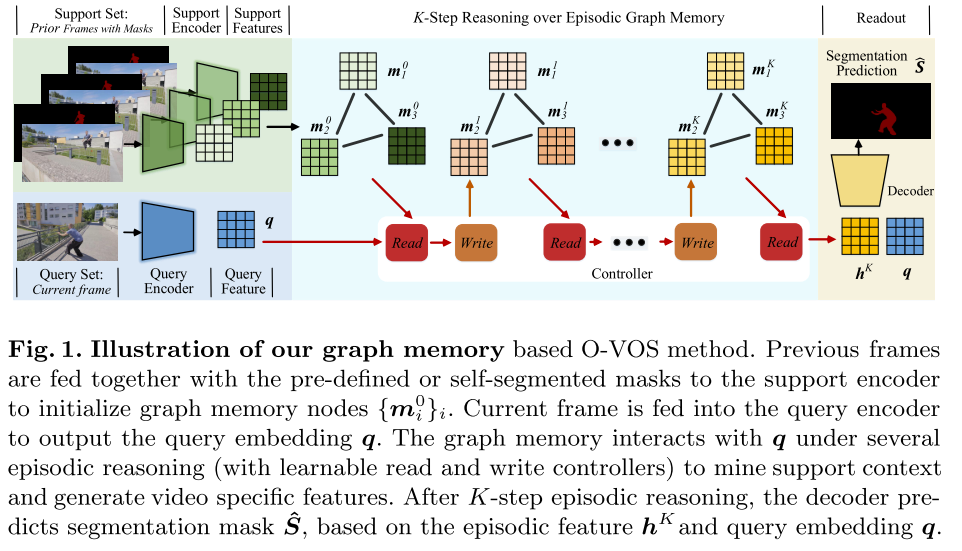
大概流程分为两步:首先构建一个由全连接图构成的情景存储网络,将帧存储为节点,并通过边捕获跨帧的相关性。然后,可学习的控制器被嵌入以简化内存的读写。
相比于以往模型的优势:结构化的外部存储使可以在视觉信息有限的情况下全面挖掘并快速存储新知识。不同的存储控制器通过梯度下降学习了一种抽象的表示方法,可以利用这种表示学习进行预测 。另外,图存储网络产生的框架,可以推广到one-shot和zero-shot视频目标分割任务。
论文链接:
https://arxiv.org/pdf/2007.07020.pdf
代码:
https://github.com/carrierlxk/GraphMemVOS.git
1.引言
视频目标分割(VOS)旨在像素级别对视频中的一个目标进行预测,目前根据第一帧的视频是否有注释可以把VOS分为两类:one-shot视频目标分割(O-VOS)和zero-shot视频目标分割(Z-VOS)。
O-VOS:提供第一帧的视频注释,可以对视频其他部分带标签的目标进行分割预测。
Z-VOS:在没有任何测试时间指示的情况下自动推断主要目标。
O-VOS的主要困难:没有关于特定目标的假设,应用场景有干扰对象。
针对O-VOS以往的解决方法:较早的方法,在每个带注释的目标上构建network finetuning-缺点:耗时。当前流行的方法,建立一个匹配框架,将该任务描述为支持集和查询集之间的匹配流程。
1.首先学习通用匹配网络,然后将其直接应用于测试视频,无法充分利用第一帧目标特定信息。结果导致其不能有效地适应输入视频。
2.由于分割目标可能会出现外观变化,因此执行在线模型更新很有意义。
3.基于匹配的方法仅对查询和每个支持帧之间的配对关系建模,而忽略了支持集中的上下文。
本文受到了最近小样本学习的记忆增强网络的启发而提出的方法:
开发了一个图存储网络,以通过单次前馈使在线分割模型适应特定目标。
本文模型的一些优势:图存储网络简洁,快速。对于内存更新,模型在固定大小的图内存上执行消息传递,而不增加内存消耗。模型提供了一个框架;它概括了Z-VOS任务,而主流方法缺乏自适应能力。这项工作代表了在统一网络设计中同时解决O-VOS和Z-VOS的第一部分。
2.方法
2.1 预备知识:情景记忆网络
背景:记忆网络通过外部存储组件增强了神经网络,使网络可以显式访问过去的经验。常应用于小样本学习和目标追踪中。
解决的相关任务:情景外部存储器网络解决视觉问题回答和视觉对话中的推理问题。
基本思想:使用可学习的读写运算符从内存中检索回答问题所需的信息。给定输入表示的集合,情节记忆模块通过神经注意力选择要关注的输入部分。然后在考虑查询以及存储的情况下生成“内存摘要”表示形式。情节中的每个迭代为存储模块提供有关输入的相关信息。最后存储模块具有在每次迭代中检索新信息并获得有关输入的新表示的能力。
