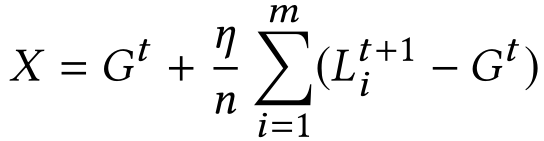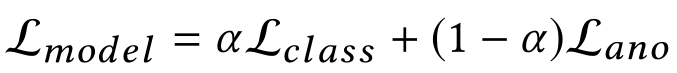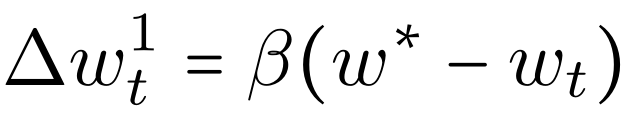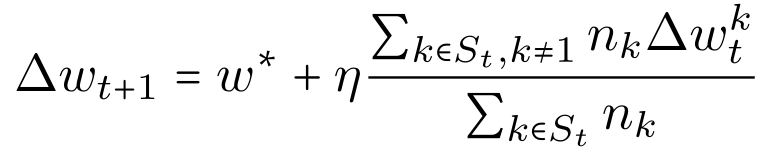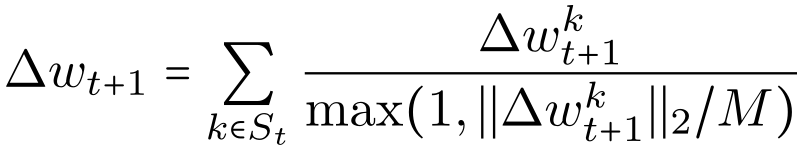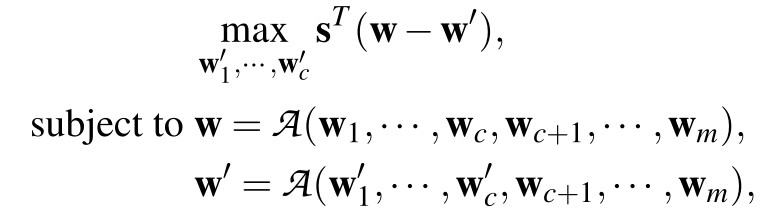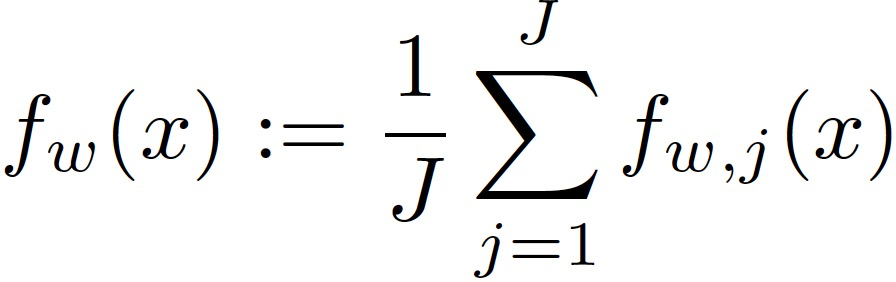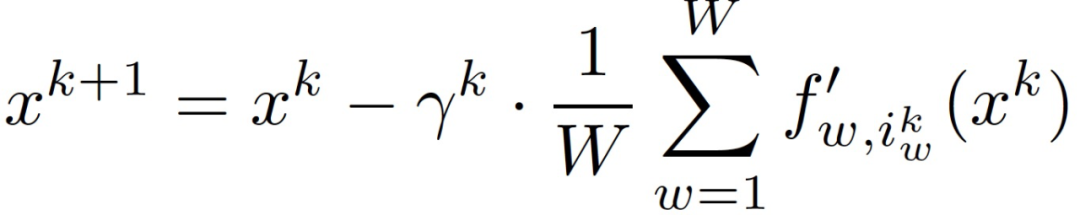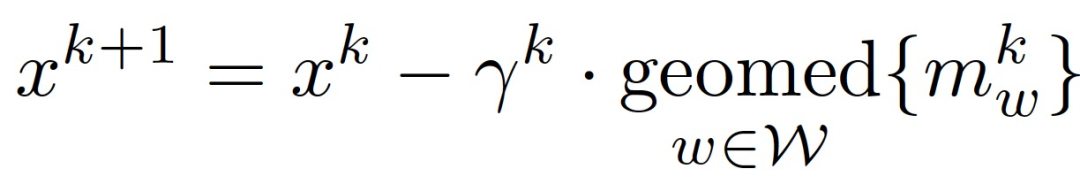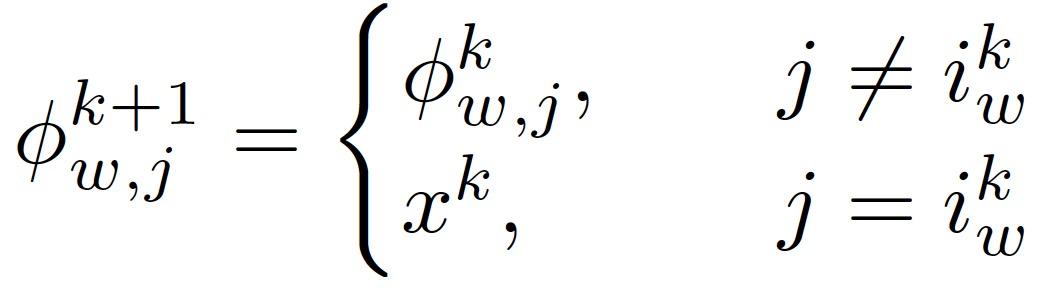随着联邦学习的推广应用,越来越多的研究人员聚焦于解决联邦学习框架中的模型攻击问题。我们从近两年公开的研究成果中选取了四篇文章进行详细分析,重点关注模型攻击类的鲁棒联邦学习(Robust Federated Learning)。
现代机器学习算法在实际应用场景中可能会受到各种对抗性攻击,包括数据和模型更新过程中中毒( Data and Model Update Poisoning)、模型规避(Model Evasion)、模型窃取(Model Stealing)和对用户的私人训练数据的数据推理性攻击(Data Inference Attacks)等等。在联邦学习的应用场景中,训练数据集被分散在多个客户端设备(如桌面、手机、IoT 设备)之间,这些设备可能属于不同的用户 / 组织。这些用户 / 组织虽然不想分享他们的本地训练数据集,但希望共同学习得到一个全局最优的机器学习模型。由于联邦学习框架的这种分布式性质,在使用安全聚合协议(Secure Aggregation)的情况下,针对机器学习算法的故障和攻击的检测纠正更加困难。
在联邦学习应用中根据攻击目标的不同,可以将对抗性攻击大致分为两类,即非定向攻击(Untargeted Attacks)和定向攻击(Targeted Attacks)。非定向攻击的目标是破坏模型,使其无法在主要任务中达到最佳性能。在定向攻击(通常被称为后门攻击(Backdoor Attacks))中,对手的目标是令模型在主要任务中保持良好的整体性能的同时在某些特定的子任务中表现出较差的性能。例如,在图像分类中,攻击者可能希望模型将某些 「绿色汽车」 误分类为鸟类,同时确保其能够正确分类其它汽车。由于非定向攻击会降低主要任务的整体性能,因此更容易被发现。由于对手的目标往往是事先不知道的,后门定向攻击则较难检测。
对于非定向攻击和定向攻击,可以根据攻击者的能力进一步将攻击分为两种类型:模型攻击(Model Attack)或数据攻击(Data Attack)。数据攻击是指攻击者可以改变所有训练样本中的一个子集,而这个子集对模型的学习者来说是未知的。模型攻击是指被攻击的客户端改变本地模型的更新,从而改变全局模型。特别的,当联邦学习框架中引入了安全聚合协议 (Secure Aggregation,SecAgg) 确保服务器无法检查每个用户的更新时,在本地更新的聚合中部署了安全聚合(SecAgg),模型攻击就更难对付了。关于安全聚合协议的解释,感兴趣的读者可阅读文献[1]。
在这篇文章中,我们重点聚焦模型攻击。在联邦学习应用框架中,恶意参与者(攻击者)直接破坏全局模型,因此比数据攻击的破坏性更大。在下文详细分析的文献《How To Backdoor Federated Learning》中提到:联邦学习中的任何参与者都可以用另一个模型替换全局模型,这导致 (i)新模型在联邦学习任务上是同样准确的,但是 (ii) 攻击者却能够控制模型在攻击者所选择的后门子任务上的表现。图 1 中给出了一种模型攻击的过程,攻击者控制联邦学习框架中的一个或多个参与者 / 客户端在后门数据上训练一个模型,将训练得到的结果模型提交给中央服务器,平均后的联合模型作为联邦学习的最终全局模型。
![]()
图 1:模型攻击概览《How To Backdoor Federated Learning》
随着联邦学习的推广应用,越来越多的研究人员聚焦于解决联邦学习框架中的模型攻击问题。我们从近两年公开的研究成果中选取了四篇文章进行详细分析,重点关注模型攻击类的鲁棒联邦学习(Robust Federated Learning)。
1. How To Backdoor Federated Learning
![]()
论文地址:https://arxiv.org/abs/1807.00459
本文是 Cornell Tech 研究团队贡献的一篇文章,首次公开于 2018 年,最新收录于 AISTATS'20。这篇文章也是帮助理解联邦学习模型在遭受恶意用户攻击前后所出现的变化情况的一篇重要文章。本文研究重点是:如何对联邦学习框架进行后门攻击?即,重点描述如何能够有效攻击的方法,而不是解决攻击的方法。本文的研究属于定向攻击(Targeted Attacks)和模型攻击(Model Attack)类别。
联邦学习通过将局部模型迭代聚合成一个联合全局模型,将深度神经网络的训练分布在 n 个参与者之间。在每一轮 t 迭代过程中,中央服务器随机选择 m 个参与者的子集 Sm,并向他们发送当前的联合模型 G^t。选中的参加者基于存储于本地客户端的私人数据训练得到新的本地模型 L^(t+1)。局部更新算法如下:
![]()
之后,客户端将差值 L^(t+1)-G^t 发送给中央服务器,中央服务器根据收到的信息更新计算全局联合模型:
![]()
在联邦学习架构中,各个客户端基于本地数据单独训练局部模型,这就给攻击者提供了一个脆弱的攻击面,局部的训练过程很有可能遭到攻击、破坏。特别是在数千个客户端的情况下,准确找出攻击者几乎是不可能的。此外,现有的联邦学习框架无法判断局部学习模型的正确性,客户端可以随意提交恶意模型,例如包含后门功能的模型。人们很难区分被后门攻击的模型和基于局部数据训练得到的真实模型。
攻击者。攻击模型中的攻击者不控制用于将参与者的更新组合到联合模型中的聚合算法,也不控制合法参与者训练的任何方面。本文假设攻击者通过将联合学习规定的训练算法正确地应用到他们的本地数据中来创建他们的本地模型。这种设置与传统的数据攻击的主要区别在于,数据攻击假定攻击者控制了相当一部分训练数据。相比之下,在模型攻击的联邦学习中,攻击者控制了整个训练过程,但只控制了一个或几个参与者。
攻击目标。攻击者希望通过联邦学习得到一个联合模型,该模型在其主任务和攻击者选择的后门子任务上都能实现高准确度,并且在攻击后的多轮攻击后,在后门子任务上保持高准确度。相比之下,传统的数据攻击旨在改变模型在大面积输入空间上的性能,而拜占庭攻击则旨在阻止全局(联合)模型收敛。一个安全漏洞即使不能每次都被利用,而且在被利用后一段时间内打上补丁,也是危险的。同样的道理,模型攻击有时会引入后门(即使有时会失败),只要模型至少在单轮中表现出高的后门准确率,那么模型攻击就是成功的。而在实际操作中,攻击的表现要好得多,后门一般都能够停留多轮。
语义后门(Semantic backdoors)。本文重点关注了语义后门。攻击者可自由选择 要么是物理场景中自然产生的特征(例如,某种汽车的颜色),要么是没有攻击者的情况下不可能出现的特征(例如,只有攻击者才有的特殊帽子或眼镜)。因此,攻击者可以选择后门是否由特定的、没有攻击者参与的场景下触发,或仅通过攻击者物理上修改的场景来出发。这两种类型的语义后门都能够造成模型基于未经修改的数字输入产生攻击者选择的输出。另一类后门攻击问题称为像素模式(pixel-pattern)。像素模式后门要求攻击者在测试时以特殊方式修改数字图像的像素,以便模型对修改后的图像进行错误分类。在一些应用场景下,这些后门攻击导致的问题比针对全局模型直接对抗式破坏的方式更加严重。
后门与对抗样本。对抗性转换利用模型对不同类的表示方式之间的界限,来产生被模型错误分类的输入。相比之下,后门攻击则故意改变这些边界,使某些输入被错误分类。像素模式后门攻击严格来说比对抗性转换要弱:攻击者必须在训练时对模型攻击,而在测试时修改输入。如果规模化部署联邦学习模型,语义后门可能比对抗性转换更危险。
基线攻击。攻击者只在后门输入上训练其模型。解决这一问题的最简单的办法就是在每个训练批次中尽量包括正确标记的输入和后门输入的混合,以帮助模型学习识别二者的差异。这种简单的基线攻击在实际应用中效果很差,中央服务器的聚合操作抵消了后门模型的大部分贡献,这造成全局模型很快就忘记了后门攻击的存在。必须要在模型的更新过程中不断地重新选择攻击者,即便如此,最终的攻击效果仍然不理想。
模型替换攻击。首先,作者对本文描述的攻击进行数学分析,攻击者试图用恶意的全局模型 X 代替新的全局模型 G^(t+1):
![]()
考虑到本地客户端中数据与全局数据的非独立同分布问题(Non-IID),每个本地模型可能远离目前的全局模型。当全局模型收敛时,这些偏差开始抵消。因此,攻击者按照下式处理拟提交的模型:
![]()
这种攻击将后门模型 X 的权重缩放为γ=n/η,以确保后门在平均化中能够存活,最终导致全局模型被 X 取代。一个不知道 n 和η的攻击者,可以通过每轮迭代增加并测量模型在后门任务上的准确度,来近似缩放系数γ。在一些联邦学习框架中,参与者会对模型权重应用随机掩码。攻击者既可以跳过这一步,直接发送整个模型,也可以应用一个掩码,只删除接近于零的权重。上述模型替换操作确保了攻击者的贡献能够存活下来,并被转移到全局模型中。这是一种单次性(single-shot attack)的攻击:全局模型在后门任务上表现出了高准确度,而后门任务被杀死后,全局模型立即表现出高准确度。
由于攻击者可能只被选择进行单轮训练,因此攻击者希望的是后门在替换模型后尽可能多地保留在模型中——防止后门被全局模型遗忘。本文提出的攻击实际上是一种双任务学习,即全局模型在正常训练时学习主任务,而后门任务只在攻击者被选中的回合中学习主任务。该双任务学习的目标是在攻击者的回合后仍然保持这两个任务学习的高准确率。
在最新提出的联邦学习框架中建议使用安全聚合协议。该协议可以阻止中央服务器中的聚合器检查参与者提交的模型。有了安全聚合,就无法检测到聚合中是否包含了恶意模型,也无法检测到谁提交了这个模型。如果没有安全聚合,聚合参与者模型的中央服务器可能会试图过滤掉 「异常」 贡献。由于攻击者创建的模型权重被显著地放大,这样的模型很容易被检测和过滤掉。然而,联邦学习的主要动机是利用参与者的多样性,即使用分布在各个客户端中的非独立同分布(Non-IID)的训练数据,包括不正常或低质量的本地数据,如智能手机照片或短信历史记录等。因此,中央服务器的聚合器应该接受,即便是准确度较低或者与当前全局模型有明显偏离的局部模型。
