最新综述 | 强化学习中从仿真器到现实环境的迁移

©PaperWeekly 原创 · 作者|李文浩
学校|华东师范大学博士生
研究方向|强化学习
最近 survey 了一下 sim2real 领域最近的相关工作,先整理个第一版(共有七篇论文)的总结。
整篇总结分为以下四个部分:
-
问题的定义以及工作的出发点 -
方法的分类 -
具体算法 -
一个实例

问题的定义以及工作的出发点
-
采样效率太低(在用强化学习算法解决机器人相关问题时,所需要的样本量一般会达到上千万,在现实环境中采集如此数量级的样本要耗费几个月的时间) 安全问题 (由于强化学习需要通过智能体在环境中进行大范围的随机采样来进行试错,因而在某些时刻其做出的行为可能会损伤机器人自身,例如手臂转动角度过大或者避障任务中由于碰撞造成的不可逆损伤等等;也可能会损害周围的环境甚至生物)
但是如果我们在模拟器中进行强化学习算法的训练,以上两个问题均可迎刃而解。但是,这里同样会存在一个问题,由于模拟器对于物理环境的建模都是存在误差的,因而在模拟环境中学习到的最优策略是否可以直接在现实环境中应用呢?
答案往往是否定的,我们把这个问题称为 “reality gap”。而 sim2real 的工作就是去尝试解决这个问题。

sim2real 中的典型工作大致可以分为以下五类:
-
Domain Adaption 主要是通过学习一个模拟环境以及现实环境共同的状态到隐变量空间的映射,在模拟环境中,使用映射后的状态空间进行算法的训练;因而在迁移到现实环境中时,同样将状态映射到隐含空间后,就可以直接应用在模拟环境训练好的模型了。 -
Progressive Network 利用一类特殊的 Progressive Neural Network 来进行 sim2real。其主要思想类似于 cumulative learning,从简单任务逐步过渡到复杂任务(这里可以认为模拟器中的任务总是要比现实任务简单的)。 -
Inverse Dynamic Model 通过在现实环境中学习一个逆转移概率矩阵来直接在现实环境中应用模拟环境中训练好的模型。 Domain Randomization 对模拟环境中的视觉信息或者物理参数进行随机化,例如对于避障任务,智能体在一个墙壁颜色、地板颜色等等或者摩擦力、大气压强会随机变化的模拟环境中进行学习。

3.1 GDA

该论文属于 Domain Adaption 类别。

▲ 虚拟环境以及现实环境收集到的图像对比
如上图,本文的基本思想是,无论是在模拟环境还是在现实环境智能体收集的图像中,对于任务比较重要的便是一些可控制物体或者目标的位置。因而希望学到的隐含表示能够保留这部分物体的位置信息。
以上是针对图像局部信息的约束。而对于整体图像来说,本文希望模拟环境以及现实环境在这个公共的隐含表示空间中的隐含表示无法被一个二分类器所分辨出来。另外,对于一对图片,例如上图,本文希望这一对图片的隐含表示的欧氏距离能够尽可能接近。
根据以上三个约束,可以得到以下三个损失函数:
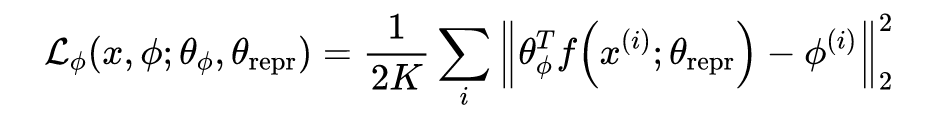
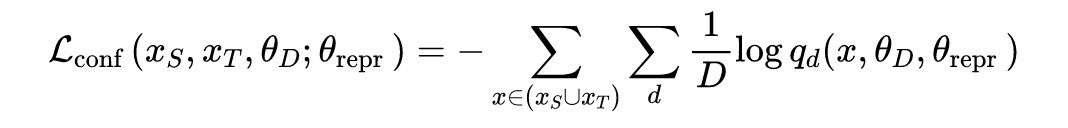
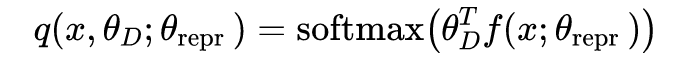
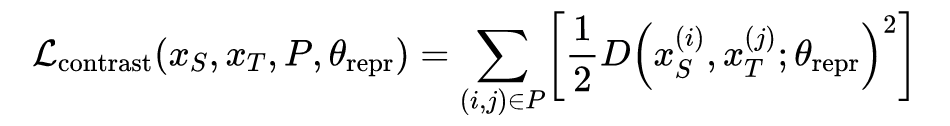
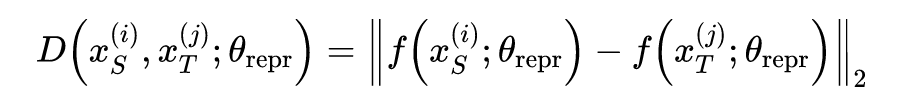

