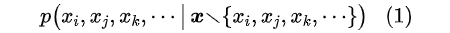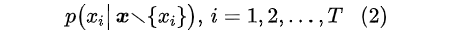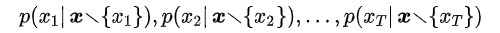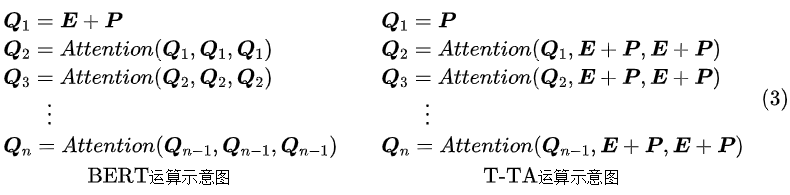©PaperWeekly 原创 · 作者|苏剑林
单位| 追一科技
研究方向| NLP、神经网络
大家都知道,MLM (Masked Language Model) 是 BERT、RoBERTa 的预训练方式,顾名思义,就是 mask 掉原始序列的一些 token,然后让模型去预测这些被 mask 掉的 token。
随着研究的深入,大家发现 MLM 不单单可以作为预训练方式,还能有很丰富的应用价值,比如笔者之前就发现直接加载 BERT 的 MLM 权重就可以当作 UniLM 来做 Seq2Seq 任务(参考这里 ),又比如发表在 ACL 2020 的 Spelling Error Correction with Soft-Masked BERT [1] 将 MLM 模型用于文本纠错。
然而,仔细读过 BERT 的论文或者亲自尝试过的读者应该都知道,原始的 MLM 的训练效率是比较低的,因为每次只能 mask 掉一小部分的 token 来训练。ACL 2020 的论文 Fast and Accurate Deep Bidirectional Language Representations for Unsupervised Learning
论文标题: Fast and Accurate Deep Bidirectional Language Representations for Unsupervised Learning
论文链接: https://arxiv.org/abs/2004.08097
代码链接: https://github.com/joongbo/tta
假设原始序列为
,
表示将第 i 个token 替换为
后的序列,那么 MLM 模型就是建模:
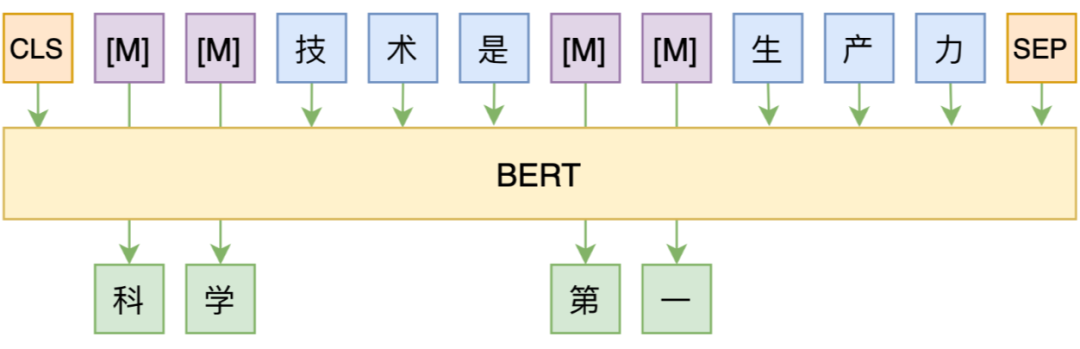
我们说它效率低,是因为每次只能选择一小部分 token 来 mask,比如 15%,那么也就是说每个样本只有 15% 的 token 被训练到了,所以同一个样本需要反复训练多次。在 BERT 里边,每个样本都被 mask 了多遍然后存为 tfrecord,训练效率低的同时还增加了硬盘空间占用。
▲ MLM任务示意图
如果训练的时候每个样本的所有 token 都可以作为预测目标,那么训练效率自然就能提升了。像 GPT 这样的单向语言模型是可以做到的,但是 MLM 是双向的模型,并不能直接做到这一点。为了达到这个目标,我们需要简化一下上式,假设每次只 mask 掉一个 token,也就是要构建的分布为:
怎么做到这一点呢?这就来到本文要介绍的论文结果了,它提出了一种称之为 T-TA (Transformer-based Text Autoencoder) 的设计,能让我们一并预测所有 token 的分布。
T-TA介绍
首先,我们知道 Transformer 的核心运算是
,在 BERT 里边
都是同一个,也就是 Self Attention。而在 MLM 中,我们既然要建模
,那么第 i 个输出肯定是不能包含第 i 个 token 的信息的。
为此,第一步要做出的改动是:去掉
里边的 token 输入,也就是说第一层的 Attention 的
不能包含 token 信息,只能包含位置向量。这是因为我们是通过
把
的信息聚合起来的,如果
本身就有 token 信息,那么就会造成信息泄漏了。
改了
之后,我们就可以防止来自
的信息泄漏,接下来我们就要防止来自
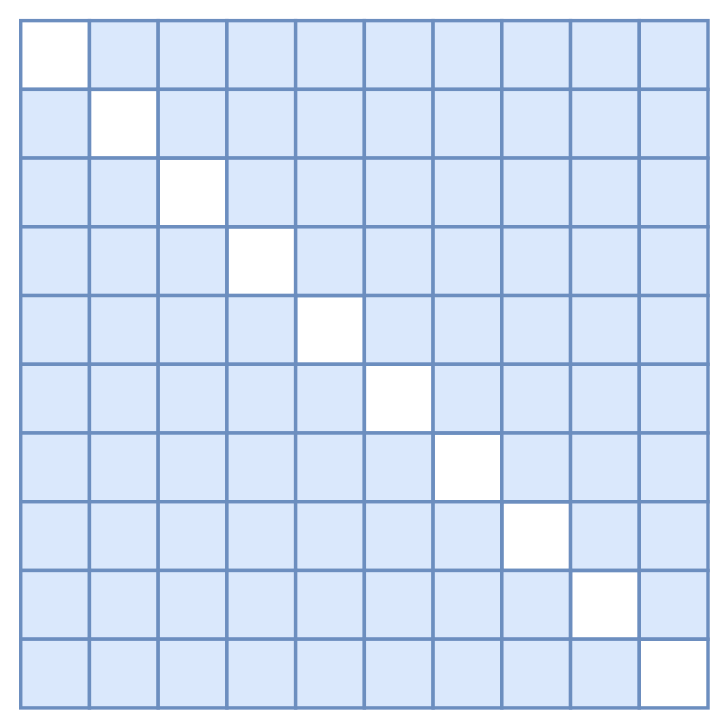
的信息泄漏了,这需要修改 Attention Mask,把对角线部分的 Attention(也就是自身的)给 Mask 掉,如图所示:
▲ T-TA的Attention Mask模式
但是,这种防泄漏的 Attention Mask 只能维持一层!也就是说即便这样做之后,
已经融入了第 i 个 token 的信息了,所以从第二层开始,如果你还是以第一层的输出为
,即便配合了上述 Attention Mask,也会出现信息泄漏了。
原论文的解决很粗暴,但貌似也只能这样解决了:每一层 Attention 都共用输入为
!所以,设
为 token 的 embedding 序列,
为对应的位置向量,那么 T-TA 与 BERT 的计算过程可以简写为:
当然残差、FFN 等细节已经省略掉了,只保留了核心运算部分,预训练阶段 T-TA 的 Attention 是进行了对角线形式的 Attention Mask 的,如果是下游任务的微调,则可以把它去掉。
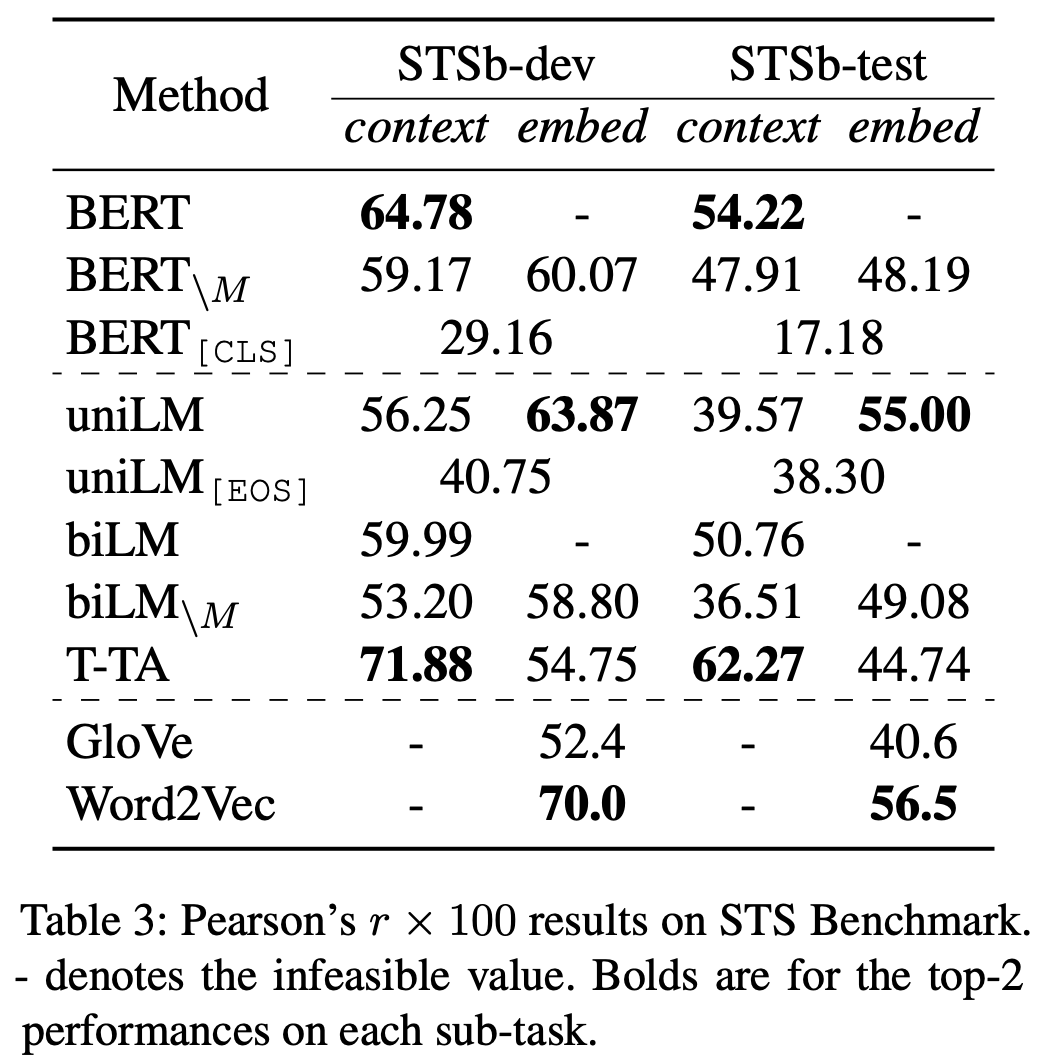
▲ 原论文的实验表格之一。可以看到T-TA在语义表达方面有它的独特优势。
基于上述设计,T-TA 它能一次性预测所有的 token,并且不需要额外的
符号,所以训练效率高,并且实现了预训练和微调之间的一致性(没有
)。
但是不难理解,T-TA 实则是对标准 Transformer 的一种简化,所以理论上它的拟合能力是变弱了。
这样一收一放之下,具体结果还有没有提升呢? 当然,论文的实验结果是有的。 原论文做了多个实验,结果显示 T-TA 这种设计在同样的参数情况下基本都能媲美甚至超过标准的 MLM 训练出来的模型。 作者还很慷慨地开源了代码,以便大家复现结果。