目标:从第一帧中带注释的目标学习,在后续帧中对其进行预测。
传统方法:将网络连接到一起,并为每个特定的视频执行在线学习。
本文的方法:根据训练任务的分布对各种任务构造基于情境记忆的学习器,从而使学习的模型在新的不可见的任务(测试视频)上表现良好。将O-VOS作为“学习更新”的分割网络来处理。
ii)给定任务表示形式,更新查询的分割网络。如图1所示,增强具有图结构的情景存储网络(即图存储网络),以便:i)立即使分割网络适应特定的对象,而不是执行大量的迭代;ii)充分利用视频序列中的上下文。
本文的图存储网络具有两种能力:在模型初始化阶段学会从one-shot支持集调整分割网络,学会在帧处理阶段利用分割帧来更新分段网络
结构:由一个外部图存储器和用于存储操作的可学习控制器组成。
外部图存储器:为新知识编码提供了短期存储,其图结构允许全面探索上下文。
控制器:进行读取和写入操作,与图存储器交互,通过权重的缓慢更新来长期存储。通过控制器,模型可学习两方面的内容:1.其放入内存的表示类型,2.以后如何将这些表示用于细分预测的通用策略。
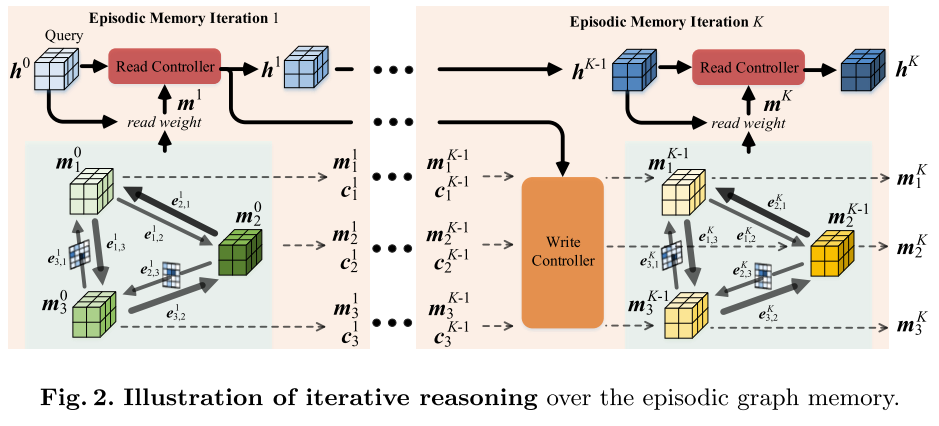
图存储网络的核心思想:执行情节推理的K个步骤,以有效挖掘内存中的结构并更好地捕获目标特定的信息。
存储器被组织为一个大小固定的全连接图
,其中节点
表示第i个存储单元,边
表示 单元格
和
之间的关系。
给定一个查询帧,支持集被认为是第一个带注释的帧和先前分割的帧的组合。从支持集采样的
帧初始化图内存。对于每个存储节点
,通过将全卷积存储编码器应用于支持帧以捕获空间视觉特征以及分割mask信息,来生成其初始嵌入
。
图内存读取。全卷积查询编码器也应用于查询帧,以提取视觉特征
。一个可学习的读取控制器首先将q作为输入并生成其初始状态
:
在每个情节推理步骤
,读取控制器通过读取内容与外部图存储器进行交互。遵循键值检索机制,先计算查询与每个内存节点
之间的相似度:
接下来通过softmax归一化函数计算读取权重
:
考虑到某些节点由于底层相机移动或视线不佳而产生噪声,因此
可以测量存储单元
的置信度。然后使用此权重检索内存聚合
以线性组合内存单元:
通过等式(2-4),存储器模块检索与
最相似的存储器单元,以获得存储器聚合
。读取内存汇总后,读取控制器将更新其状态,如下所示:
其中
和
是卷积核,σ表示Sigmoid激活函数。“ *”和“◦”分别代表卷积运算和Hadamard乘积。更新门
控制要保留多少先前的隐藏状态
。通过这种方式,控制器的隐藏状态对图存储器和查询表示进行编码。
每次通过内存汇总后,都需要使用新的查询输入来更新情节图内存。在每个步骤k,可学习的存储器通过考虑其先前状态
写入控制器,来自读取控制器