本文作者给出了名为「限制—缩放」(「constrain-and-scale」)的通用方法,使攻击者能够产生一个在主任务和后门任务上都有很高的准确度、但又不被中央服务器异常检测器拒绝的模型。论文通过使用一个目标函数将规避异常检测的行为纳入训练中,该目标函数:(1)对模型的准确性进行奖励,(2)对偏离中央服务器的聚合器认为 「正常」 的模型进行惩罚。完整算法如下:
![]()
通过添加异常检测项 L_ano 来修改目标(损失)函数:
![]()
攻击者的训练数据同时包括正常输入和后门输入,因此 L_class 能够同时兼顾主要任务和后门任务的准确性。L_ano 可以是任何类型的异常检测,例如权重矩阵之间的 p 范数距离或更高级的权重可塑性惩罚。超参数α控制回避异常检测的重要程度。
训练并缩放处理(training-and-scale):对于只考虑模型权重大小的异常检测器(例如,欧氏距离),可以用较简单的技术来规避。攻击者训练后门模型直至收敛,然后将模型的权重进行缩放,使之达到异常检测器所允许的边界 S。缩放比例为:
![]()
对付简单的基于权重的异常检测器,训练并缩放(training-and-scale)的效果比约束并缩放(constrained-and-scale)更好,因为无约束训练增加了对后门精度影响最大的权重,从而使训练后的缩放变得不那么重要。对付更复杂的防御措施,约束和比例训练会带来更高的后门准确度。
作者使用图像分类和单词预测任务验证后门攻击的效果。实验中,将经典的数据中毒(直接针对数据攻击)的方法作为基线对比方法。在图像分类任务中,作者使用的是 CIFAR-10 数据库,并训练了一个具有 100 名参与者的全局模型,其中每轮随机选择 10 名参与者,使用具有 270 万个参数的轻量级 ResNet18 CNN 模型。为了模拟 Non-IID 训练数据并为每个参与者提供不平衡样本,使用 Dirichlet 分布和超参数 0.9 划分了 50,000 个训练图像。轮训中选择的每个参与者进行 2 个局部时期的学习,学习速率为 0.1。实验中选择了三个功能作为后门:绿色汽车(CIFAR 数据集中的 30 个图像),具有赛车条纹的汽车(21 个图像)和背景中具有垂直条纹的墙壁的汽车(12 个图像),如图 2(a)。在训练攻击者的模型时,在每个训练批次中将后门图像与正常图像混合(每批大小为 64 的情况下 c=20 个后门图像)。
![]()
图 2:语义后门示例。(a):图像的语义后门(具有某些属性的汽车被归类为鸟类);(b):单词预测后门(触发语句以攻击者选择的目标单词结尾)
字词预测是非常适合联邦学习的任务,因为训练数据(例如,用户在手机上键入的内容)无法进行集中式收集。它也是 NLP 任务(例如问题解答,翻译和摘要)的代理。使用 PyTorch 单词预测示例代码,该模型是一个 2 层 LSTM,具有 1000 万个参数,该参数在公开 Reddit 数据集中随机选择的一个月(2017 年 11 月)上进行了训练。假设每个 Reddit 用户都是联邦学习的独立参与者,并且要确保每个用户有足够的数据,筛选出少于 150 个或 500 个以上帖子的用户,总共 83,293 名参与者,平均每个人拥有 247 个帖子。将每个帖子视为训练数据中的一句话,将单词限制为数据集中 50K 个最常用单词的字典,每轮随机选择 100 名参与者。攻击者希望模型在用户键入特定句子的开头时预测攻击者选择的单词,如图 2(b)。图 3 给出了单词预测后门的修正损失。其中,图 3(a)为标准单词预测:在每个输出上计算损失;图 3(b)后门单词预测:攻击者用触发语句和选择的最后一个单词替换输入序列的后缀。损失仅在最后一个单词上计算。
![]()
图 4 给出了图像分类和单词预测任务的后门攻击准确度结果。图 4(a)和 4(c)显示了单发攻击的结果,其中在攻击之前的 5 个回合和之后的 95 个回合中,在一个回合中选择了一个由攻击者控制的参与者。攻击者提交他的更新后,后门任务上全局模型的准确度立即达到近 100%,然后逐渐降低。图 4(b)和 4(d)给出了重复攻击情况下的平均成功率。本文提出的攻击方法比基线的数据中毒方法获得更高的准确度。对于 CIFAR(图 4(b)),控制 1%参与者的攻击者与控制 20%数据中毒的攻击者具有相同的(高)后门准确性。对于单词预测(图 4(d)),控制 0.01%的参与者能够达到 50%的平均后门准确性(单词预测的最大准确性通常为 20%)。
![]()
图 4:后门准确度,a + b:带有语义后门的 CIFAR 分类;c + d:带有语义后门的单词预测。a + c:单发攻击;b + d:反复攻击
本文确定并评估了联邦学习中的一个漏洞:通过模型平均,联邦学习使得成千上万的参与者能够对最终学习的全局模型的权重产生直接影响,其中有些参与者不可避免地是恶意的。这使得恶意参与者能够将后门子任务引入联邦学习中。本文提出了一种新的模型攻击方法 --- 模型替换方法,该方法利用了联邦学习的这一漏洞,作者在标准的联邦学习任务上证明了其有效性,包括图像分类和单词预测。此外,现代深度学习模型都具有强大的学习功能。因此,传统的通过衡量模型质量来判断是否存在后门攻击的方法不再适用。深度模型不强调对主要任务的了解和适合,其强大的学习容量可以引入隐蔽的后门,而不会严重影响模型的准确性。
联邦学习不仅仅是标准机器学习的分布式版本。它是一个分布式系统,因此必须对任何行为不当的参与者都具有较强的鲁棒性。当参与者的训练数据不是独立同分布时,现有的用于拜占庭容忍的分布式学习技术都不再适用。如何设计强大的联邦学习系统或架构是未来研究的重要课题。
