自注意力机制在计算机视觉中的应用【附PPT与视频资料】

关注文章公众号
回复"蒋正锴"获取PPT与视频资料
视频资料可点击下方阅读原文在线观看
导读
在神经网络中,我们知道卷积层通过卷积核和原始特征的线性结合得到输出特征,由于卷积核通常是局部的,为了增加感受野,往往采取堆叠卷积层的方式,实际上这种处理方式并不高效。同时,计算机视觉的很多任务都是由于语义信息不足从而影响最终的性能。自注意力机制通过捕捉全局的信息来获得更大的感受野和上下文信息。这次的分享主要从自注意力的角度分析最近的一些发展,以及相应的改进方案。
作者简介
蒋正锴,中科院自动化所模式识别国家重点实验室在读二年级硕士,本科毕业于东北大学自动化专业,发表AAAI 论文一篇,ECCV 2018实例分割第三名成员(第四作者)。目前的研究兴趣在图像视频的检测分割。

Introduction
自注意力机制 (self-attention)[1] 在序列模型中取得了很大的进步;另外一方面,上下文信息(context information)对于很多视觉任务都很关键,如语义分割,目标检测。自注意力机制通过(key, query, value)的三元组提供了一种有效的捕捉全局上下文信息的建模方式。接下来首先介绍几篇相应的工作,然后分析相应的优缺点以及改进方向。
RelatedWorks
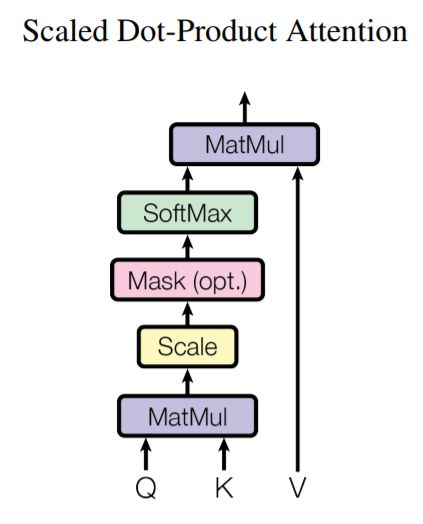
Attention is all you need [1] 是第一篇提出在序列模型中利用自注意力机制取代循环神经网络的工作,取得了很大的成功。其中一个重要的模块是缩放点积注意力模块(scaled dot-product attention)。文中提出(key,query, value)三元组捕捉长距离依赖的建模方式,如下图所示,key和query通过点乘的方式获得相应的注意力权重,最后把得到的权重和value做点乘得到最终的输出。
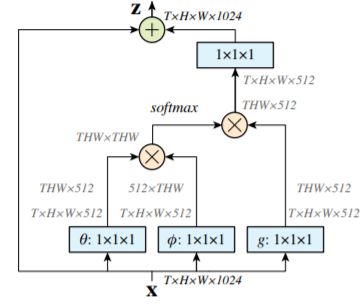
Non-localneural network [2] 继承了(key, query, value) 三元组的建模方式, 提出了一个高效的non-local 模块, 如下图所示。在Resnet网络中加入non-local模块后无论是目标检测还是实例分割,性能都有一个点以上的提升(mAP),这说明了上下文信息建模的重要性。
