学界 | 综述论文:对抗攻击的12种攻击方法和15种防御方法
选自arXiv
作者:Naveed Akhtar等
机器之心编译
参与:许迪、刘晓坤
这篇文章首次展示了在对抗攻击领域的综合考察。本文是为了比机器视觉更广泛的社区而写的,假设了读者只有基本的深度学习和图像处理知识。不管怎样,这里也为感兴趣的读者讨论了有重要贡献的技术细节。机器之心重点摘要了第 3 节的攻击方法(12 种)和第 6 节的防御方法(15 种),详情请参考原文。
尽管深度学习在很多计算机视觉领域的任务上表现出色,Szegedy et al. [22] 第一次发现了深度神经网络在图像分类领域存在有意思的弱点。他们证明尽管有很高的正确率,现代深度网络是非常容易受到对抗样本的攻击的。这些对抗样本仅有很轻微的扰动,以至于人类视觉系统无法察觉这种扰动(图片看起来几乎一样)。这样的攻击会导致神经网络完全改变它对图片的分类。此外,同样的图片扰动可以欺骗好多网络分类器。这类现象的深远意义吸引了好多研究员在对抗攻击和深度学习安全性领域的研究。
自从有了 Szegedy 的发现,机器视觉领域中陆续出现了好几个有意思的受对抗攻击影响的结果。例如,除了在特定图像的对抗性扰动之外,Moosavi-Dezfooli et al. [16] 展示了「通用扰动(universal perturbations)」的存在(如图 1 所示),这种通用扰动可以让一个分类器对所有图片错误分类。同样的,Athalye et al. [65] 展示了即使用 3D 打印的真实世界中存在的物体也可以欺骗深度网络分类器(如图 2 所示)。考虑到深度学习研究在计算机视觉的重要性和在真实生活中的潜在应用,这篇文章首次展示了在对抗攻击领域的综合考察。这篇文章是为了比机器视觉更广泛的社区而写的,假设了读者只有基本的深度学习和图像处理知识。不管怎样,这里也为感兴趣的读者讨论了有重要贡献的技术细节。

图 1:三种网络的对抗样本和原始样本的对比,以及错误分类结果。

图 2:3D 打印的对抗样本。
第 2 节里列举了机器视觉中关于对抗攻击的常用术语。
第 3 节回顾了针对图片分类任务的对抗攻击。

图 3:单像素攻击。
第 4 节单独介绍了在实际生活场景中对抗攻击的方法。

图 4:人脸识别的对抗样本构造。
第 5 节关注对抗攻击的工作焦点和研究方向。
第 6 节讨论了防御对抗攻击的文献。
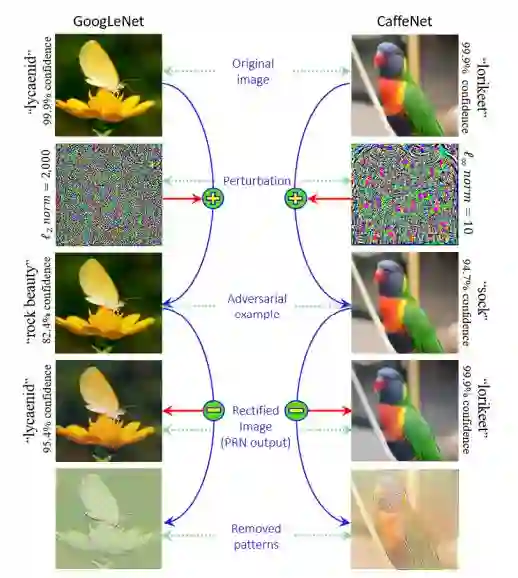
图 5:防御通用扰动的图示。
在第 7 章里,我们以讨论过的文献为基础的展望了未来的研究方向。
第 8 章总结并画上结尾。
论文:Threat of Adversarial Attacks on Deep Learning in Computer Vision: A Survey

论文地址:https://arxiv.org/abs/1801.00553
深度学习正占据如今飞速发展的机器学习和人工智能领域的心脏地位。在机器视觉领域中,它已经变成了从自动驾驶到监控、安保应用中的主力。然而,即便深度网络已经展示了在处理复杂问题时所取得的现象级成功,最近的研究表明它们对于输入中带有的轻微扰动是很脆弱的,从而导致错误的输出。对于图片来说,这样的扰动经常是太小了从而不能被人类感知,但是它们完全愚弄了深度学习模型。对抗攻击造成了深度学习在实践中成功的一系列威胁,进而引导了大量的研究进入这个方向。这篇文章展示了第一个对抗攻击在机器视觉领域的深度学习中的综合考察。我们回顾了对抗攻击设计的研究,分析了这些攻击的存在性以及提出的防御机制。为了强调对抗攻击在实际场所中存在,我们独立地回顾了实际场景中的对抗攻击。最终,我们引用文献来展望更广阔的研究方向。
3.1 对分类网络的攻击
本节列举了 12 种生成对抗样本的方法,专门针对分类网络。