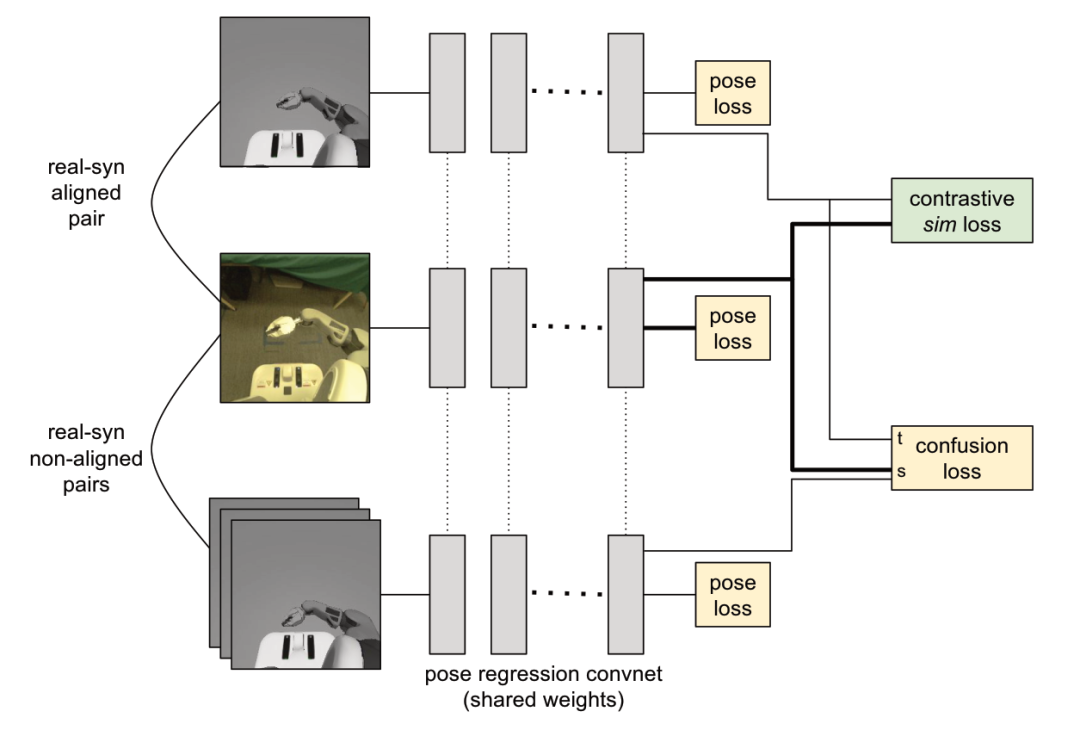
但是这种方法存在一个问题,在计算 contrastive loss 时需要使用一对在模拟环境以及现实环境中能对应上的图片。这种对应关系如果需要人工完成工作量很大而且如何去分辨两张图是否是对应关系也没有一个绝对的标准。
只使用虚拟环境中收集的图片(进行位置标记)并只是用 pose estimation loss 训练一个表示学习网络。
使用上一步训练好的表示学习网络抽取数据集中所有图片(包括仿真环境以及真实环境)的第一个卷积特征图。
对以上特征图采用 5x5 的最大池化。
为每一个仿真-现实图片对计算相似度,即计算其拉直后的特征图的内积。
-
每一张真实环境中的图片对应的虚拟环境的图片为相似度最高的那一张。
3.2 ICLR 2017