2. Can You Really Backdoor Federated Learning?
![]()
论文地址:https://arxiv.org/abs/1911.07963
本文是 Google 的一篇关于联邦学习后门攻击问题的文章,其中第一作者来自于 Cornell 大学。文章发表于 NeurIPS 2019。本文重点讨论联邦学习中的后门攻击,目的是降低模型在目标子任务上的性能,同时在联邦学习的主要任务上保持良好的性能。本文的研究也属于定向攻击(Targeted Attacks)和模型攻击(Model Attack)类别。与上一篇文章所讨论的问题不同的是,本文的方法允许非恶意的客户端在目标任务中正确标注样本。
令 K 为联邦学习网络中的客户端总数。在每个更新回合回合 t,中央服务器随机选择 C⋅K 个客户端,C <1。令 S_t 为该客户端集合,n_k 为客户端 k 中的样本数,用 w_t 表示第 t 轮时的模型参数。每个被中央服务器选定的客户端都会计算模型更新,用Δ(w_t)^k 表示,中央服务器汇总各个客户端的Δ(w_t)^k:
![]()
对手采样。如果客户端的比例ε完全被泄露,那么每一轮可能包含 0 到 min(ε ⋅K, C ⋅K)之间的任何对手。在对客户端进行随机抽样的情况下,每轮中的对手数量遵循超几何分布。作者将此攻击模型称为随机抽样攻击(random sampling attack)。作者在本文中考虑的另一个模型是固定频率攻击(fixed frequency attack),即每 f 轮中就会出现一个对手。为了公平的比较这两种攻击模型,作者将频率设置为与攻击者总数成反比(即 f = 1 /(ε ⋅C⋅K))。
后门任务。在后门任务中,对手的目标是确保模型在某些目标任务上失败,此外,允许非恶意客户从目标后门任务中正确标记样本。作者在本文中通过对来自多个选定的 「目标客户」 的示例进行分组来形成后门任务。由于来自不同目标客户端的示例遵循不同的分布,因此将目标客户端的数量称为「后门任务数量」,并探讨其对攻击成功率的影响。直观地讲,拥有的后门任务越多,攻击者试图破坏的特征空间就越大,因此,攻击者在不破坏模型在主要任务上的性能的情况下成功地对其后门进行攻击的难度就越大。
如果在第 t 轮中仅选择了一个攻击者(假定它是客户端 1),则攻击者尝试通过发送后门模型 w* 来替换整个模型:
![]()
![]()
如果假设模型已经充分收敛,那么它将在 w* 的一个小邻域内,此时其他更新∆(w_t)^k 的值也很小。为了得到 w* 的后门模型,假设攻击者拥有描述后门任务的集合 D_mal。同时,还假设攻击者具有一组从真实分布 D_trn 生成的训练样本。不过,在真实应用场景中,攻击者很难获得这样的数据。
在无约束的加速后门攻击场景下,对手在没有任何约束的情况下根据 w_t,D_mal 和 D_trn 训练得到了模型 w*。常用的训练策略是用 w_t 初始化 D_trn∪D_mal 训练模型。
在范数约束后门攻击的应用场景下,每回合,模型在模型更新小于 M /β的约束下进行后门任务训练。因此,模型更新在以因子β增强后,其范数为 M。这可以通过使用多轮预测的梯度下降训练模型来实现,在每一轮中,使用无约束的训练策略训练模型,然后将其投影回 w_t 大小为 M /β周围的 L2 球面中。
范数阈值更新(Norm thresholding of updates)。由于增强型攻击可能会产生具有较大范数的更新,因此合理的防御措施是让中央服务器简单地忽略范数超过某个阈值 M 的更新;在更复杂的方案中,甚至可以以随机方式选择 M。假定对手知道阈值 M,因此它可以始终返回此阈值范围内的恶意更新。假定对手确实已知阈值,此时范数约束防御如下:
![]()
此模型更新可确保每个模型更新的范数较小,因此对中央服务器的影响较小。
(弱)差异性隐私((Weak) differential privacy)。防御后门任务的一种数学严格方法是训练具有差分隐私的模型,具体的可以通过裁减更新、附加高斯噪声来实现。对于攻击任务来说,一般为获得合理的差别隐私而增加的噪声量相对较大。由于本小节讨论的目标不是隐私,而是防止攻击,因此只添加少量的噪声,这些噪声在经验上足以限制攻击的成功。
本文在 EMNIST 数据库中完成后门攻击实验。该数据库是从 3383 位用户收集的带有注释的手写数字分类数据库,其中,每位用户大约有 100 张数字图像。他们每个人都有自己独特的写作风格。使用 TensorFlow Federated 框架中的联合学习来训练具有两个卷积层、一个最大池化层和两个密集层的五层卷积神经网络。每轮训练选择 C⋅K = 30 个客户。在实验中,将后门任务视为从多个选定的 「目标客户」 中选取 7s 作为 1s 进行分类。
首先,针对两种攻击模型进行实验,结果见图 1(无约束的加速后门)和图 2(范数约束后门攻击)。这些图表明,尽管固定频率攻击比随机采样攻击更有效,但两种攻击模型都有相似的行为。此外,在固定频率攻击中,更容易查看攻击是否发生在特定回合中。
![]()
图 1:针对攻击者不同比例的固定频率攻击(左列)和随机采样攻击(右列)的无限制攻击,其中,绿线是后门准确度的累积平均值
![]()
图 2:对于攻击者所占比例不同的固定频率攻击(左列)和随机采样攻击(右列),范数为 10 的范数约束攻击,其中,绿线是后门准确度的累积平均值
![]()
图 3:范数边界和高斯噪声的影响。点:主要任务;实线:后门任务
在图 3(a)中,考虑了每个用户的范数阈值更新。假设每一轮出现一名攻击者,对应于ε = 3.3%的被破坏的客户端,范数边界为 3、5 和 10(大多数回合中 90%的正常客户端的更新低于 2),这意味着在提升之前更新的范数阈值为 0.1、0.17、0.33。从图中可以看出,选择 3 作为范数阈值能够成功缓解攻击,而对主要任务的性能几乎没有影响。因此,作者认为,范数阈值可能是当前后门攻击的有效防御措施。在图 4(b)的实验中,作者在范数阈值中加上了高斯噪声。从图中可以看出,添加高斯噪声还可以帮助减轻攻击,而不会超出常规限幅,且不会严重损害整体性能。
本文证明了在没有任何防御的情况下,对手的表现在很大程度上取决于在场的对手所占的比例。因此,要想攻击成功,就需要有大量的对手存在。