1 Box-constrained L-BFGS
Szegedy[22] 等人首次证明了可以通过对图像添加小量的人类察觉不到的扰动误导神经网络做出误分类。他们首先尝试求解让神经网络做出误分类的最小扰动的方程。但由于问题的复杂度太高,他们转而求解简化后的问题,即寻找最小的损失函数添加项,使得神经网络做出误分类,这就将问题转化成了凸优化过程。
2 Fast Gradient Sign Method (FGSM)
Szegedy 等人发现可以通过对抗训练提高深度神经网络的鲁棒性,从而提升防御对抗样本攻击的能力。GoodFellow[23] 等人开发了一种能有效计算对抗扰动的方法。而求解对抗扰动的方法在原文中就被称为 FGSM。
Kurakin[80] 等人提出了 FGSM 的「one-step target class」的变体。通过用识别概率最小的类别(目标类别)代替对抗扰动中的类别变量,再将原始图像减去该扰动,原始图像就变成了对抗样本,并能输出目标类别。
3 Basic & Least-Likely-Class Iterative Methods
one-step 方法通过一大步运算增大分类器的损失函数而进行图像扰动,因而可以直接将其扩展为通过多个小步增大损失函数的变体,从而我们得到 Basic Iterative Methods(BIM)[35]。而该方法的变体和前述方法类似,通过用识别概率最小的类别(目标类别)代替对抗扰动中的类别变量,而得到 Least-Likely-Class Iterative Methods[35]。
4 Jacobian-based Saliency Map Attack (JSMA)
对抗攻击文献中通常使用的方法是限制扰动的 l_∞或 l_2 范数的值以使对抗样本中的扰动无法被人察觉。但 JSMA[60] 提出了限制 l_0 范数的方法,即仅改变几个像素的值,而不是扰动整张图像。
5 One Pixel Attack
这是一种极端的对抗攻击方法,仅改变图像中的一个像素值就可以实现对抗攻击。Su[68] 等人使用了差分进化算法,对每个像素进行迭代地修改生成子图像,并与母图像对比,根据选择标准保留攻击效果最好的子图像,实现对抗攻击。这种对抗攻击不需要知道网络参数或梯度的任何信息。
6 Carlini and Wagner Attacks (C&W)
Carlini 和 Wagner[36] 提出了三种对抗攻击方法,通过限制 l_∞、l_2 和 l_0 范数使得扰动无法被察觉。实验证明 defensive distillation 完全无法防御这三种攻击。该算法生成的对抗扰动可以从 unsecured 的网络迁移到 secured 的网络上,从而实现黑箱攻击。
7 DeepFool
Moosavi-Dezfooli 等人 [72] 通过迭代计算的方法生成最小规范对抗扰动,将位于分类边界内的图像逐步推到边界外,直到出现错误分类。作者证明他们生成的扰动比 FGSM 更小,同时有相似的欺骗率。
8 Universal Adversarial Perturbations
诸如 FGSM [23]、 ILCM [35]、 DeepFool [72] 等方法只能生成单张图像的对抗扰动,而 Universal Adversarial Perturbations[16] 能生成对任何图像实现攻击的扰动,这些扰动同样对人类是几乎不可见的。该论文中使用的方法和 DeepFool 相似,都是用对抗扰动将图像推出分类边界,不过同一个扰动针对的是所有的图像。虽然文中只针对单个网络 ResNet 进行攻击,但已证明这种扰动可以泛化到其它网络上。
9 UPSET and ANGRI
Sarkar[146] 等人提出了两个黑箱攻击算法,UPSET 和 ANGRI。UPSET 可以为特定的目标类别生成对抗扰动,使得该扰动添加到任何图像时都可以将该图像分类成目标类别。相对于 UPSET 的「图像不可知」扰动,ANGRI 生成的是「图像特定」的扰动。它们都在 MNIST 和 CIFAR 数据集上获得了高欺骗率。
10 Houdini
Houdini[131] 是一种用于欺骗基于梯度的机器学习算法的方法,通过生成特定于任务损失函数的对抗样本实现对抗攻击,即利用网络的可微损失函数的梯度信息生成对抗扰动。除了图像分类网络,该算法还可以用于欺骗语音识别网络。
11 Adversarial Transformation Networks (ATNs)
Baluja 和 Fischer[42] 训练了多个前向神经网络来生成对抗样本,可用于攻击一个或多个网络。该算法通过最小化一个联合损失函数来生成对抗样本,该损失函数有两个部分,第一部分使对抗样本和原始图像保持相似,第二部分使对抗样本被错误分类。
12 Miscellaneous Attacks
这一部分列举了更多其它的生成对抗样本的方法,详情请参见原文。
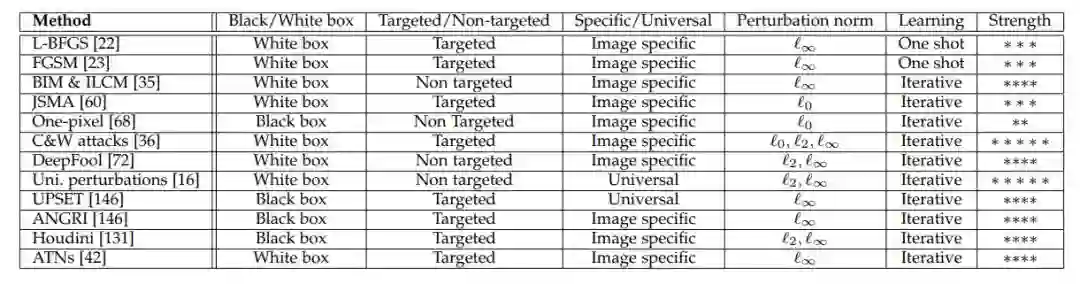
表 1:以上列举的各种攻击方法的属性总结:「perturbation norm」表示其限制的 p-范数(p-norm)以使对抗扰动对人类不可见或难以察觉。strength 项(*越多,对抗强度越大)基于回顾过的文献得到的印象。
3.2 分类/识别场景以外的对抗攻击
除了 Houdini 这个例外, 在 3.1 节中概述的所有主流对抗攻击直接针对于分类任务——欺骗基于 CNN 的分类器。然而,因为对抗性威胁的严重性,对抗攻击的研究已经超越了分类/识别场景。文中概述了以下分类应用领域之外的攻击深度神经网络的方法:
在自编码器和生成模型上的攻击
在循环神经网络上的攻击
深度强化学习上的攻击
在语义切割和物体检测上的攻击
目前,在对抗攻击防御上存在三个主要方向:
1)在学习过程中修改训练过程或者修改的输入样本。
2)修改网络,比如:添加更多层/子网络、改变损失/激活函数等。
3)当分类未见过的样本时,用外部模型作为附加网络。
第一个方法没有直接处理学习模型。另一方面,另外两个分类是更加关心神经网络本身的。这些方法可以被进一步细分为两种类型:(a)完全防御;(b)仅探测(detection only)。「完全防御」方法的目标是让网络将对抗样本识别为正确的类别。另一方面,「仅探测」方法意味着在对抗样本上发出报警以拒绝任何进一步的处理。详细的分类在图 9 中展示了。剩下的章节是按这个分类来整理的。
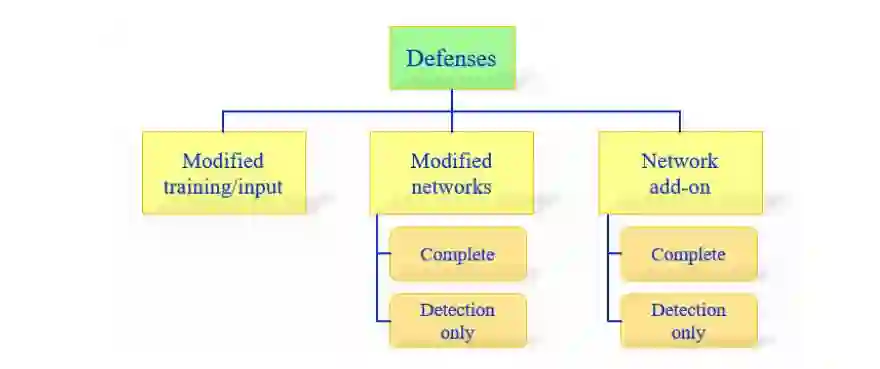
图 9:防御对抗攻击的方法分类。
6.1 修改训练过程/ 输入数据
1 蛮力对抗训练
通过不断输入新类型的对抗样本并执行对抗训练,从而不断提升网络的鲁棒性。为了保证有效性,该方法需要使用高强度的对抗样本,并且网络架构要有充足的表达能力。这种方法需要大量的训练数据,因而被称为蛮力对抗训练。很多文献中提到这种蛮力的对抗训练可以正则化网络以减少过拟合 [23,90]。然而,Moosavi-Dezfooli[16] 指出,无论添加多少对抗样本,都存在新的对抗攻击样本可以再次欺骗网络。
2 数据压缩
注意到大多数训练图像都是 JPG 格式,Dziugaite[123] 等人使用 JPG 图像压缩的方法,减少对抗扰动对准确率的影响。实验证明该方法对部分对抗攻击算法有效,但通常仅采用压缩方法是远远不够的,并且压缩图像时同时也会降低正常分类的准确率,后来提出的 PCA 压缩方法也有同样的缺点。
3 基于中央凹机制的防御
Luo[119] 等人提出用中央凹(foveation)机制可以防御 L-BFGS 和 FGSM 生成的对抗扰动,其假设是图像分布对于转换变动是鲁棒的,而扰动不具备这种特性。但这种方法的普遍性尚未得到证明。
4 数据随机化方法
Xie[115] 等人发现对训练图像引入随机重缩放可以减弱对抗攻击的强度,其它方法还包括随机 padding、训练过程中的图像增强等。
6.2 修改网络
5 深度压缩网络
人们观察到简单地将去噪自编码器(Denoising Auto Encoders)堆叠到原来的网络上只会使其变得更加脆弱,因而 Gu 和 Rigazio[24] 引入了深度压缩网络(Deep Contractive Networks),其中使用了和压缩自编码器(Contractive Auto Encoders)类似的平滑度惩罚项。
6 梯度正则化/ masking
使用输入梯度正则化以提高对抗攻击鲁棒性 [52],该方法和蛮力对抗训练结合有很好的效果,但计算复杂度太高。
7 Defensive distillation
distillation 是指将复杂网络的知识迁移到简单网络上,由 Hinton[166] 提出。Papernot[38] 利用这种技术提出了 Defensive distillation,并证明其可以抵抗小幅度扰动的对抗攻击。
8 生物启发的防御方法
使用类似与生物大脑中非线性树突计算的高度非线性激活函数以防御对抗攻击 [124]。另外一项工作 Dense Associative Memory 模型也是基于相似的机制 [127]。
9 Parseval 网络
在一层中利用全局 Lipschitz 常数加控制,利用保持每一层的 Lipschitz 常数来摆脱对抗样本的干扰。
10 DeepCloak
在分类层(一般为输出层)前加一层特意为对抗样本训练的层。它背后的理论认为在最显著的层里包含着最敏感的特征。
11 混杂方法
这章包含了多个人从多种角度对深度学习模型的调整从而使模型可以抵抗对抗性攻击。
12 仅探测方法
这章介绍了 4 种网络,SafetyNet,Detector subnetwork,Exploiting convolution filter statistics 及 Additional class augmentation。
SafetyNet 介绍了 ReLU 对对抗样本的模式与一般图片的不一样,文中介绍了一个用 SVM 实现的工作。
Detector subnetwork 介绍了用 FGSM, BIM 和 DeepFool 方法实现的对对抗样本免疫的网络的优缺点。
Exploiting convolution filter statistics 介绍了同 CNN 和统计学的方法做的模型在分辨对抗样本上可以有 85% 的正确率。
6.3 使用附加网络
13 防御通用扰动
利用一个单独训练的网络加在原来的模型上,从而达到不需要调整系数而且免疫对抗样本的方法。
14 基于 GAN 的防御
用 GAN 为基础的网络可以抵抗对抗攻击,而且作者提出在所有模型上用相同的办法来做都可以抵抗对抗样本。
15 仅探测方法
介绍了 Feature Squeezing、MagNet 以及混杂的办法。
Feature Squeezing 方法用了两个模型来探查是不是对抗样本。后续的工作介绍了这个方法对 C&W 攻击也有能接受的抵抗力。
MagNet:作者用一个分类器对图片的流行(manifold)测量值来训练,从而分辨出图片是不是带噪声的。
混杂方法(Miscellaneous Methods):作者训练了一个模型,把所有输入图片当成带噪声的,先学习怎么去平滑图片,之后再进行分类。

以下是机器之心报道过的对抗攻击的案例:
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com



