机器人在人机协作团队中成“领导”?工作原理为何?

在合作任务与对抗任务中的方式各有不同!
编译 | 晟炜
编辑 | Pita
随着机器人技术的发展,机器人在实际生活中发会越来越重要的作用。它不仅只是根据人类的指令来行动,更开始在人机协同工作中开始发挥引导人类工作的作用。本文介绍了斯坦福 AI 研究院的研究人员如何应用领导者-跟随者图(LFG)来更好地发挥机器人在团队中的领导作用。
我们的生活大多围绕着团队协作。例如,我们在与人群协作或影响人群时,既能够以显而易见的方式(如一起做饭时),也能够以不易察觉的方式(如在高速公路上共享车道时)。随着机器人越来越融入社会,它们应该能够很好地与人类群体协作。

团体协作的例子包括协作烹饪、抗议和在拥挤的空间中穿行。
然而,要影响人群是具有挑战性的。例如,想象一下在一个志愿搜救任务中,无人机学习关于目标位置的最新信息(如下面的蓝色标记所示)。假设没有直接的通讯方式,无人机应该如何带领志愿者前往那个地点?

无人机领导团队的一种方式,是分别对每个个体进行建模并单独施加影响。其中,无人机建模的用意在于理解并预测某个人的行为。然而,独立于他人的建模和影响并不能很好地扩展到人数更多的个体,而且我们无法在进行在线快速计算。

一个为每个志愿者单独建模的无人机。这种方法不适用于大量智能体。
影响人类团队的另一种方法是放弃任何建模,直接从对团队的观察中学习策略或行动规划。这种方法为人数同样多的团队提供了一个合理的解决方案。但是,添加或减去一个团队成员会改变模型的输入大小,并且需要重新训练模型。
我们取得成果如下:
引入了一种可以用可伸缩的方式为人群交互建模的方法。
描述了机器人如何利用这些知识影响人类团队。
人类群体的潜在结构
与为群体中的每个个体建模不同,我们的核心思想是关注个体之间的建模关系。当在群体中互动时,我们不再孤立地行动,而是根据他人的行动有条件地行动。这些依赖关系提供了一种结构,我们可以使用这种结构来形成对他人的期望,并据此行事。在更大的范围内,这允许我们发展出规范、惯例,甚至文化。这些依赖关系对机器人很有用。因为它们提供了丰富的信息源,可以帮助机器人建模和预测人类行为。我们称这些依赖关系为潜在结构。


日本(左)和印度(右)形成了不同的驾驶文化。
潜在结构的一个重要例子是领导和跟随行为。我们可以很容易地组成团队,并决定是否应该跟随或带领团队高效地完成任务。例如,在搜救任务中,一旦发现目标的新信息,人类就能自发地成为领导者。我们还默默地协调领导和跟随策略。举个例子,当司机开车时,他们会跟随对方穿过车道。在工作中,我们将重点建模潜在的引导和跟随结构,并将它作为一个运行示例。

在搜救任务中,志愿者之间潜在的领导和跟随结构的例子(左图),以及车辆在交通中相互跟随的例子(右图)。
那么我们该如何对这些潜在结构进行建模呢?理想模型应该具有哪些性质呢?在讨论如何建立潜在结构模型之前,让我们先确定一些必备要素?
复杂性:由于这些结构通常是隐式形成的,我们的模型应该足够复杂,能够捕获个体之间的复杂关系。
可伸缩性:模型应该能够适应不断变化的智能体数量。
潜在结构建模
最简单的情况
我们使用监督学习方法来估计两个人类智能体之间的关系。回到必备要素的讨论,这解决了复杂性的问题,因为使用基于学习的方法允许我们捕获这对组合可能拥有的复杂关系。使用模拟器,我们可以要求参与者演示我们想要度量的期望关系,例如领导和跟随。
我们将搜救任务抽象为一个游戏,其中目标代表潜在的幸存者位置。在下面的例子中,参与者被要求互相领导和跟随,以便集体决定要达成的目标。与人有关的数据通常充满噪音,很难大规模收集。为了弥补这个缺点,我们用模拟的人类数据扩充了我们的数据集。然后,我们将这些数据输入神经网络模块。这些模块经过训练,可以预测前导关系和后导关系。这为我们提供了一个模型,可以评估每个智能体以及目标成为智能体的领导者的可能性。
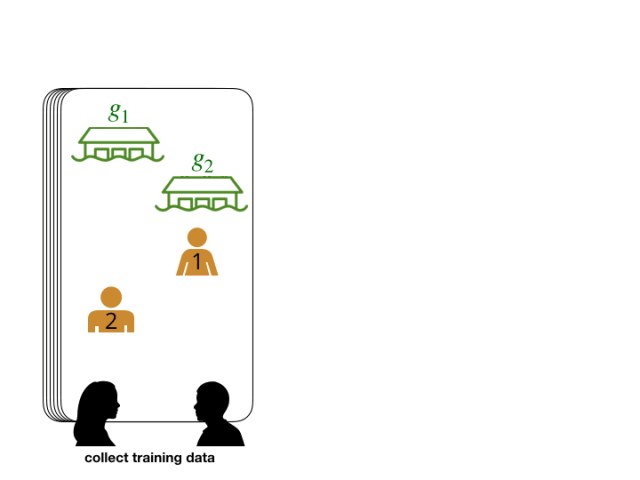
该网络预测玩家 2 的领导者是玩家 1。
扩大团队规模
现在,我们如何给一个更大的团队建模呢?使用上面的模型,我们可以通过计算所有智能体和目标之间成对关系的得分,将多个人类之间的关系表示为一个图。每个描述的边都有一个由我们训练过的神经网络分配的概率(概率在下面的图中抽象出来)。
我们计算了所有可能的领导者和追随者之间的领导者-追随者关系的两两权重。
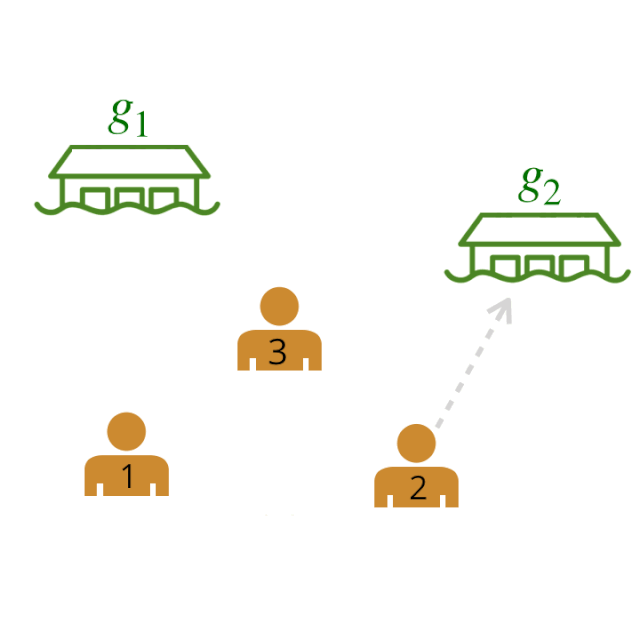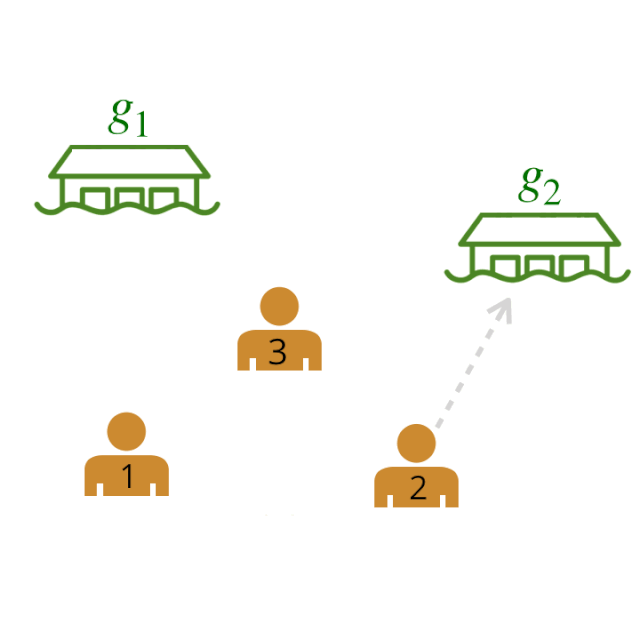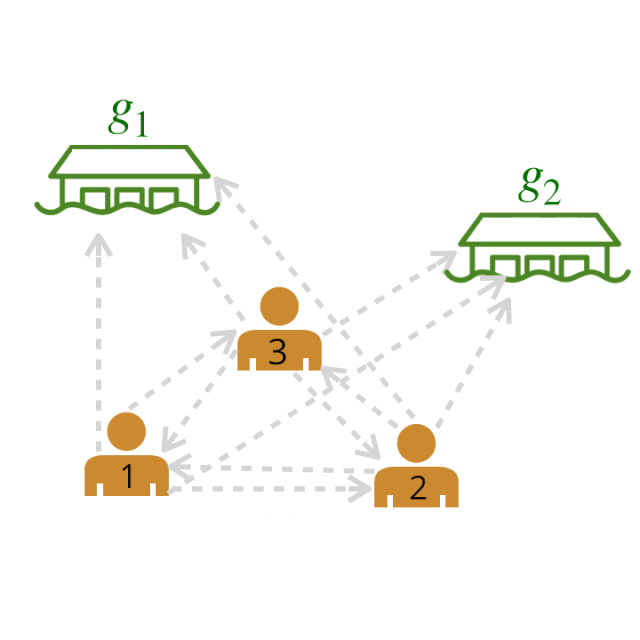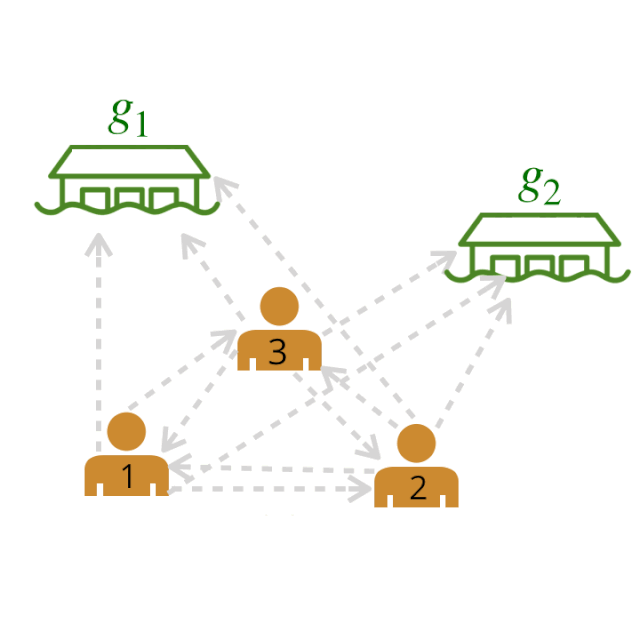
然后利用图论算法对原始图进行剪枝,得到最大似然图。例如,我们可以贪婪地为每个智能体选择权重最高的出边(outgoing edge )。
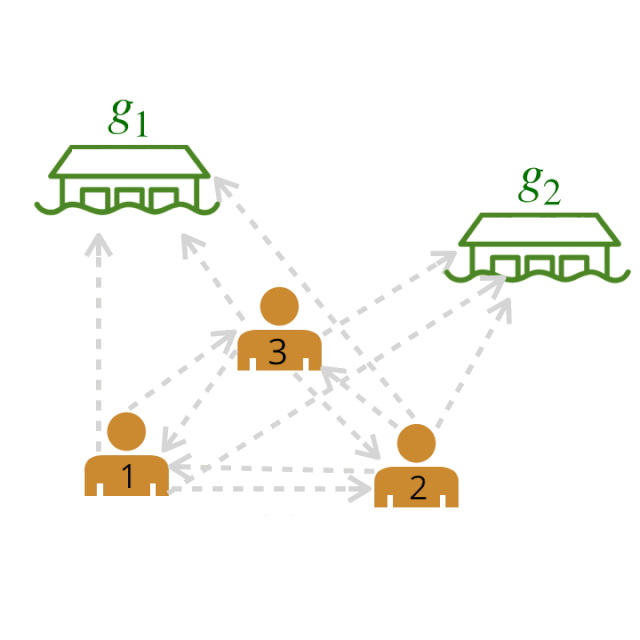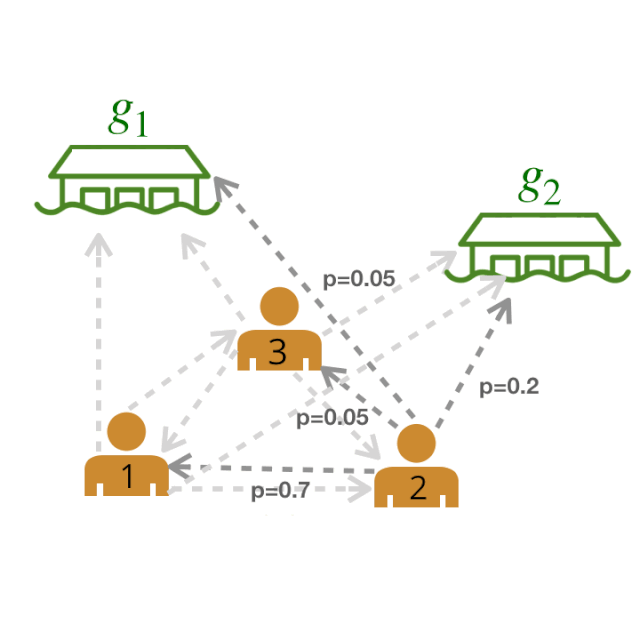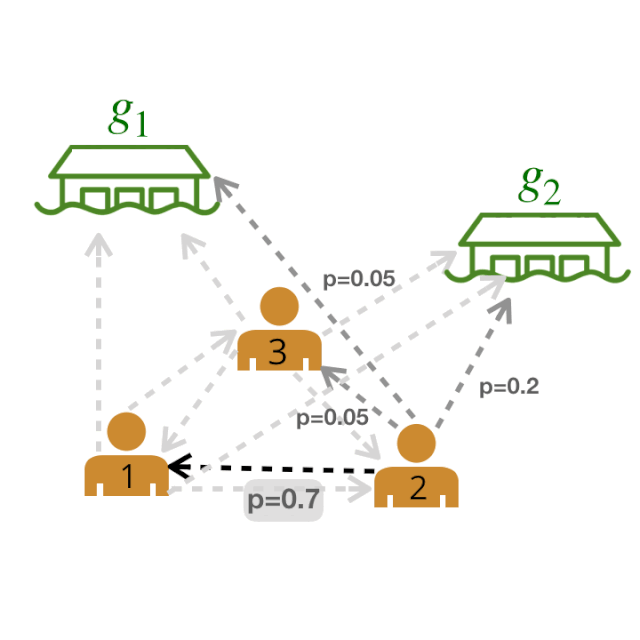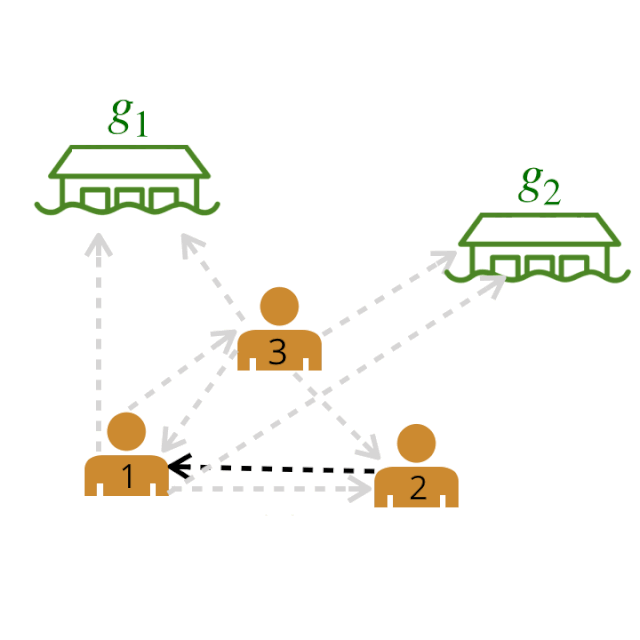
剩下的图中,粗体边表示最有可能的边。我们称这个图为领导者-追随者图(LFG)。
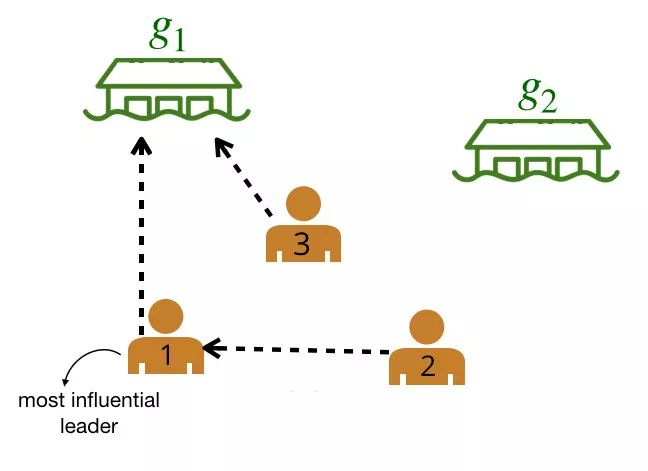
领导者-追随者图(LFG)。我们可以使用 LFG 来确定最有影响力的领导者,即拥有最多追随者的智能体。
由于我们可以很容易地对实时变换的智能体数量进行建模,因此图结构可以随着智能体数量的变化而伸缩。例如,在下一个时间步长 $kth$ 中添加一个智能体所需要的时间与智能体程序的数量 $n$ 和目标的数量 $m$ 线性相关。在实践中,这需要以毫秒为单位来计算。
我们的模型泛化后有多准确?
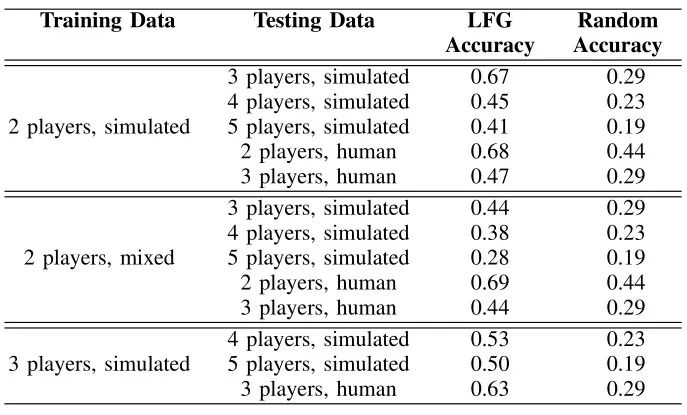
通过将领导者-追随者图所做的预测与真实落地的预测进行比较,来评估我们的模型泛化的准确性。用模拟数据和同时包含模拟和真实人类数据的数据(混合数据)进行训练实验。我们发现,训练更多的智能体有助于模型的推广。这表明,需要权衡使用较少的智能体进行训练还是使用量较多的智能体进行训练(这需要收集更多的数据)。
潜在结构对机器人有什么用?
机器人可以利用潜在结构来推断团队的有用信息。例如,在领导和跟随的例子中,我们可以识别诸如智能体的目标或谁是最有影响力的领导者之类的信息。这些信息允许机器人识别对任务至关重要的关键目标或智能体。考虑到这一点,机器人可以采取行动来达到预期的结果。下面是机器人利用图形结构影响人类团队的两项任务:
A.合作任务
在许多现实生活场景中,能够带领一组人实现目标是很有用的。例如,在搜救任务中,拥有更多幸存者位置信息的机器人应该能够领导团队。我们已经创建了一个类似的场景,其中有两个目标,幸存者的潜在位置,以及一个知道幸存者所在位置的机器人。机器人试图通过带领所有队友到达目标位置来最大化联合效用。为了影响团队,机器人使用领导者-跟随者图来推断当前最有影响力的领导者是谁。然后机器人选择采取最大化最具影响力的领导者实现最优目标的概率的动作。
在下面的图中,绿色的圆圈代表位置(或目标),橙色的圆圈代表模拟的人类智能体,黑色的圆圈代表机器人。机器人正试图带领团队走向更理想的底部位置。我们将使用图结构的机器人(上)与贪婪地瞄准最优目标的机器人(下)进行对比。
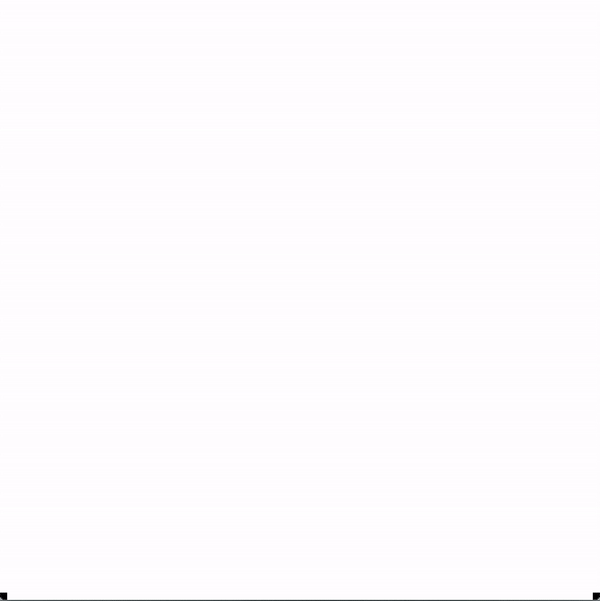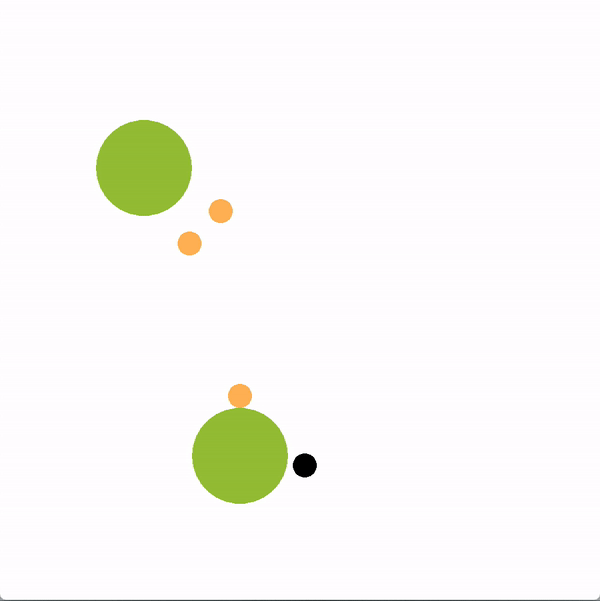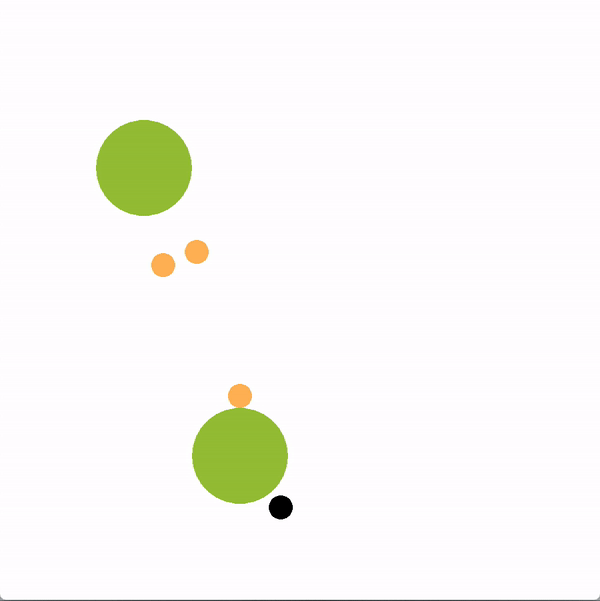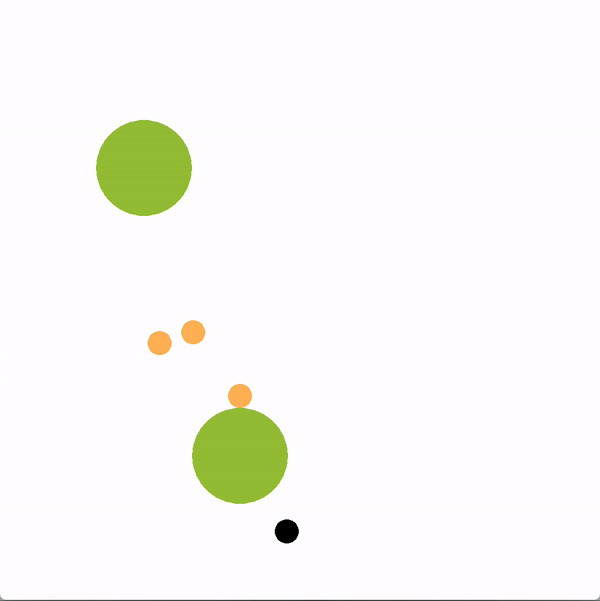
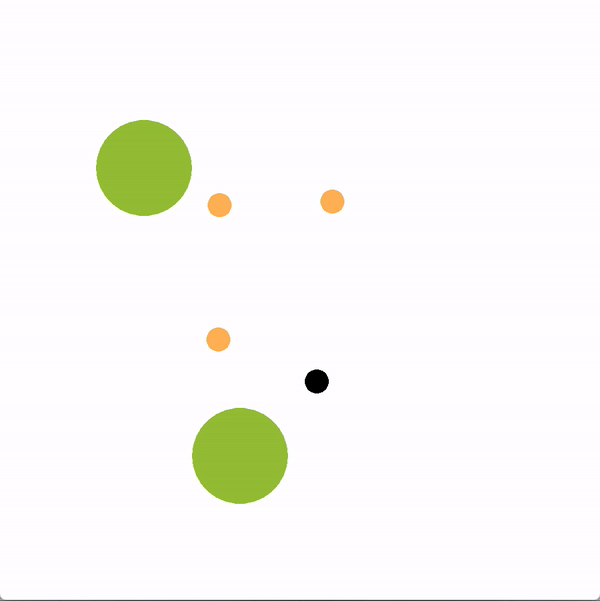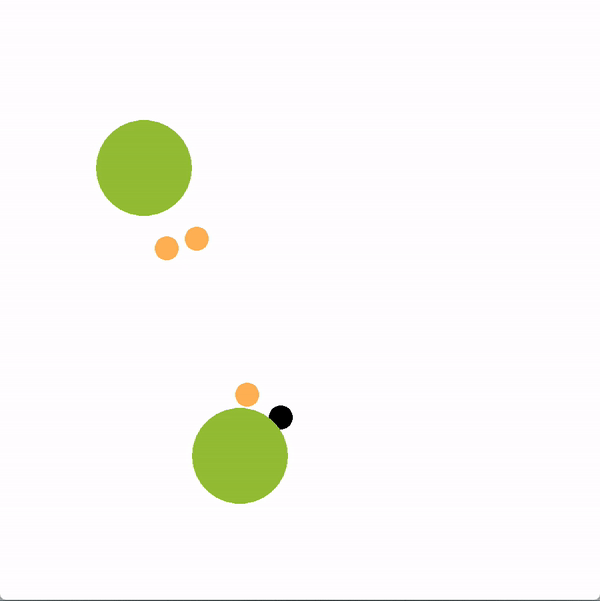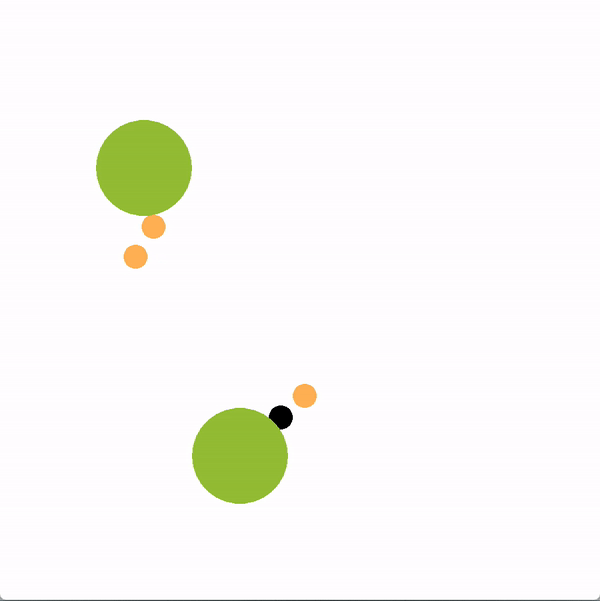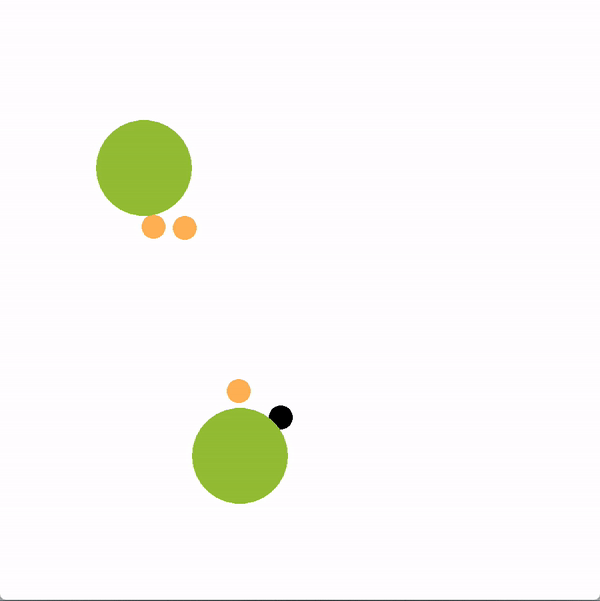
上方图中,机器人向底部移动,并围绕底部移动,这是最优的目标,目的是引导推断出的领导者向目标移动。下方图中,机器人直接朝底部目标前进,没有任何积极影响队友的企图。
如果大多数人首先与底层目标发生冲突,机器人就会成功;如果大多数人与次优目标发生冲突,机器人就会失败。下面是一个图表,它记录了使用图形表示的机器人与使用其他基线策略的机器人的成功率。
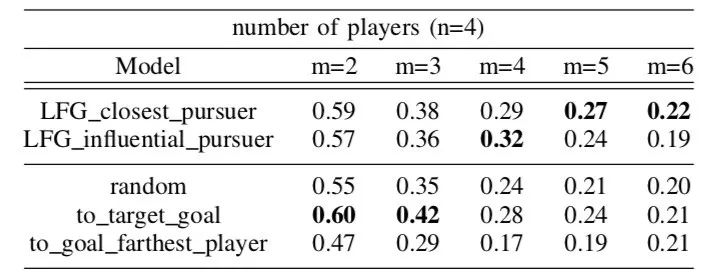
超过100个合作游戏的成功率,其中n=4个玩家,目标不同
我们发现,在具有大量潜在目标的更困难的场景中,图形表示是有用的。
B .对抗任务
机器人也可能想要阻止人类团队达成集体目标。例如,想象一个夺旗游戏,一个机器人队友试图阻止对手夺旗。
我们创造了一个类似的任务,一个机器人想要阻止一个人类团队达成目标。为了让团队陷入停滞,敌对型机器人使用领导者-追随者图来识别当前最有影响力的领导者是谁。然后,机器人选择采取能够引导其推断出的最有影响力的领导者偏离目标的最大化概率的行动。下图左边显示了机器人的动作示例。在右边,我们展示了一个简单策略的例子,一个机器人随机选择一个玩家,并试图阻止它,但没有成功。

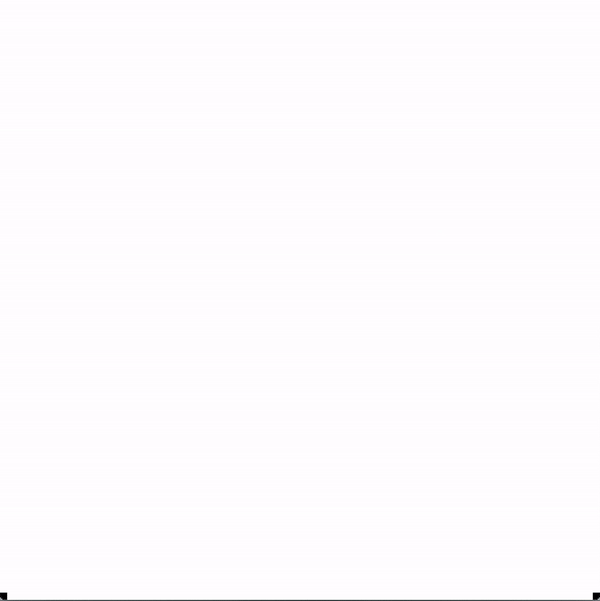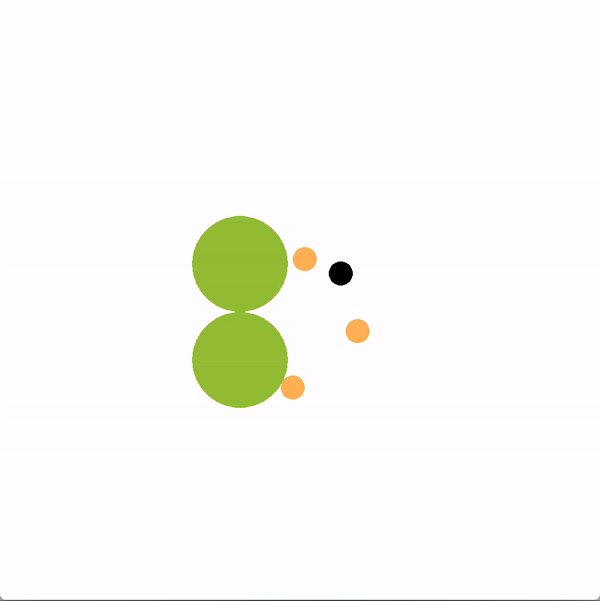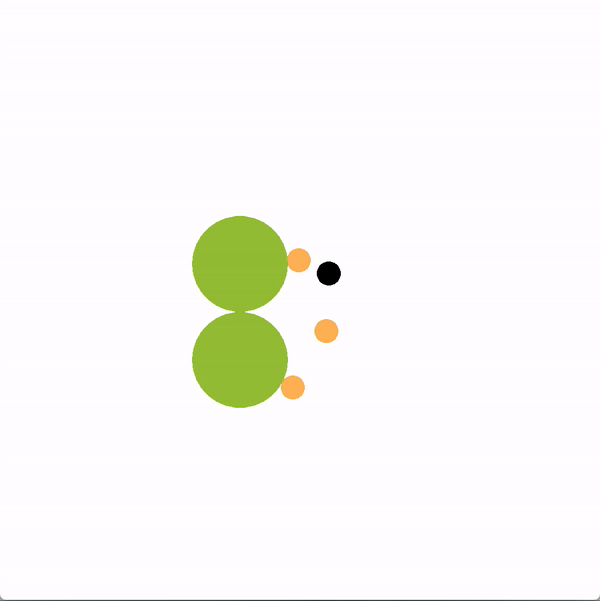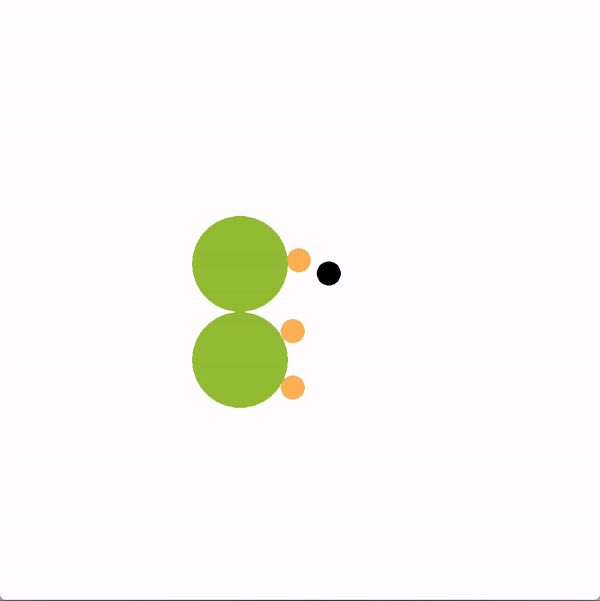
上方图中,机器人使用领导者-追随者图来采取行动,阻止推断出来的领导者达到目标。下方图中,机器人没能成功地跟随一名玩家以阻止他达到目标。
通过阻止玩家达到目标,机器人试图尽可能延长游戏时间。这是一个使用图形表示与其他基线策略进行比较的机器人的图。
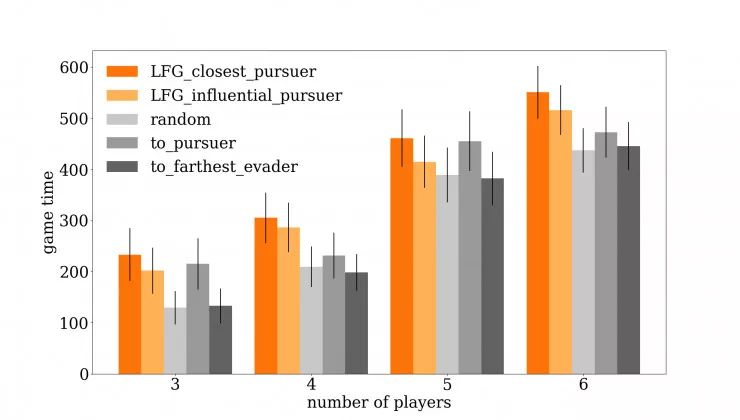
使用领导者-追随者图 (LFG)的两种策略比其他基线方法成功地延长了游戏时间。
我们发现,与其他基准策略相比,使用我们的图形表示的机器人在延长游戏时间方面最为成功。
接下来是什么?
我们引入了一种可伸缩的方法,表示团队中的固有结构。然后,我们演示了如何使用这个结构来设计智能影响行为。对于未来的工作,我们感兴趣的有以下几点:
实际实验。我们正在微型群机器人上实现我们的算法,这样就可以用真实的机器人和人类进行人机合作实验。
改变工作领域和结构。在更多类型的潜在结构(例如,团队成员如何信任彼此)和不同领域(例如,驱动,部分可观察的设置)上测试我们的框架是很好的。
想要了解更多,可阅读论文原文:
Influencing Leading and Following in Human-Robot Teams, Minae Kwon*, Mengxi Li*, Alexandre Bucquet, Dorsa Sadigh Proceedings of Robotics: Science and Systems (RSS), June 2019
via:http://ai.stanford.edu/blog/influencelead/
封面图来源:https://alexandre.alapetite.fr/doc-alex/robot-mobile-laptop/