在范数约束的情况下,多次迭代的 「预增强的」 映射梯度下降并不是有效的单轮攻击防御手段。事实上,对手可能会尝试直接制作满足范数约束的 「最坏情况」 的模型更新。此外,如果攻击者知道他们可以在多轮攻击中进行攻击,那么在范数约束下可能会存在更好的防御策略值得进一步研究。可能影响后门攻击性能的另一个因素是模型容量,特别是猜测后门攻击会利用深度网络的备用容量。模型能力如何与后门攻击相互作用是一个有趣的问题,需要进一步从理论和实践角度来考虑。
3. Local Model Poisoning Attacks to Byzantine-Robust Federated Learning
![]()
论文地址:https://arxiv.org/abs/1911.11815
本文是 Duke 大学 Gong Zhenqiang 教授组的一篇文章,发表在 USENIX Security Symposium 2020,重点讨论如何在拜占庭鲁棒的联邦学习方法中制造有效的模型攻击。该研究的具体内容属于模型攻击(Model Attack)类问题。经典的联邦学习数据中毒攻击(Data Poisoning Attacks)主要是通过攻击者破坏受其控制的客户端中的局部 / 本地数据来实现的。这种攻击对于拜占庭鲁棒的联邦学习是无效的。本文是首次针对具有拜占庭鲁棒性的联邦学习进行的局部模型中毒攻击(Local Model Poisoning Attacks)研究,其目标是在训练阶段破坏学习过程的完整性,如图 1 所示。
![]()
假设攻击者入侵了一些客户端设备,在学习过程中,攻击者在这些被入侵的设备上控制并更改本地模型参数,从而提高了全局模型的测试误差率。本文将所提出的攻击方法应用到了最新的四种拜占庭鲁棒的联邦学习方法中,这些方法应用了包括 Krum ,Bulyan,修整均值和中位数的聚合规则。这四种方法都声称对拜占庭攻击具有鲁棒性,而本文的分析和实验数据表明,使用本文所提出的攻击方法能够大幅提高这四种方法学习到的全局模型的错误率。
能够成功实现局部模型中毒攻击的关键是要将已中毒、被破坏的工作节点设备的局部模型发送到主设备。为了解决这一问题,作者将局部模型的建立视为解决联邦学习的每一次迭代中的优化问题。具体来说,如果不存在攻击,则主设备可以在迭代中计算得到全局模型,将这一模型称为「攻击前全局模型」。而当存在本文所提出的攻击时,该攻击方法会在受影响的工作节点设备上建立局部模型,使全局模型在与攻击前全局模型变化方向的反方向上具有最大偏差。作者认为,在多次迭代中积累的偏差会使学习到的全局模型与攻击前的模型有明显的差异,从而实现有效攻击。
最后,本文还讨论了如何针对该攻击进行有效防御。作者对两种经典的针对数据中毒攻击的防御方法进行了归纳,以防御本文提出的局部模型中毒攻击。实验结果表明,在某些情况下,其中一种防御方法可以有效地防御本文的攻击,但在其他情况下,这两种防御方法都是无效的。
本文所提出的攻击方法的目标是在受影响的工作节点设备上建立局部模型,使全局模型在与攻击前全局模型变化方向的反方向上具有最大偏差。作者认为,在多次迭代中积累的偏差会使学习到的全局模型与攻击前的模型有明显的差异。最后,本文还讨论了如何针对该攻击进行有效防御。作者对两种经典的针对数据中毒攻击的防御方法进行了归纳,以防御本文提出的局部模型中毒攻击。实验结果表明,在某些情况下,其中一种防御方法可以有效地防御本文的攻击,但在其他情况下,这两种防御方法都是无效的。
联邦学习架构主要包括三个工作流程:主设备(中央服务器)将当前的全局模型发送给工作节点设备(各个客户端);工作节点设备利用本地训练数据集和全局模型更新本地模型,并将本地模型发送给主设备;主设备根据一定的聚合规则,通过聚合本地模型计算出新的全局模型。例如,以局部模型参数的平均值作为全局模型的均值聚合规则(Mean Aggregation Rule),在非对抗性设置下被广泛使用。但是,即使只破坏了一个工作器设备,也可以任意操纵全局模型的均值。因此,机器学习社区最近提出了多个聚合规则(例如,Krum ,Bulyan,修整均值和中位数),目的是针对某些特定的工作节点设备的拜占庭式故障提供鲁棒性。
Krum 和 Bulyan。Krum 在 m 个局部模型中选择一个与其他模型相似的模型作为全局模型。Krum 的想法是即使所选择的局部模型来自受破坏的工作节点设备,其能够产生的影响也会受到限制,因为它与其他可能的正常工作节点设备的局部模型相似。Bulyan 本质上是 Krum 和修整均值的变体结合。Bulyan 首先迭代应用 Krum 来选择θ(θ≤m-2c)局部模型。然后,Bulyan 使用修整均值的变体汇总θ个局部模型。Bulyan 在每次迭代中多次执行 Krum,并且 Krum 计算局部模型之间的成对距离,因此,Bulyan 是不可扩展的。本文中重点介绍 Krum。
修整均值(Trimmed mean)。该聚集规则独立地聚集每个模型参数。具体地,对于每个第 j 个模型参数,主设备对 m 个局部模型的第 j 个参数进行排序。删除其中最大和最小的β个参数,计算其余 m-2β个参数的平均值作为全局模型的第 j 个参数。
中位数(Median)。在中位数聚合规则中,对于第 j 个模型参数,主设备都会对 m 个局部模型的第 j 个参数进行排序,并将中位数作为全局模型的第 j 个参数。当 m 为偶数时,中位数是中间两个参数的均值。与修整均值聚集规则一样,当目标函数为强凸时,中位数聚集规则也能达到阶优误差率。
背景:假设攻击者控制了 c 工作节点设备。攻击者的目标是操纵学习到的全局模型,以使其在测试示例时不加选择地都具有较高的错误率,即非定向攻击(Untargeted Attacks),它使学习的模型不可用,并最终导致拒绝服务攻击。
上面讨论的拜占庭鲁棒聚集规则可以在目标函数的某些假设下,渐近地限制学习的全局模型的错误率,并且其中一些(即修整后的均值和中位数)甚至可以实现阶数最优的错误率。这些理论上的保证似乎强调了操纵错误率的困难。但是,渐近保证不能准确地表征学习模型的实际性能。尽管这些渐近错误率对于局部模型中毒攻击仍然有效,因为它们对于拜占庭式失败也有效,在实践中,本文提出的攻击仍可以显着提高学习模型的测试错误率。攻击者能够掌握被破坏的工作节点设备上的代码、本地局部训练数据集和局部模型、聚合规则等。
优化问题:攻击者的目标(本文称其为有向偏离目标)是使全局模型参数最大程度地偏离全局模型参数在没有攻击的情况下沿其变化的方向的反方向。假设在迭代中,w_i 是使用第 i 个工作节点设备计划在没有攻击时发送给主设备的局部模型。假定前 c 个工作节点设备受到了破坏。有向偏差目标是通过在每次迭代中解决以下优化问题,为受损的工作节点设备制作局部模型:
![]()