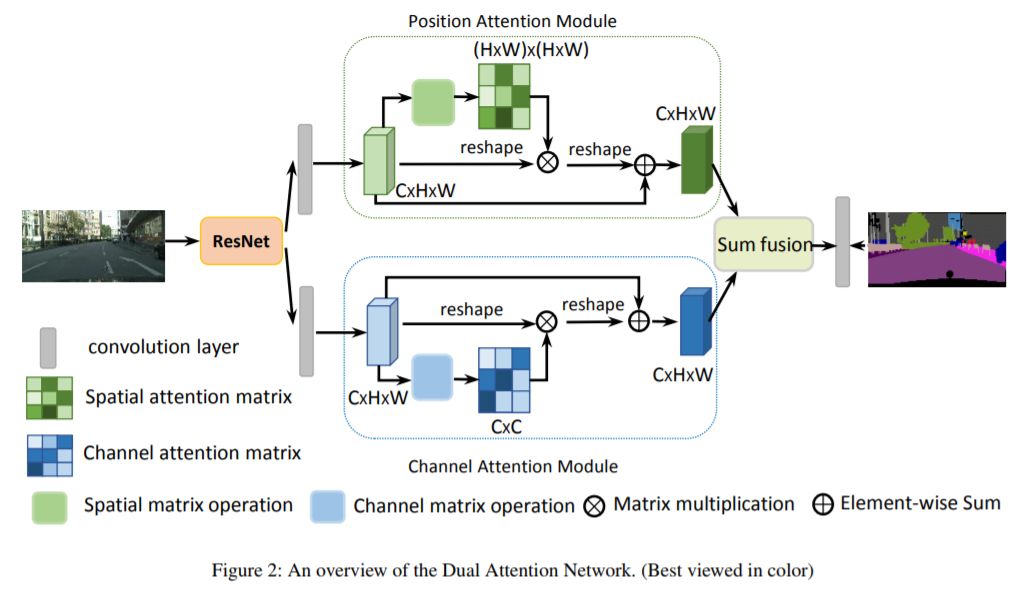
Danet [3]是来自中科院自动化的工作,其核心思想就是通过上下文信息来监督语义分割任务。作者采用两种方式的注意力形式,如下图所示,分别是spatial和 channel上,之后进行特征融合,最后接语义分割的head 网络。思路上来说很简单,也取得了很好的效果。
Ocnet[4]是来自微软亚洲研究所的工作。同样它采用(key, query, value)的三元组,通过捕捉全局的上下文信息来更好的监督语义分割任务。与Danet [3]不同的是它仅仅采用spatial上的信息。最后也取得了不错的结果。
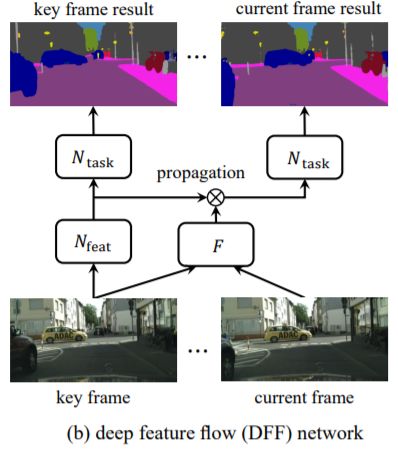
DFF [5] 是来自微软亚洲研究所视觉计算组的工作。如下图所示,它通过光流来对视频不同帧之间的运动信息进行建模, 从而提出了一个十分优雅的视频检测框架DFF。其中一个很重要的操作是warp, 它实现了点到点之间的对齐。在此以后出现了很多关于视频检测的工作,如, FGFA[6],Towards High Performance [7]等,他们大部分都是基于warp这个特征对其操作。由于光流网络的不准确性以及需要和检测网络进行联合训练,这说明现在视频检测中的光流计算其实不准确的。如何进行更好的建模来代替warp操作,并且起到同样的特征对其的作用是很关键的。通常而言我们假设flow运动的信息不会太远,这容易启发我们想到通过每个点的邻域去找相应的运动后的特征点,具体做法先不介绍了,欢迎大家思考(相关操作和自注意力机制)。
前面主要是简单的介绍了自注意力机制的用途,接下来分析它的缺点和相应的改进策略,由于每一个点都要捕捉全局的上下文信息,这就导致了自注意力机制模块会有很大的计算复杂度和显存容量。如果我们能知道一些先验信息,比如上述的特征对其通常是一定的邻域内,我们可以通过限制在一定的邻域内来做。另外还有如何进行高效的稀疏化,以及和图卷积的联系,这些都是很开放的问题,欢迎大家积极思考。
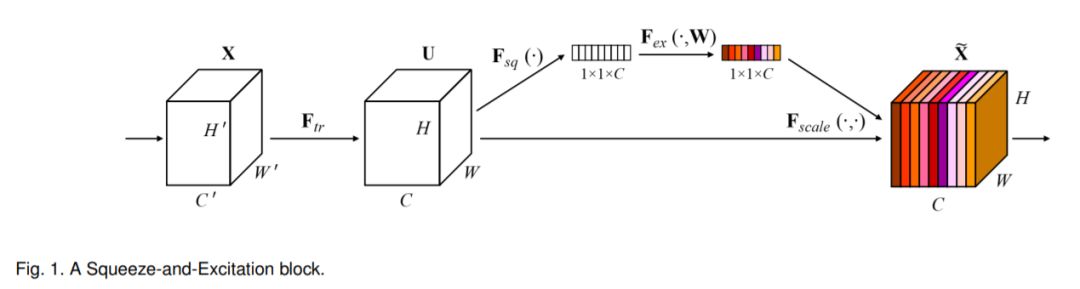
接下来介绍其他的一些改进策略,Senet[9] 启发我们channel上的信息很重要,如下图所示。
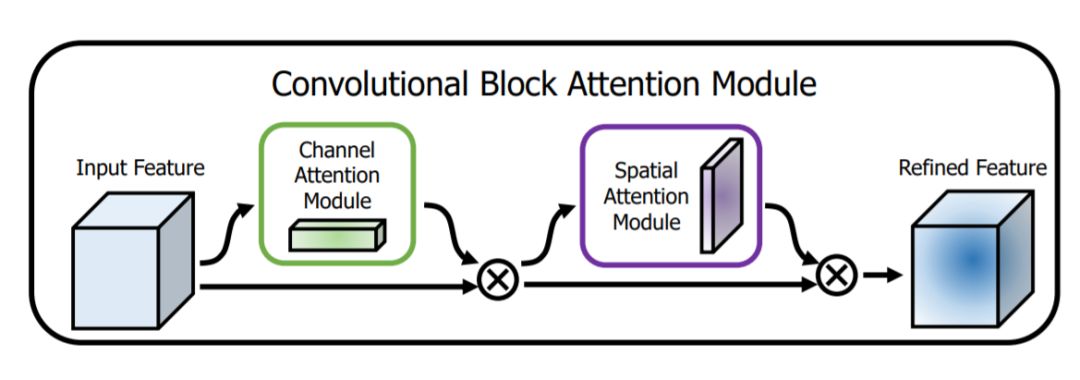
