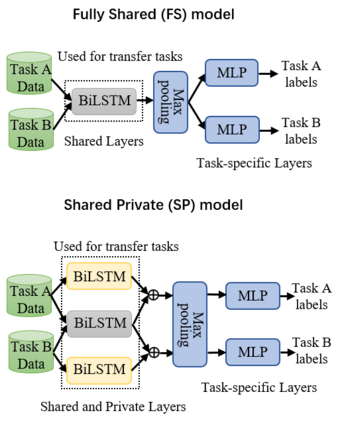
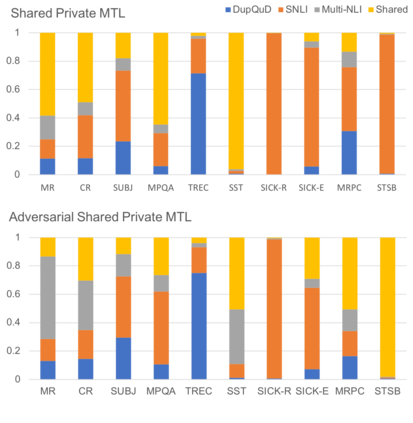
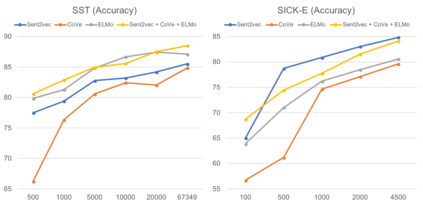
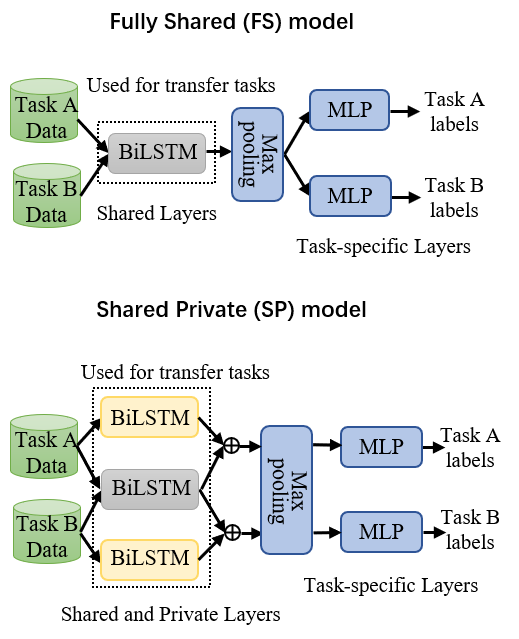
Learning distributed sentence representations is one of the key challenges in natural language processing. Previous work demonstrated that a recurrent neural network (RNNs) based sentence encoder trained on a large collection of annotated natural language inference data, is efficient in the transfer learning to facilitate other related tasks. In this paper, we show that joint learning of multiple tasks results in better generalizable sentence representations by conducting extensive experiments and analysis comparing the multi-task and single-task learned sentence encoders. The quantitative analysis using auxiliary tasks show that multi-task learning helps to embed better semantic information in the sentence representations compared to single-task learning. In addition, we compare multi-task sentence encoders with contextualized word representations and show that combining both of them can further boost the performance of transfer learning.
翻译:以往的工作表明,在大量收集自然语言附加说明的推论数据方面受过培训的经常性神经网络(RNN)句子编码器在转移学习方面十分有效,有助于其他相关任务。在本文中,我们表明,通过进行广泛的实验和分析,比较多任务和单任务已学习的句子编码器,共同学习多种任务,可以更普遍地表述句子。 利用辅助任务进行的定量分析表明,多任务学习有助于将更好的语义信息与单任务学习结合起来。 此外,我们将多任务判决编码器与背景化的字句表示法进行比较,并表明将两者结合起来可以进一步促进转移学习的绩效。