论文链接:https://arxiv.org/abs/1703.02949
这篇论文同样属于 Domain Adaption 领域,即学习一个虚拟环境以及真实环境的状态(state)的公共的隐含表示空间。其整个学习过程分为两步,第一步进行表示学习,第二步采用学习到的表示在现实环境中进行强化学习。
Assume that the reward functions share some structural similarity, in that the state distribution of an optimal policy in the source domain will resemble the state distribution of an optimal policy in the target domain when projected into some common feature space.
举个例子,我们在仿真环境中构建一个拥有两个关节的机械臂希望它能够将一个冰球推到指定位置,回报函数设计为冰球与目标位置的距离的负值;然后在现实环境中,我们拥有一个有三个关节的机械臂去完成同样的任务。
在这个例子中,虽然从智能体获得的图像表示完全不同(一个两关节一个三关节),但是回报函数其实是一样的,与关节数目没有关系。当然这是一个比较极端的例子,回报函数可以不完全一样。
所以本文的目标是学习两个映射函数,能够将两个环境中的状态映射到一个共同的隐含表示空间,这与上一篇论文只有一个公共的映射函数不同:
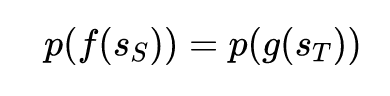
仿真环境以及真实环境的智能体需要学会完成同一个任务
-
动作空间一致,状态空间的维度一致
另外对于第二个假设,如果仿真环境以及现实环境中使用的是同一款机器人或者机械臂,动作空间一致以及状态空间的维度一致是一个非常自然的假设。
要进行如上公式所示的表示学习,我们首先需要对两个环境中的状态(学会的共同任务中的状态)进行对齐(与上一篇论文里的对齐意义是一样的),这里存在两种方法进行对齐:
-
Time-bases Alignment -
Dynamic Time Wrapping