CBAW [10] 提出了结合spatial和channel的模块,如下图所示,在各项任务上也取得很好的效果。
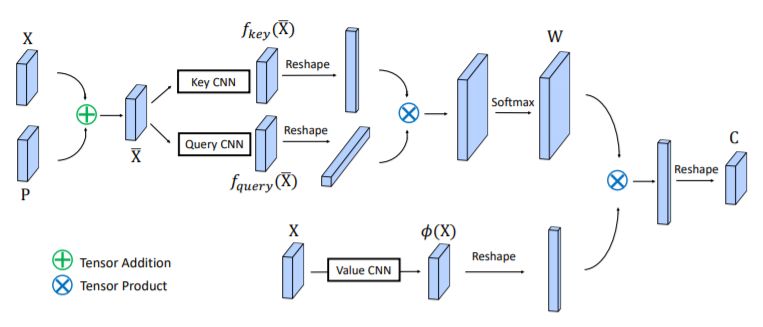
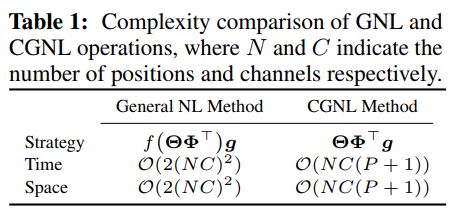
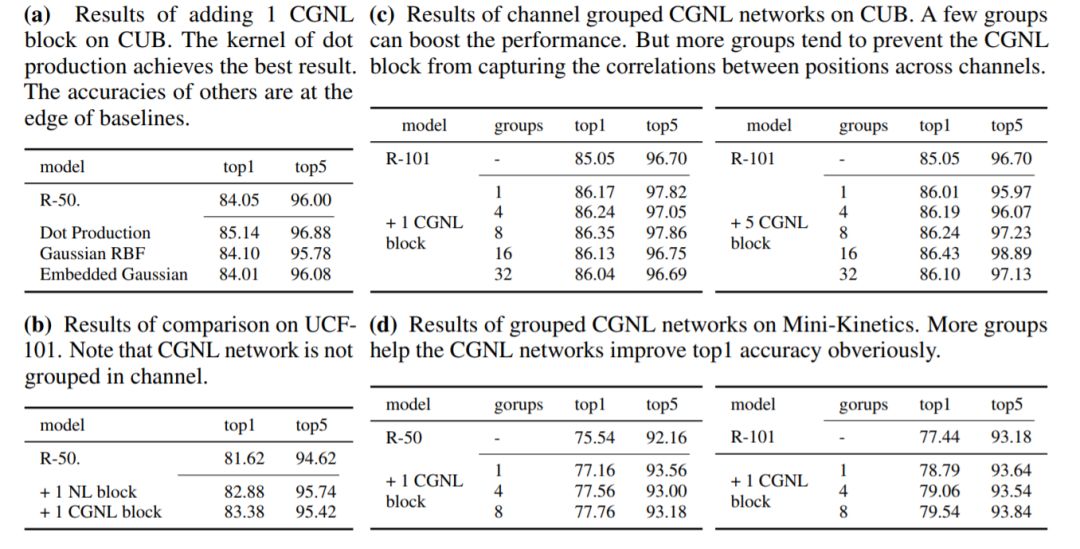
最后介绍一篇来自百度IDL的结合channel as spatial的建模方式的工作 [11]。本质上是直接在(key, query, value)三元组进行reshape的时候把channel的信息加进去,但是这带来一个很重要的问题就是计算复杂度大大增加。我们知道分组卷积是一种有效的降低参数量的方案,这里也采用分组的方式。但是即使采用分组任然不能从根本上解决计算复杂度和参数量大的问题,作者很巧妙的利用泰勒级数展开后调整计算key, query, value的顺序,有效的降低了相应的计算复杂度。下表是优化后的计算量和复杂度分析,下图是CGNL模块的整体框架。

通过和non-local[2]模块的对比,如下表所示,在视频分类任务上取得了很好的效果, 也说明了channel维信息的重要性。
TakeHome Message
自注意力机制作为一个有效的对上下文进行建模的方式,在很多视觉任务上都取得了不错的效果。同时,这种建模方式的缺点也是显而易见的,一是没有考虑channel上信息,二是计算复杂度仍然很大。相应的改进策,一方面是如何进行spatial和channel上信息的有效结合,另外一方面是如何进行捕捉信息的稀疏化,关于稀疏的好处是可以更加鲁棒的同时保持着更小的计算量和显存。最后,图卷积作为最近几年很火热的研究方向,如何联系自注意力机制和图卷积,以及自注意力机制的更加深层的理解都是未来的很重要的方向。
Reference
[1]Ashish Vaswani et al. Attention Is AllYou Need. In NIPS, 2017
[2] Xiaolong Wang et al. Non-local Neural Networks. In CVPR, 2018
[3] JunFu et al. Dual Attention Network for Scene Segmentation. In arxiv, 1809.02983