其中 s 是所有全局模型参数变化方向的列向量,w 是攻击前全局模型,w’是攻击后全局模型。
攻击 Krum:假定 w 为没有攻击情况下的选定的局部工作节点设备。目标是制作 c 个折衷的局部模型,以使 Krum 选择的局部模型与 w 的最大有向偏差。因此,目标是解决公式(1)中 w’ = w’_1 的优化问题,并且聚合规则为 Krum。
在掌握全面知识的情况下,解决优化问题的关键挑战是优化问题的约束是高度非线性的,并且局部模型的搜索空间非常大。作者提出下面两个假设。首先,将 w’_1 限制如下:w’_1=w_Re-λs,其中 w_Re 是当前迭代中从主设备接收的全局模型(即上一次迭代中获得的全局模型),并且λ> 0。其次,为使 w_1 更有可能被 Krum 选择,将其他 c-1 折衷的局部模型设计为接近 w’_1。基于这两个假设,将优化问题转换如下:
![]()
在掌握部分知识的情况下,攻击者不知道正常工作节点设备上的局部模型,也就无法掌握方向 s 的变化,也无法解决优化问题。但是,攻击者可以访问受到攻击的 c 个设备上的攻击前局部模型。因此,需要根据这些攻击前的局部模型来设计折衷的局部模型。首先,计算 c 个攻击前局部模型的均值。其次,使用平均局部模型估算变化方向。第三,将受攻击的工作节点设备上的攻击前局部模型视为是正常工作节点设备上的局部模型,目标是在生成的局部模型和 c 攻击前局部模型中找到局部模型 w’_1。此时,优化问题如下:
![]()
修整均值攻击:假设 w_i 在第 i 个工作节点设备上是第 j 个攻击前局部模型参数,而在当前迭代中是第 j 个攻击前全局模型参数。
在掌握全局知识的情况下,从理论上讲,可以证明以下攻击可以使全局模型的有向偏差最大化。本文的攻击会根据最大或最小正常局部模型参数来设计折衷的局部模型,具体取决于哪个参数会使全局模型朝着没有攻击的情况下更改全局模型的方向的反方向偏离。采样的 c 数目应接近 w_(max,j) 或 w_(min,j),以避免离群和易于检测。在实施攻击时,如果 s_j = -1,那么将在间隔 [w_(max,j) ,b·w_(max,j) ] 中随机采样 c 个数字,否则,将以[w_(min,j)/ b, w_(min,j)] 间隔对 c 个数字进行随机采样。
在掌握部分知识的情况下,攻击者面临两个挑战。首先,攻击者不知道变化的方向变量,因为不知道正常工作节点设备上的局部模型。其次,出于相同的原因,攻击者不知道最初的正常局部模型的最大 w_(max,j),最小 w_(min,j)。为了解决第一个挑战,使用受破坏的工作节点设备上的局部模型来估算变化方向的变量。解决第二个挑战的一种简单策略是使用非常大的 w_(max,j),或使用非常小的 w_(min,j)。如果基于 w_(max,j)、w_(min,j)来设计折衷的局部模型,而这些模型与真实值相差甚远,那么生成的局部模型可能会是异常值,并且主设备可能会容易地检测到折衷的局部模型。
中位数攻击:采用与修整均值攻击同样的攻击策略来进行中值攻击。例如,在完全知识方案中,如果 s_j=-1,随机抽取区间 [w_(max,j) ,b·w_(max,j)] 或[w_(max,j) ,w_(max,j)/b]中的 c 数;否则随机抽取区间 [w_(min,j)/ b, w_(min,j)] 或[b·w_(min,j), w_(min,j)]中的 c 数。
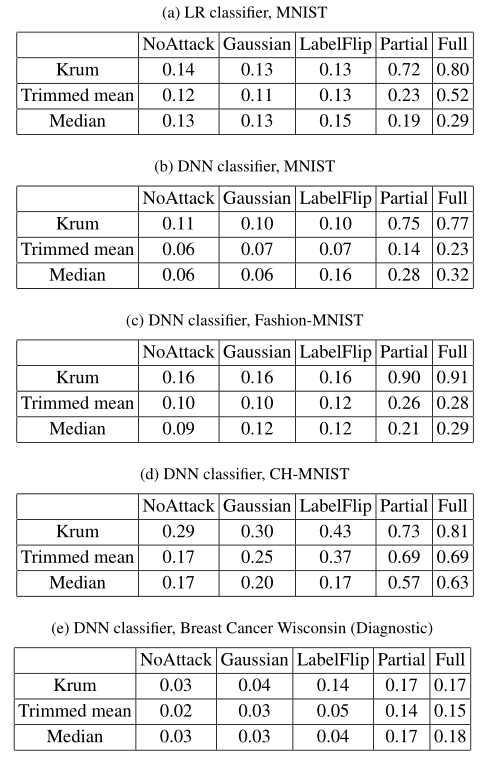
本文在四个数据库中进行实验:MNIST,FashionMNIST,CH-MNIST 和 Breast Cancer Wisconsin(诊断)数据库。MNIST 和 Fashion-MNIST 分别包含 60,000 个训练示例和 10,000 个测试示例,其中每个示例都是 28×28 灰度图像。这两个数据集都是 10 类分类问题。CH-MNIST 数据库包含来自结肠直肠癌患者的 5000 张组织切片图像。数据库是一个 8 类分类问题。每个图像具有 64×64 灰度像素。我们随机选择 4000 张图像作为训练示例,其余 1000 张作为测试示例。Breast Cancer Wisconsin(诊断)数据库是诊断人是否患有乳腺癌的二元分类问题。该数据集包含 569 个示例,每个示例都有 30 个描述一个人细胞核特征的特征。随机选择 455 个(80%)示例作为训练示例,并使用其余 114 个示例作为测试示例。
联邦学习架构中考虑的分类方法包括:多类逻辑回归(Multi-class logistic regression,LR)、深度神经网络(Deep neural networks ,DNN)。本文采用的攻击对比基线方法包括:高斯攻击(Gaussian attack)、标签翻转攻击(Label flipping attack)、基于反向梯度优化的攻击(Back-gradient optimization based attack)、全部知识攻击或部分知识攻击(Full knowledge attack or partial knowledge attack)。
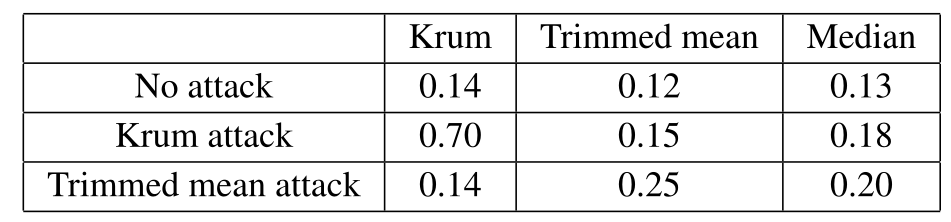
![]()
表 1 显示了在四个数据库上进行比较的攻击的测试错误率。首先,这些结果表明我们的攻击是有效的,并且大大优于现有的攻击。其次,除了在 Breast Cancer Wisconsin(诊断)数据库上,Krum 与中位数攻击的效果相当之外,Krum 对本文的攻击的鲁棒性不如均值和中位数高。
![]()
图 2:测试 MNIST 数据库中不同攻击的错误率,(a)-(c):LR 分类器,(d)-(f):DNN 分类器
图 2 给出了随着 MNIST 上受到破坏的工作节点设备的百分比增加,不同攻击的错误率。随着受到破坏的工作节点设备数量的增加,本文的攻击会大大提高错误率。作为基线对比的标签翻转攻击只会稍微增加错误率,而高斯攻击则对错误率没有产生明显的影响。图 2 的实验中有两个例外是,当被破坏的工作人员设备的百分比从图 2a 中的 5%增加到 10%,以及,从图 2d 中的 10%增加到 15%时,Krum 的错误率降低。作者分析,这可能是因为 Krum 每次迭代都会选择一个局部模型作为全局模型。
![]()
图 3:提高 MNIST 上数据的非 IID 程度,不同攻击的错误率变化