的当前内容以及来自其他单元
的状态来更新每个存储单元。 首先将从
到
的关系
公式化为其特征矩阵的内积相似性:
其中
表示可学习的权重矩阵,
和
被固定为矩阵表示形式。
存储与
和
中所有位置对 对应的相似性分数。
然后,对于
,从其他单元格计算归一化的信息
,并对其归一化的内积相似性进行加权:
汇总来自邻居的信息后,内存写控制器将
的状态更新为:
图内存更新允许每个内存单元将邻居信息嵌入到其表示中,以便全面探索支持集中的上下文。此外,通过对图结构进行迭代推理,每个存储单元对新的查询信息进行编码,并逐渐改进表示形式。与传统的存储网络相比,本文的图存储网络具有两个优点:i)将内存写操作融合到内存更新过程中,而不会增加内存大小,并且ii)避免设计复杂的内存写策略。图2显示了内存读取和更新。
最终分割Readout 在对情节性存储器进行K步更新之后,利用来自存储器读取控制器的最终状态
来支持对查询的预测:
网络配置 总体模型以端到端的全卷积实现;查询编码器和内存编码器都具有相同的结构;图存储器,读控制器(等式(5))和写控制器(等式(8))均使用具有1×1卷积内核的ConvGRU实现;投影函数fP(等式(1))也通过1×1卷积层实现;读出函数fR(等式(9))由一个解码器网络实现,该网络由四个块组成,这些块具有与相应的ResNet50块的skip-connection;解码器中每个卷积层的内核大小设置为3×3,最后一个1×1卷积层除外;查询和内存编码器实现为ResNet50的四个卷积块,由ImageNet上预训练的权重初始化;
输入 查询编码器以RGB查询帧作为输入;内存编码器,输入为RGB支持帧;存储器编码器以二进制掩码和实例标签图作为输入
训练 对于O-VOS,按照“递归训练”训练模型。通过对支持集进行采样以构建图存储器和相关查询集来形成每个训练周期。递归训练的核心是模仿推理过程。对每个视频采样N + 1帧构建支持集(前N帧)和查询集(最后一帧)。N个支持帧可以由N节点存储器图表示。将交叉熵损失应用于监督训练。
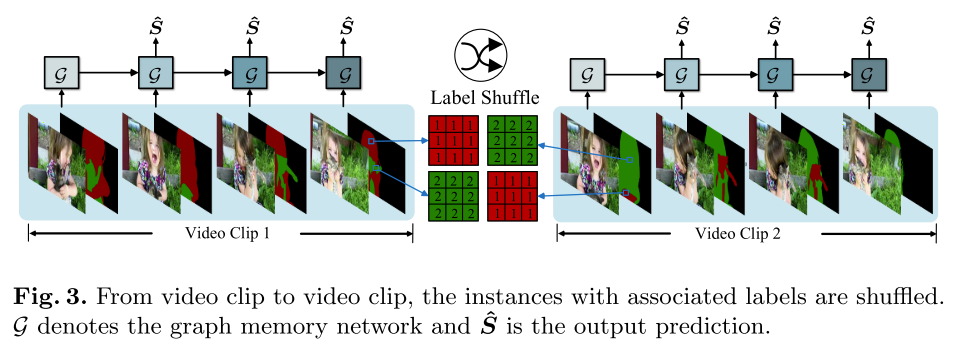
为了防止图记忆仅记住实例与单向矢量标签之间的关系,本文采用了标签关闭策略。如图3所示,分割网络通过考虑当前的训练样本而不是记住目标和给定标签之间的特定关系来学习区分当前帧中的特定实例。
为了进一步提高性能,通过合成视频扩展了训练集。对于静态图像,采用视频生成技术通过不同的变换操作来获得模拟的视频剪辑。静态图像来自现有的图像分割数据集。在对合成视频进行预训练之后,将真实视频数据用于微调。
对于Z-VOS,遵循与O-VOS类似的训练协议,但是输入模态仅具有RGB数据。本文专注于对象级别的Z-VOS设置,因此不使用标签切换策略。