[4]Yuhui Yuan et al. OCNet: Object Context Network for Scene Parsing. In arxiv,1809.00916
[5]Xizhou Zhu et al. Deep Feature Flow for Video Recognition. In CVPR 2017
[6]Xizhou Zhu et al. Flow-Guided Feature Aggregation for Video Object Detection.In ICCV 2017
[7]Xizhou Zhu et al. Towards High Performance for Video Object Detection. In CVPR2018
[8]Zhengkai Jiang et al. Video Object Detection with Locally-Weighted DeformableNeighbors. In AAAI 2019
[9] JieHu et al. Squeeze-and-Excitation Networks. In CVPR2018
[10]Sanghyun Woo et al. CBAM: Convolution Block Attention Module. In ECCV 2018
[11]Kaiyu Yue et al. Compact Generalized Non-local Network. In NIPS 2018
SFFAI讲者招募
为了满足人工智能不同领域研究者相互交流、彼此启发的需求,我们发起了SFFAI这个公益活动。SFFAI每周举行一期线下活动,邀请一线科研人员分享、讨论人工智能各个领域的前沿思想和最新成果,使专注于各个细分领域的研究者开拓视野、触类旁通。
SFFAI目前主要关注机器学习、计算机视觉、自然语言处理等各个人工智能垂直领域及交叉领域的前沿进展,将对线下讨论的内容进行线上传播,使后来者少踩坑,也为讲者塑造个人影响力。
SFFAI还将构建人工智能领域的知识树(AI Knowledge Tree),通过汇总各位参与者贡献的领域知识,沉淀线下分享的前沿精华,使AI Knowledge Tree枝繁叶茂,为人工智能社区做出贡献。
这项意义非凡的社区工作正在稳步向前,衷心期待和感谢您的支持与奉献!
有意加入者请与我们联系:wangxl@mustedu.cn


历史文章推荐:



