Cross-Modal & Metric Learning 跨模态检索专题-1

·前言
去年在跨模态检索/匹配 (cross-modal retrieval/matching) 方向开展了一些研究与应用,感觉比较有意思,所以想写点东西记录一下。这个研究方向并不是一个很"干净"的概念,它可以与 representation learning、contrastive learning、unsupervised leraning 等等概念交叉联系。并没有时间和能力写综述,思来想去就以研究较多的图文跨模态检索为切入点来介绍下相关工作。
本专题计划分3个部分介绍图文跨模态检索的一些工作与思考。第一篇将侧重 "multi-modal" 和 "application", 介绍相关概念与研究背景;第二、三篇会侧重"algorithm" 介绍这个方向研究的技术路线,其中第二篇介绍基于 GAN 的追求公共子空间的 cross-modal 检索;第三篇则从 modal 抽象成更一般的 domain,并且将多域扩展到单域,总结分析单/多域匹配问题,主要介绍基于 contrastive learning / instances discrimination的研究思路。专题重点将会在第3篇,可能会用视频的方式介绍。我在实际工作中分别使用过 GAN 和 instance discrimination 这2种思路,近期结合二者尝试了综合模型效果提升明显。
注:本专题内容主要来源于我去年的几次内部分享笔记,当时 PPT引用了一些来自互联网的图片,但是现在出处实在是找不全了,所以不会一个个注明来源,如果有侵权,可以联系删除,谢谢~
本文脉络
多模态研究背景介绍
跨模态检索的两类研究方法
工业界应用中要注意transfer learning
·背景介绍
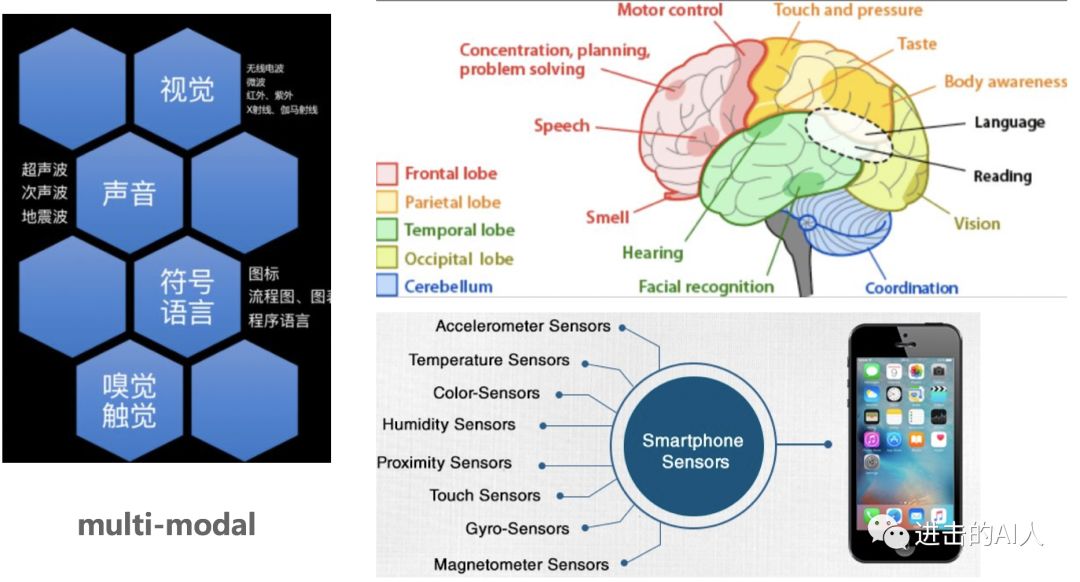
Fig. 多模态信息 everywhere
此刻的你也许正坐在电脑前,听着喜欢的音乐,看着上面这张图片,读着这段文字,等着香醇扑鼻的热咖啡冷一点再喝。世界是复杂而又多元的,为了理解这个世界,人的大脑就要做到分工明确而又统一指挥。分工明确是指不同区域负责不同的感官,接受图片、文字、气味等外界不同模态的信息;统一指挥是指能够将这些多个模态的信息综合处理互相融合最终得到统一的处理反应。
近几年媒体一直在"炒"人工智能这个概念,学术界和工业界也是在不断的研究与应用(见下图几个顶级会议的文章研究关键词分析),幻想着能够搭建出一个 brain 来逼近人脑的功能。

Fig. AI相关科研现状
上图中 CVPR、ACL、ACM MM 分别属于了图像、文本、多媒体3个领域的顶级会议。虽然统计有幸存者偏差,不过还是能说明目前很多研究的对象还是相对独立的单个模态信号。MM 虽然是交叉学科但是 CV 的研究还是明显超过 NLP。当前这样独立发展,很难在一个融合的系统生态中完美的应用。因此基于多模态、跨模态的研究是很重要也很有必要的。
"那应该怎么研究呢?", 一位不愿露面的网友如是问道。

Fig. 各个模态数据不对应,各自的空间大不相同
本文主要以图片和文本两个模态的信号来展开介绍。如上图所示,若以左侧小女孩图片为 anchor,那么可以有下方多种相关文本语句来描述;同理如若以图片右侧那句话『放风筝的小女孩』为 anchor/seed,也可以找到周围4幅图片来代表这句话。所以我们可以看到图文不同模态信号之间存在一种多对多的"映射"关系。这里的映射不是普通意义上的 map 函数,有点类似翻译模型(中文和英文两个不同 domain 的信号),但又复杂的多。文本域中的信号不一定能在图片域中找到对应的信号,比如『3只眼睛的男人带着3个头的小孩在遛狗』这句话就找不到一张图片来对应。"杨戬和哪吒拉着哮天犬马上就到",不愿露面的网友这思维挺敏捷的。。。总之可以看到由于不同模态的信息所处的空间差异太大,想要用 id 映射的方式来打通是不可能的。同时,多模态研究的重点也正在于如何将这些截然不同的空间互相关联上?

Fig. 空间映射是本质
上面说到两个模态的空间映射是这类问题的本质。这个所谓的映射,可以表现为不同的应用形式。比如图文这2个模态,就可以有上图3类常见应用方向:生成、问答、检索。Generate 方向 任务包扩给一张图,让你生成一段话来描述它(image caption);或给一句话,让你生成一张对应的图片(各种GAN)。VQA 类任务则更加重视内容理解,如给一张图片,让你回答图中穿黑衣服的有几个人?Generate 和 VQA 任务更多的是细粒度的研究,所以 attention 这个好东西就会经常用到。而我们这个专题要探讨的是第3类应用--检索/匹配(下面简称检索)。这个任务更多的是语义级别的理解,往往不需要太细粒度。检索任务就是给定一个模态中的信号,让你在另一个模态的空间中找到"对应的"或者最接近的若干个信号。或者给你两个不同模态的信号,让你判断是否相关。听着是不是有点像 metric learning,给二者找到一个度量空间,亦或是设计一个度量方式来衡量不同模态信号间的距离。好吧写到这才引出了本题目中的 metric learning~
这里解释一些名词关系,上面提到了很多 XXX learning。这些learning 之间是什么关系呢,有什么区别与联系呢?其实简单的说这些名词概念并不是同级划分的,是一个类似交叉、包含的关系。根据研究方向的侧重点不同,才有了这些概念。比如 ICLR 更多的关注 representation learning 想要得到一个信号的embedding,而 metric learning 则是一种侧重研究度量相似度的方向,那必然可以对这个 embedding 进行度量研究。同时 contrastive learning 又可以是这个方向里的一类研究方法。总之是没必要也不可能完全区分出来,一些总结会在本专题第3篇中介绍。
·两种研究套路
从上一部分的介绍可以归纳出,所谓"映射"这一跨模态检索的本质就是对不同模态的信号分别进行编码得到其语义表示 embedding,同时要建立一个度量方法用该距离来判断这些 embedding 之间的关系。
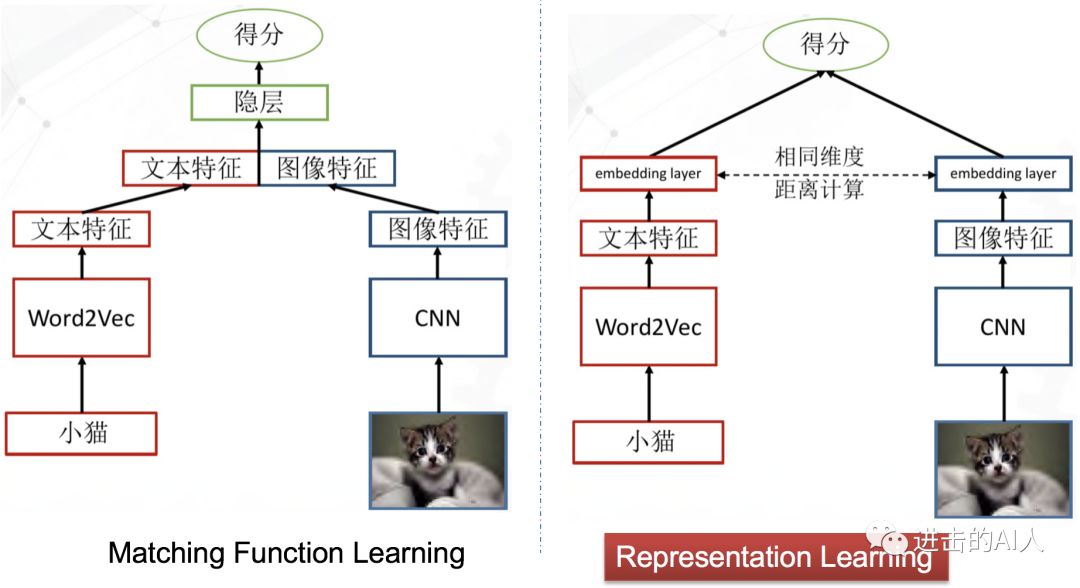
Fig. 跨模态的两种建模思路
上图是两个极其简洁的图文跨模态匹配模型。虽然简洁,但是代表了这类问题的2种研究思路。后续发展出的一堆复杂的变形金刚模型,其本质还是依照上面这2个"套路"的指导。左侧模型的思想是,图文特征先融合,然后再过隐层,让隐层来学习出一个不可解释的跨模态距离函数,最终得到一个图文关系得分。右侧模型(一般称双塔结构)的思想是,图文特征分别计算得到最终顶层的 embedding,然后用可解释的距离函数(如 cosine、L2等)来约束图文关系。
一般而言,同等条件下,左侧的模型"效果"要优于右侧的模型。因为图文特征组合后可以为模型隐层提供更多的交叉特征信息,所以一般这类模型的准确度会高一点。但是,这个模型存在致命的缺陷就是无法使用顶层 embedding 来独立表示图和文的输入信号。在一个 N 图 M 文输入的检索召回场景下,就需要 N*M 个组合输入到该模型才能得到图搜文或文搜图的结果。再者,在实际线上使用时,计算性能也是很大的瓶颈,特征组合后隐层需要在线计算。又由于交叉组合量非常大,也就无法通告提前存储图文信号的 embedding 向量来cache计算。模型设计的核心是如何交叉组合不同模态特征,属于 Matching function learning 分支。这类模型虽然效果好,但并不是研究应用的主流。
右侧的双塔模型结构是当前最主流的检索结构(阿里有 TDM),由于分隔开个图片和文本两个不同模态的信号,所以可以分别在离线阶段计算出各自的顶层embedding。存储后在线使用时,只要计算2个模态向量的距离即可。如果是pair 相关性过滤,则只要计算2个向量的 cosine/L2距离;如果是在线检索召回,则提前将一个模态的embedding 集合构建成检索空间,使用 ANN 算法去搜就行。这类方法的核心是得到高质量的 embedding,因此可以当做是 representation learning 这一分支。
双塔结构不仅仅存在于图文跨模态场景,在其他场景下也是被广泛的应用。比如广告或推荐场景,广告/内容是一个模态,用户/流量是一个模态。再比如文本相关性场景,虽然是同模态数据,但是也各自代表不同的域 domain,双塔套路依旧有效。