说到修改 Transformer 结构,大家可能联想到大量的 GPU、TPU 在并行运算。 但事实上,虽然作者没有具体列出自己的实验设备,但从论文可以看到设备阵容应该不算“豪华”。 为此,作者只训练了 3 层的 T-TA,并且按照同样的模式复现了 3 层的 MLM 和 GPT(也就是单向语言模型),然后对比了效果。
没错,论文中所有 T-TA 的结果都只是 3 层的模型,而其中有些都超过了 Base 版本的 BERT。
所以作者生动地给我们上了一课:
没有土豪的设备,也可以做修改 Transformer 的工作,也可以发ACL,关键是你有真正有效的 idea。
最后,再来简单谈谈 T-TA 为什么有效。读者可能会质疑,既然作者只做了 3 层的实验,那么如何保证在更多层的时候也能有效呢?那好,我们来从另外一个角度看这个模型。
从设计上看,对于 T-TA 来说,当输入给定后,
在所有 Attention 层中的保持不变,变化的只有
,所以读者质疑它效果也不意外。
但是别忘了,前段时候 Google 才提出了个 Synthesizer(参考 Google 新作Synthesizer:我们还不够了解自注意力 ),里边探索了几种 Attention 变种,其中一种简称为“R”的,相当于
固定为常数,结果居然也能 work 得不错!要注意,“R”里边的
是彻彻底底的常数,跟输入都没关系。
所以,既然
为常数效果都还可以,那么
为什么不能为常数呢?更何况 T-TA 的
动态依赖于输入的,只是输入确定后它才算是常数,因此理论上来讲 T-TA 的拟合能力比 Synthesizer 的“R”模型要强,既然“R”都能好了,T-TA 能好应该也是不奇怪。
[1] https://arxiv.org/abs/2005.07421
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读 ,也可以是学习心得 或技术干货 。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品 ,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱: hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」 也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」 订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」 ,小助手将把你带入 PaperWeekly 的交流群里。