图 3 给出了针对 MNIST 上不同程度的非 IID 数据进行的攻击的错误率变化情况。包括无攻击在内的所有攻击的错误率都随着非 IID 程度的提升而增加,只有针对 Krum 的攻击的错误率会随着非 IID 的程度而波动。可能的原因是,由于不同工作节点设备上的局部训练数据集的非 IID 情况越来越严重,局部模型呈现更加多样化的分布状态,从而为攻击留下了更多空间。
针对未知聚合规则,作者基于某一个聚合规则构建局部模型,之后通过实验验证分析其对其他聚合规则的攻击效果。表 2 显示了聚合规则之间的可转移性,其中也分别考虑了 MNIST 和 LR 分类器。「 Krum 攻击」和 「修整均值攻击」 表示分别基于 Krum 和修整平均聚合规则来构建折衷的局部模型。本实验中考虑部分知识攻击。表中给出的数字结果是测试错误率。
![]()
本文将用于防御数据中毒攻击的 RONI 和 TRIM 概括用于防御本文提出的的局部模型中毒攻击。在联邦学习的每次迭代计算全局模型之前,两种通用防御都删除了可能有害的局部模型。一种广义防御方法删除了对全局模型的错误率具有较大负面影响的局部模型(受 RONI 的启发,后者删除了对模型的错误率具有较大负面影响的训练示例),而另一种防御方法则除去了局部模型导致大量损失(受 TRIM 的启发,删除了对损失有较大负面影响的训练示例)。在这两种防御中,都假定主设备具有一个小的验证数据集。像现有的聚合规则(例如 Krum 和修整均值)一样,假设主设备知道受破坏的工作节点设备数量的上限 c。
表 3 给出了针对不同聚合规则的攻击的防御结果,表中的数字表示错误率,实验环境设置为 MNIST 数据库和 LR 分类器。「 Krum」和 「 Trimmed Mean」 列表示攻击者在进行攻击时假定的聚合规则,而各行则表示实际的聚合规则和防御措施。对于每个局部模型,当包含局部模型时,使用聚合规则来计算全局模型 A;在排除局部模型时,使用全局规则 B 来计算全局模型 B。该实验在验证数据库上计算全局模型 A 和 B 的错误率,分别记为 EA 和 EB,将 EA-EB 定义为局部模型的错误率影响,基于错误率的拒绝(Error Rate based Rejection,ERR)。较大的 ERR 表示如果在更新全局模型时将局部模型包括在内,则局部模型会显着增加错误率。此外,实验中还考虑另外一个指标:基于损失函数的拒绝(Loss Function based Rejection,LFR)。像基于错误率的拒绝一样,对于每个局部模型,计算全局模型 A 和 B。在验证数据库上计算模型 A 和模型 B 的交叉熵损失函数值,分别记为 LA 和 LB,将 LA-LB 定义为局部模型的损失影响。像基于错误率的拒绝一样,删除损失影响最大的 c 个局部模型,并汇总其余局部模型以更新全局模型。表 3 中的 Union 表示 ERR+LFR。
本实验中考虑部分知识攻击。表 3 的结果说明两方面问题,一是,LFR 与 ERR 相当或比 ERR 更有效,即 LFR 的测试错误率与 ERR 相似或小得多。二是,在大多数情况下,Union 与 LFR 相当,但在一种情况下(Krum + LFR 对 Krum 和 Krum + Union 对 Krum),Union 更有效。第三,LFR 和 Union 可以在某些情况下有效防御本文提出的攻击方法。
![]()
本文提出了一种模型中毒攻击方法,并证明了机器学习社区中给出的对某些工作节点设备的拜占庭式故障具有鲁棒性的联邦学习方法很容易受到本文所提出的局部模型中毒攻击方法的攻击。在针对攻击的防御问题中,作者对现有的数据中毒攻击的防御措施进行了归纳总结,用以抵御本文提出的模型中毒攻击方法。不过,这些归纳后得到的防御措施在某些情况下是有效的,但在其他情况下却是无效的。本文重点关注联邦学习中的非定向攻击,作者提出将会在今后的工作中开展更多针对定向攻击的研究。
4. Federated Variance-Reduced Stochastic Gradient Descent with Robustness to Byzantine Attacks
![]()
论文地址:https://arxiv.org/abs/1912.12716
本文是 University of Minnesota Georgios B. Giannakis 教授团队的成果,主要研究的是对拜占庭攻击具有鲁棒性的联合方差缩减随机梯度下降方法。具体的,本文讨论在恶意拜占庭攻击的情况下,在联邦学习网络中进行分布式有限优化学习的问题。为了应对这种攻击,迄今为止,大多数方法是将随机梯度下降(stochastic gradient descent,SGD)与不同的鲁棒性聚合规则相结合。然而,SGD 诱发的随机梯度噪声使我们很难区分由拜占庭攻击者发送的恶意信息和 「真实」 客户端发送的随机梯度噪声。这促使本文作者考虑通过降低随机梯度的方差,作为在拜占庭式攻击中鲁棒性 SGD 的手段,即:如果随机梯度噪声很小,恶意信息应该很容易识别。为减少随机优化过程中的方差,本文选择了 SAGA[2] 。在有限求和优化中 SAGA 被证明是最有效的,同时适合于分布式的环境,因此能够满足联邦学习架构的要求。
考虑一个网络有一个主节点(中央服务器)和 W 个工作节点(客户端设备),其中 B 个工作节点是拜占庭攻击者,他们的身份不为主节点所知。W 是所有工作节点的集合,B 是拜占庭攻击者的集合。数据样本均匀地分布在诚实的工作节点 W 上。f_w,j(x) 表示第 j 个数据样本在诚实工作节点 w 处的损失相对于模型参数 x 的损失。有限求和优化问题记为:
![]()
![]()
求解该问题的主要难点在于拜占庭攻击者可以串通,向主节点发送任意的恶意消息,从而使优化过程出现偏差。为此,本文假设 B<W/2,并证明所提出的拜占庭攻击算法能够容忍来自最多半数工作节点的攻击。
在收集到所有工作节点的随机梯度后,主节点更新模型为:
![]()
其中,γ^k 为非负步长。分布式 SGD 可以扩展到它的 mini-batch 版本,即每个工作节点均匀地随机选择一个 mini-batch 的数据样本,并将平均的随机梯度传回主节点。诚实的工作节点向主节点发送真正的随机梯度,而拜占庭的工作节点可以向主节点发送任意的恶意消息,以扰乱(偏置)优化过程。让(m_w)^k 表示工作节点 w 在轮次 k 向主节点发送的消息,给定为:
![]()
![]()
使用 {z; z ∈Z} 表示法线空间中的一个子集,{z; z ∈Z}的几何中位数为
![]()
基于此,分布式 SGD 可以被修改成抗拜占庭式攻击的形式:
![]()
