重磅发布:基于 PyTorch 的深度文本匹配工具 MatchZoo-py

本文来自公众号“中国科学院网络数据重点实验室”,AI科技评论 获授权转载,如需转载,请联系中国科学院网络数据重点实验室。

MatchZoo 是由中科院计算所网络数据科学与技术重点实验室于 2017 年发布的一个深度文本匹配工具开源项目,可应用于文本检索、自动问答、复述问题、对话系统等多种应用任务场景。目前在 GitHub 平台上已获得将近 2600 Star,719 Fork,在深度文本匹配领域具有较大的影响力。
MatchZoo-py 是基于 PyTorch 框架,对 MatchZoo Keras 版本进行二次开发的新开源项目。借助 PyTorch 灵活性高,可扩展性强的特性,MatchZoo-py 在文本处理上具有更简洁的实现。使用 MatchZoo-py 框架,用户可以更加直观地了解深度文本匹配模型的设计、更加便利地比较不同模型的性能差异、更加快捷地开发新型的深度匹配模型。
MatchZoo-py 提供了基准数据集(WiKiQA、QuoraQP、SNLI 等数据集)进行模型开发与评估,实现了当前最流行的深度文本匹配方法(包括 DRMM,DSSM,CDSSM,ESIM,ARC-I,ARC-II,KNRM,ConvKNRM,BiMPM,MatchLSTM ,Bert 等算法),旨在为信息检索、数据挖掘、自然语言处理、机器学习等领域内的研究与从业人员提供便利。
同时,MatchZoo-py 整合了为 NLP 带来里程碑式改变的预训练模型 Bert,并提供了相应的使用指南。
MatchZoo-py v1.0 具有的新 Features 如下:
基于 PyTorch 框架进行开发,灵活性高,可扩展性强
整合预训练模型 Bert,可作为模型基础层使用,并提供使用指南
优化 Embedding 加载模块,支持 Word2vec,GloVe,fastText 等 Embedding
支持不同粒度(Character,N-gram,Word,Phrase 等)的 Embedding 输入
实现了大部分流行的深度匹配模型
支持动态 Padding,提高模型效率
自动检测 Task 中 Loss 和 Metric 的合法性
支持多线程 DataLoader
模型训练中支持自定义 Early stopping,clipping gradient norm,validation interval 以及自动保存最好模型
我们对比了多个模型,不同模型的性能如下所示,图 1 为不同模型在 WikiQA 训练数据集上的损失曲线,图 2 为不同模型在 WikiQA 测试数据集上的 NDCG@5 性能曲线,可以看到, MatchZoo-Py 可以复现 Keras 版本的性能,并且发现 Bert 取得了最好的性能。
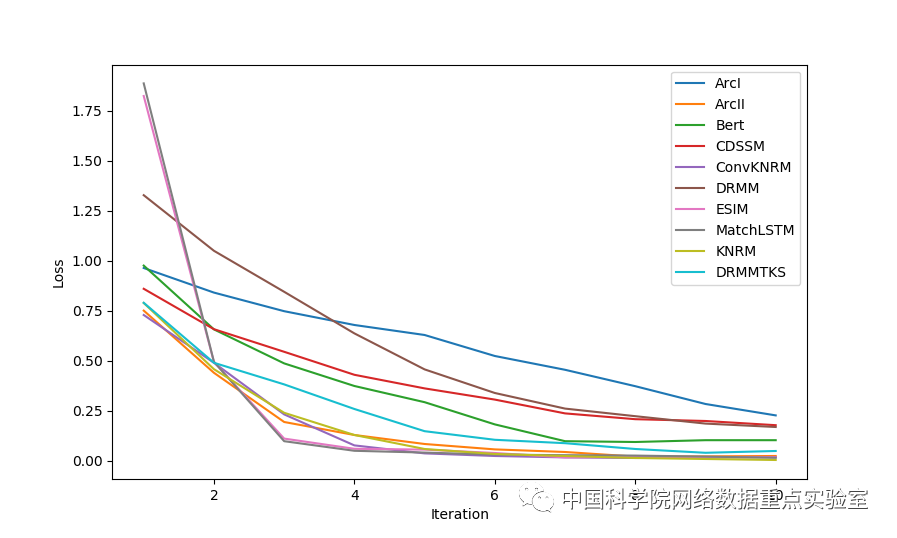
图 1 不同模型在训练集上的的 loss 曲线图
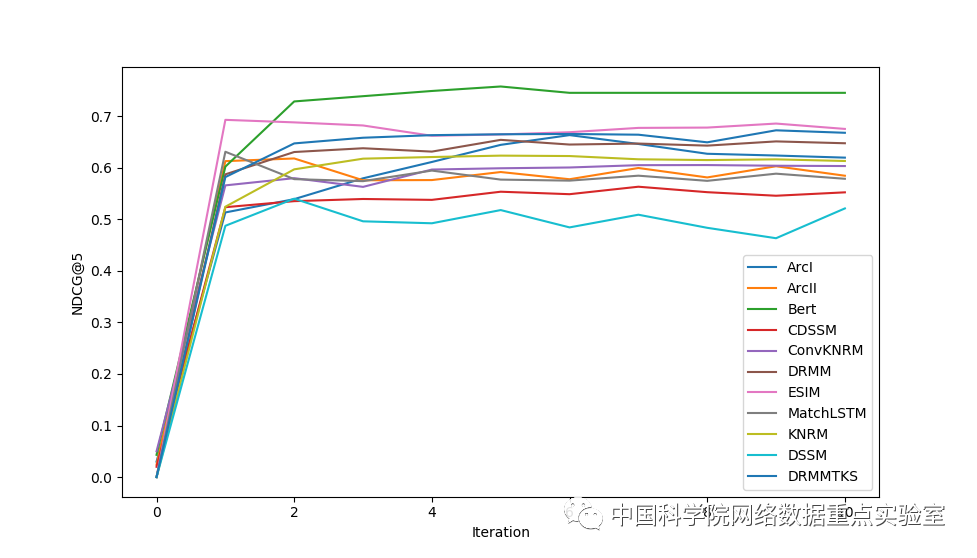
图 2 不同模型在测试集上的 NDCG@5 性能曲线图
作为一个开源项目,欢迎大家给我们提供宝贵的建议与意见,同时也欢迎大家申请加入我们的开发队伍。
项目地址:
https://github.com/NTMC-Community/MatchZoo-py


 点击
阅读原文
,查看:放大的艺术 | 基于深度学习的单图超分辨
点击
阅读原文
,查看:放大的艺术 | 基于深度学习的单图超分辨