双塔的套路虽然简洁有效,应用广泛。但是缺点也非常明显,模型结构就能看出,不同模态的信号基本没有交互,因此往往很难学习出一个高质量的代表信号语义的 embedding。对应的度量空间/距离也就没那么准确了。
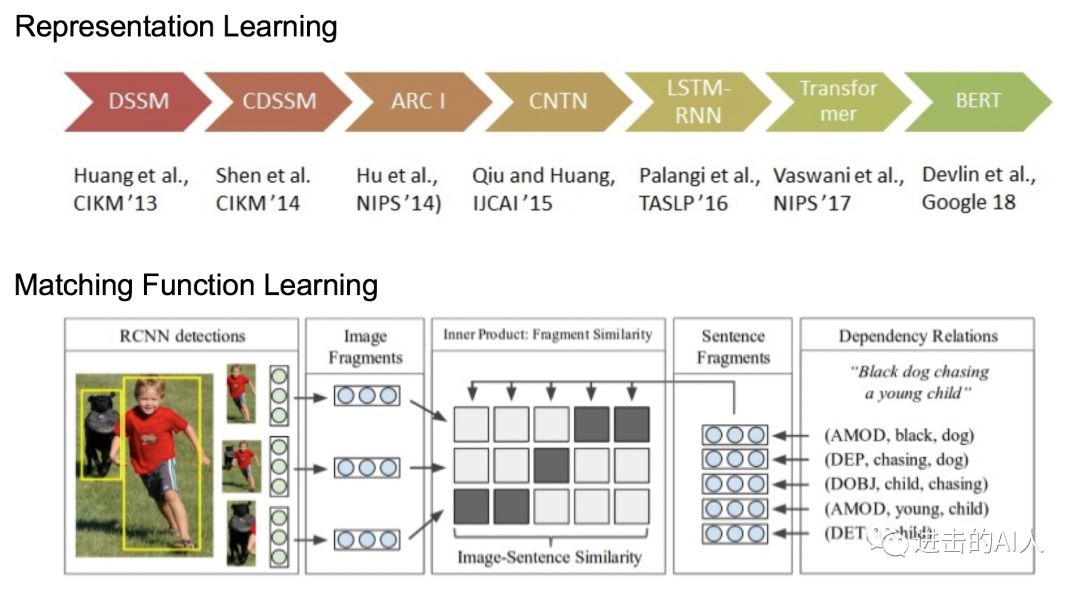
Fig. 两种研究方向的一些代表工作
上面对比了两种研究思路的优劣。在研究进展上,Matching Function Learning 这一分支会很关注细粒度的 attention和交叉特征。本文只讨论 Representation Learning 这一分支,上图可以看出这一脉络的研究工作还是很多的(不局限于双塔跨模态领域),研究者们都想找到一个方法能够将信号 embedding 化,并且这个 embedding 能完美的『代表』这个信号本身,而这些 embedding 组成的空间则能完美的『代表』这个模态空间。学过泛函分析的话,应该知道"度量空间"以及"完备"这些概念。如果真能将 embedding 构建在一个完备的希尔伯特空间中,那就真的可能是完美的了。
·实际工作中注意 Transfer Learning
目前基于有监督和无监督学习的一些里程碑的工作,已经可以很好的达到 represent 这一目的。比如 resnet、bert 可能分别是图片和文本领域中应用最广泛的 pre-trained 模型了,很多工作都是先用这俩模型得到一个 baseline embedding,然后在下游任务中重新 fine tuning 得到最终的 embedding。
Resnet、Bert 这些为各自模态内部提供了一个很高的 baseline embedding,但是想要用一个模型对多模态信号都能得到一个优秀的embedding 还是很难的。Graph 这种异构思路可以尝试,不过很依赖模态共现关系。
实际工作中,我们应重视借助 transfer learning 的能力来加速/提高模型的训练和效果。理论上,如果有足够的数据,train from scratch 也是可以的,比如文本就是用one-hot表示然后自己搞一套 word2vec。但是跨模态应用场景下,往往这种 pair 数据很难获得,因此需要更多的借助 pre-trained 模型。
在一般情况下,把跨模态匹配问题变成了一个纯粹的空间映射问题(比如2048维的 resnet 图像特征空间 VS 768维的 bert 文本输出空间),这样会简化任务,得到一个基本"能用"的结果。。。
本专题后两篇将介绍如何使用 GAN、metric learning 等思路踩在 resnet、bert 这些巨人的肩膀上来优化跨模态 embedding 的生成。更多的优化细节,可以继续关注本专题的后两部分 ~
推荐阅读
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。