当拜占庭工作节点的数量 B <W/2 时,几何中位数可以很好地接近均值{(m_w)^k}。这一特性使 抗拜占庭攻击的 SGD 算法 能够收敛到最优解的邻接点。图 1 示出随机梯度噪声对几何中位数聚集的影响。蓝点表示诚实的工作节点发送的随机梯度。红点表示拜占庭工作节点发送的恶意信息。加号表示基于几何中位数的鲁棒聚合的输出。五角星表示诚实工作节点发送的随机梯度的均值。诚实工作节点发送的随机梯度的方差在左图大,右图小。
![]()
由图 1 可知,当诚实工作节点发送的随机梯度方差较小时,真实均值与聚集值之间的差距也较小;也就是说,同样的拜占庭攻击效果较差。在这一观察的启发下,作者提出减少随机梯度的方差,以增强对拜占庭攻击的鲁棒性。
在分布式 SAGA 中,每个工作节点都维护着一个其所有本地数据样本的随机梯度表。具体的:
![]()
其中,ɸ^(k+1)_(w,j)是指在最近的 k 轮次结束时计算得到最新的 f’_(w,j)值的迭代。具体的,i^k_w 是本地数据样本的索引,即在轮次 k 由工作节点 w 基于数据样本 i^k_w 进行训练。f’_(w,j)(ɸ^k_(w,j))是指在工作节点 w、轮次 k 中,之前存储的第 j 个数据样本的随机梯度,以及可以计算得到:
![]()
上式结果表示工作节点 i 在轮次 k 处的修正随机梯度。SAGA 的模型更新表示为:
![]()
此时,工作节点 w 在轮次 k 向主节点发送的消息为:
![]()
本文使用的鲁棒性聚集规则是几何中位数。这就引出了所提出的拜占庭攻击弹性分布式形式的 SAGA:
![]()
本文所提出的抗击拜占庭攻击的 SAGA,简称 Byrd-SAGA,完整算法如下:
![]()
![]()
图 2 给出抗击拜占庭攻击的 SAGA 的图解。为了便于说明,诚实工作节点从 1 到 W-B,而拜占庭攻击者从 W-B+1 到 W,但实际操作中,拜占庭攻击者的身份是主节点不知道的。本文作者对抗击拜占庭攻击的 SAGA 还进行了理论分析,感兴趣的读者可以查阅原文相关内容。
本文给出了凸和非凸学习问题的数值实验。本文使用 IJCNN1 和 COVTYPE 数据集。其中,IJCNN1 包含 49,990 个训练数据样本,p=22 个维度。COVTYPE 包含 581012 个训练数据样本,p=54 个维度。在实验中考虑三种类型的攻击,包括:高斯、符号翻转和零梯度攻击。实验中利用均值和几何中位数聚集规则,对 SGD、mini-batch (B)SGD(BSGD)和 SAGA 进行比较。与 SGD 相比,BSGD 的随机梯度噪声较小,但计算成本较高。相比之下,SAGA 也降低了随机梯度噪声,但其计算成本与 SGD 相同。对于每个算法采用一个恒定的步长大小。具体计算代码及应用的数据库可见 https://github.com/MrFive5555/Byrd-SAGA。
实验结果分别见图 3 和图 4,其中,SAGA geomed 代表 Byrd-SAGA。从上至下:诚实信息的最优性差距和方差。从左至右:无攻击、高斯攻击、符号翻转攻击和零梯度攻击。在拜占庭攻击下,使用平均聚合的三种算法都失败了。而在三种使用几何中位数聚合的算法中,Byrd-SAGA 明显优于其他两种,而 BSGD 则优于 SGD。这表明了减少方差对处理拜占庭攻击的重要性。在诚实信息的方差方面,Byrd-SAGA、抗击拜占庭攻击 BSGD 和抗击拜占庭攻击 SGD 在 IJCNN1 数据集中的方差分别为 10^3、10^2 和 10^1。
对于 COVTYPE 数据集,Byrd-SAGA 和抗击拜占庭攻击 BSGD 在诚实信息方面具有相同的方差变化情况。Byrd-SAGA 实现了与抗击拜占庭攻击 BSGD 相似的最优性差距,但收敛速度更快,因为它能够使用更大的步长。
![]()
图 3:IJCNN1 数据集上使用均值和几何中位数聚合规则的分布式 SGD、mini-batch (B)SGD 和 SAGA 的性能
![]()
图 4:COVTYPE 数据集上使用均值和几何中位数聚合规则的分布式 SGD、mini-batch (B)SGD 和 SAGA 的性能
针对联邦学习中的拜占庭攻击问题,本文提出了一种新型的抗拜占庭攻击的 Byrd-SAGA 方法,通过联合有限求和优化抵抗拜占庭攻击。Byrd-SAGA 中的主节点使用几何中位数而不是平均数来聚合收到的模型参数。这种聚合方式显著地提高了 Byrd-SAGA 在受到拜占庭攻击时的稳健性。该方法确保了 Byrd-SAGA 能够线性收敛到最优解的邻域,其渐近学习误差完全由拜占庭工作节点数决定。作者提出,今后研究方向将是在完全去中心化的网络上开发和分析抗拜占庭攻击方法。
[1] Keith Bonawitz, et al. Practical Secure Aggregation for Privacy-Preserving Machine Learning, CCS 2017, https://arxiv.org/abs/1611.04482
[2] Aaron Defazio (https://arxiv.org/search/cs?searchtype=author&query=Defazio%2C+A), Francis Bach (https://arxiv.org/search/cs?searchtype=author&query=Bach%2C+F),et al. SAGA: A Fast Incremental Gradient Method With Support for Non-Strongly Convex Composite Objectives, NIPS2014, https://arxiv.org/abs/1407.0202.
作者介绍:
仵冀颖,工学博士,毕业于北京交通大学,曾分别于香港中文大学和香港科技大学担任助理研究员和研究助理,现从事电子政务领域信息化新技术研究工作。主要研究方向为
模式识别
、计算机视觉,爱好科研,希望能保持学习、不断进步。
关于机器之心全球分析师网络 Synced Global Analyst Network
机器之心全球分析师网络是由机器之心发起的全球性人工智能专业知识共享网络。在过去的四年里,已有数百名来自全球各地的 AI 领域专业学生学者、工程专家、业务专家,利用自己的学业工作之余的闲暇时间,通过线上分享、专栏解读、知识库构建、报告发布、评测及项目咨询等形式与全球 AI 社区共享自己的研究思路、工程经验及行业洞察等专业知识,并从中获得了自身的能力成长、经验积累及职业发展。
感兴趣加入机器之心全球分析师网络?点击阅读原文,提交申请。