【泡泡一分钟】用于避障的基于地图的深度模仿学习
每天一分钟,带你读遍机器人顶级会议文章
标题:Map-based Deep Imitation Learning for Obstacle Avoidance
作者:Yuejiang Liu, An Xu, Zichong Chen
来源:2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
编译:王丹
审核:颜青松,陈世浪
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

对于计算资源有限的移动机器人来说,在向目标点前进的时候做出避障的最优决策是其面临的基本挑战之一。本文提出一种深度模仿学习算法,该算法基于以自我为中心的局部占用图来开发一种计算上有效的避障策略。嵌入价值迭代网络变量的训练模型能够通过快速前馈推理提供近乎最优的连续动作指令,并能很好地推广到基于计划的未知场景。为了提高政策的稳健性,我们增加了人工生成的地图的训练数据集,有效地缓解了正常演示中灾难性样本的不足。通过对Segway机器人的大量实验,证明了该方法在解的最优性、鲁棒性和计算时间等方面的有效性。
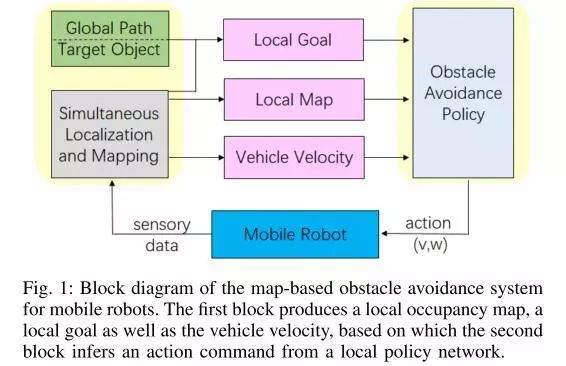
图1.基于地图的移动机器人避障系统框图。第一个块生成本地占用地图、本地目标和车辆速度,第二个块基于此从本地策略网络推断操作命令。
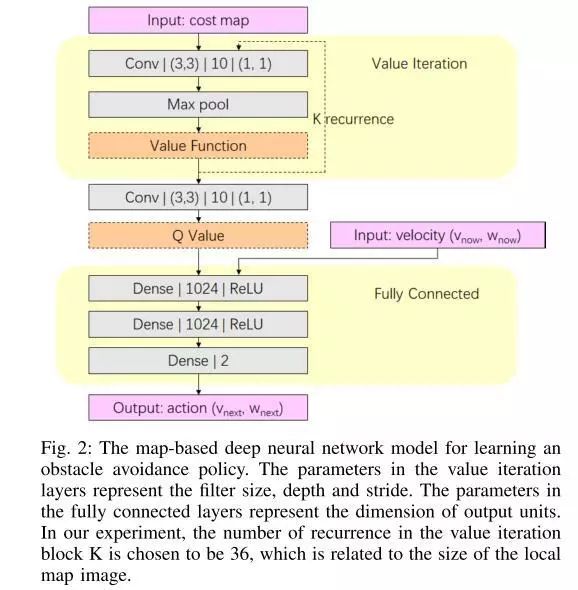
图2.基于地图的学习避障策略的深度神经网络模型。值迭代层中的参数表示filter大小、深度和步幅。全连接层中的参数表示输出单元的尺寸。在我们的实验中,k值迭代块的重复次数选择为36次,这与局部地图图像的大小有关。
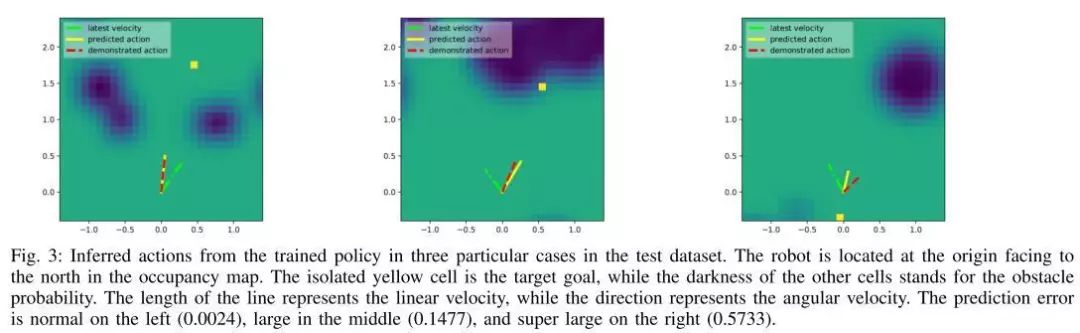
图3.在测试数据集中的三个特定情况下,从经过培训的策略推断出的操作。在占用地图中,机器人位于朝向北方的原点。隔离的黄色单元格是目标,而其他单元格的黑暗代表障碍概率。线的长度代表线速度,而方向代表角速度。预测误差在左侧为正态(0.0024),在中间为大(0.1477),在右侧为超大(0.5733)。
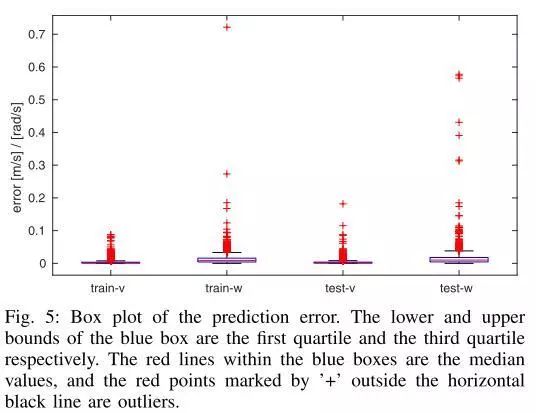
图5.预测误差的方框图。蓝框的下界和上界分别是第一个四分位数和第三个四分位数。蓝色框中的红线是中间值,水平黑线外用“+”标记的红点是离群值
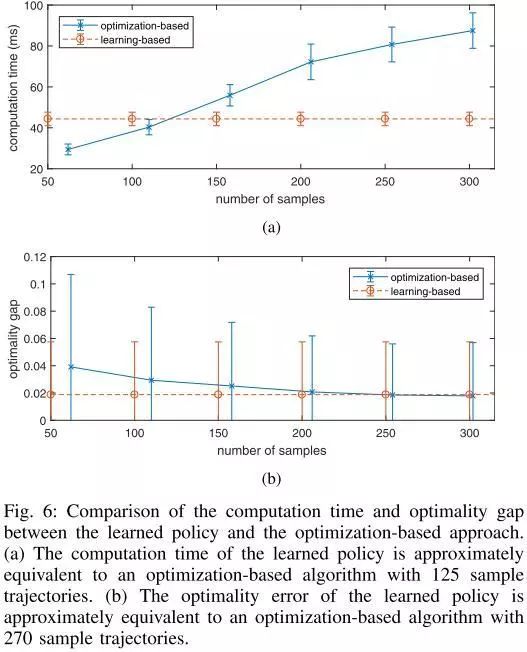
图6.比较学习策略和基于优化的方法的计算时间和最优性差距。(a)学习策略的计算时间近似等于基于优化的算法,具有125个样本轨迹。(b)所学策略的最优性误差近似等于270个样本轨迹的基于优化的算法。
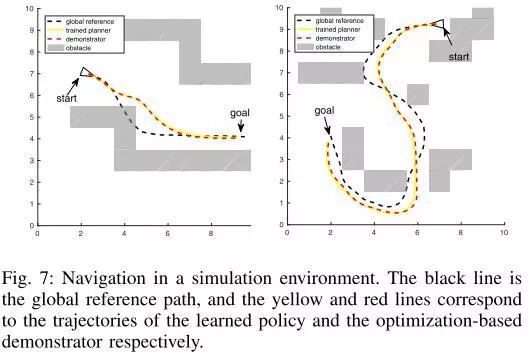
图7.在模拟环境中导航。黑线是全局参考路径,黄线和红线分别对应于学习策略和基于优化的演示器的轨迹。