推理 训练后直接将网络应用于测试集。对O-VOS按顺序处理每个测试视频。前N个帧直接计算内存汇总(等式(4))并将这些帧写入内存。从第(N + 1)帧开始,在分割之后将使用该帧更新图内存。考虑到第一帧及其注释始终提供最可靠的信息,重新初始化存储有关第一帧信息的节点。因此使用第一个带注释的帧,最后一个分割的帧和从先前的分割帧中采样的N-2个帧,以及它们的预定义或分割掩码来构建内存。对于多实例的情况,为每个实例独立运行模型,并为每个实例获得soft-max概率掩码。对于Z-VOS,从同一视频中随机采样N帧以构建图内存,然后根据所构建的内存处理每个帧。考虑到全局信息比局部信息对于处理潜在的对象遮挡和相机移动更重要,因此通过使用全局采样的帧重新初始化图形存储器来独立处理每个帧。
3.实验结果
O-VOS使用DAVIS17 和Youtube-VOS 数据集
3.2 Z-VOS的性能
Z-VOS使用DAVIS16 和Youtube-Objects数据集。
![]()
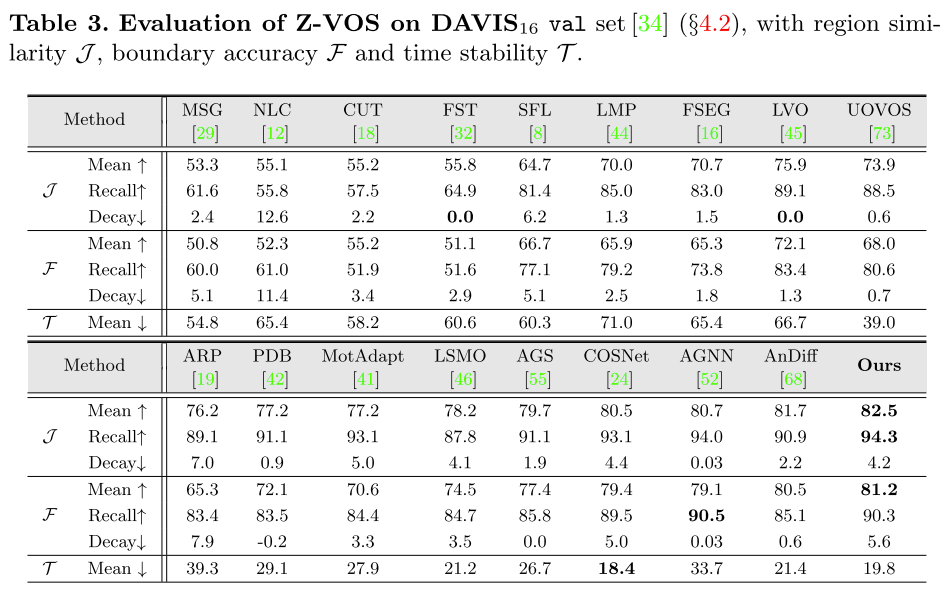
表3 Z-VOS在DAVIS16的评估
![]()
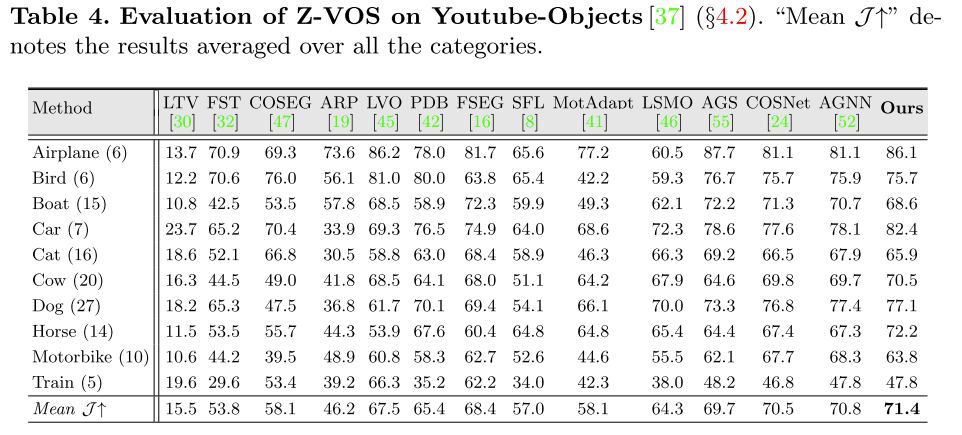
表4 Z-VOS在Youtube-Object的评估
![]() 图5 Z-VOS的量化结果
图5 Z-VOS的量化结果
4.总结
本文主要提出了一种新的图存储机制,可以有效地使分割网络适应特定视频。通过对存储图进行情节推理,所提出的模型能够生成视频专用的存储摘要,从而显着改善最终的分割预测。同时,可以通过可学习的内存控制器来实现在线模型更新。图存储网络简洁,快速。模型在内存更新时可以在固定大小的图内存上执行消息传递,而不增加内存消耗。
下载1
在CVer公众号后台回复:PRML,即可下载758页《模式识别和机器学习》PRML电子书和源码。该书是机器学习领域中的第一本教科书,全面涵盖了该领域重要的知识点。本书适用于机器学习、计算机视觉、自然语言处理、统计学、计算机科学、信号处理等方向。
![]()
PRML
下载2
在CVer公众号后台回复:CVPR2020,即可下载CVPR 2020代码开源的论文合集
在CVer公众号后台回复:ECCV2020,即可下载ECCV 2020代码开源的论文合集
重磅!CVer-图像分割 微信交流群已成立
扫码添加CVer助手,可申请加入CVer-图像分割 微信交流群,目前已汇集1500人!涵盖2D/3D目标检测、小目标检测、遥感目标检测等。互相交流,一起进步!
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如图像分割+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
![]()
▲长按加群
![]()
▲长按关注我们
整理不易,请给CVer点赞和在看!![]()