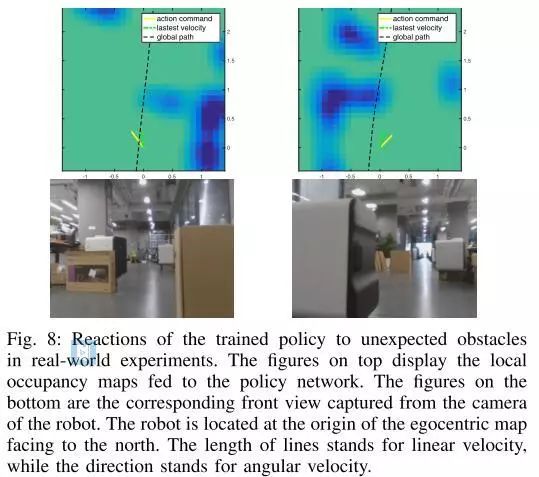
图8.训练政策对现实实验中意外障碍的反应。上面的数字显示了供给政策网络的本地占用地图。底部的数字是从机器人的摄像头捕捉到的相应的前视图。机器人位于面向北方的自心地图的原点。线的长度代表线速度,方向代表角速度。

图9.在真实办公环境中进行导航实验。机器人的任务是通过训练的策略在走廊中递归导航。占用地图的黑暗程度与障碍物概率成正比。

Abstract
Making an optimal decision to avoid obstacles while heading to the goal is one of the fundamental challenges for mobile robots equipped with limited computational resources. In this paper, we present a deep imitation learning algorithm that develops a computationally efficient obstacle avoidance policy based on egocentric local occupancy maps. The trained model embedded with a variant of the value iteration networks is able to provide near-optimal continuous action commands through fast feed-forward inferences and generalize well to unseen planning-based scenarios. To improve the policy robustness, we augment the training data set with artificially generated maps, which effectively alleviates the shortage of catastrophic samples in normal demonstrations. Extensive experiments on a Segway robot show the effectiveness of the proposed approach in terms of solution optimality, robustness as well as computation time.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号(paopaorobot_slam)。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/bbs/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com