这个方法主要在于如何去选择这个距离函数,本文的做法是首先用 time-bases alignment 方法得到一个初始的对齐方式,再使用下面要讲到的表示学习的方法学习两个映射函数,将整个序列每一对对齐状态映射后隐含表示向量的欧氏距离的和作为 dynamic time warpping 方法中序列相似度的距离函数。
以上就是状态对齐步骤,下面就要进行正式的表示学习了。我们注意到,对于以上公式,其实有个非常简单的解,即这两个映射函数的是个输出永远为 0 的常数函数。
这样一个解显然不是我们需要的,因为我们可以加上一个约束,即学习到的隐含表示能够尽可能多的保留原表示的信息,即学习到的隐含表示是一个 auto encoder 的隐向量。根据以上假设以及我们的优化目标,可以得到如下表示学习损失函数:
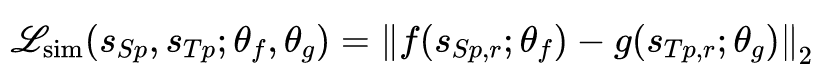
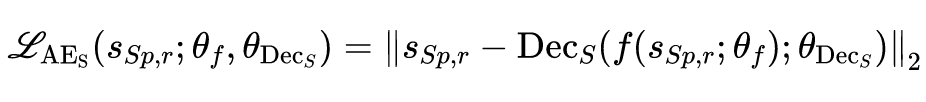
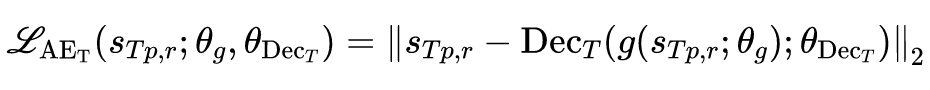
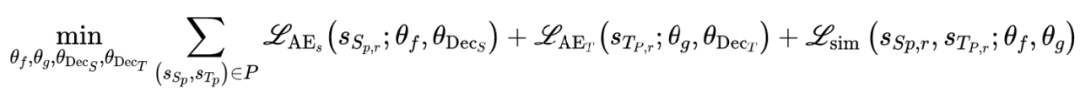
同样给出一个更容易理解的框架图:
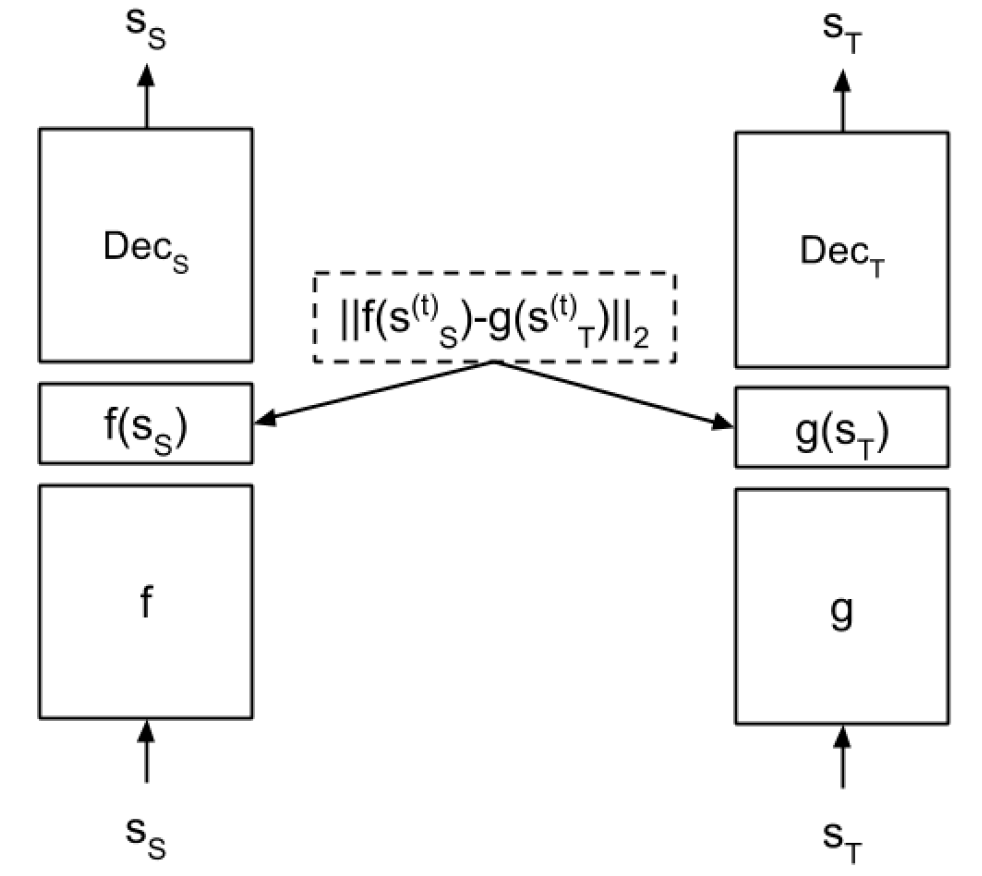
3.2.2 知识迁移
在进行了第一步的表示学习后,我们需要利用学习到的表示在现实环境中进行新任务的训练。
但是注意,我们学习的表示是经过如下两个约束学到的,第一个约束可以认为是一个 auto encoder 的降维;第二个约束是能够与模拟环境最优策略产生的状态概率分布相同的一个隐含状态表示空间。
因而我们不能单单只利用学习到隐含表示去在现实世界中训练,这样在模拟环境中训练好的策略没有办法对现实任务的训练造成任何影响,这个影响必须通过将现实任务的状态序列与模拟环境中最优策略产生的状态序列对齐后才能够实现。
本文通过对现实环境中智能体需要解决的任务的回报函数的基础上加上如下附加项来实现知识迁移:
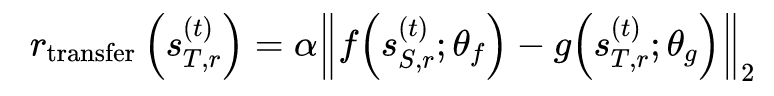
3.3 CoRL 2017

论文链接:https://arxiv.org/abs/1610.04286
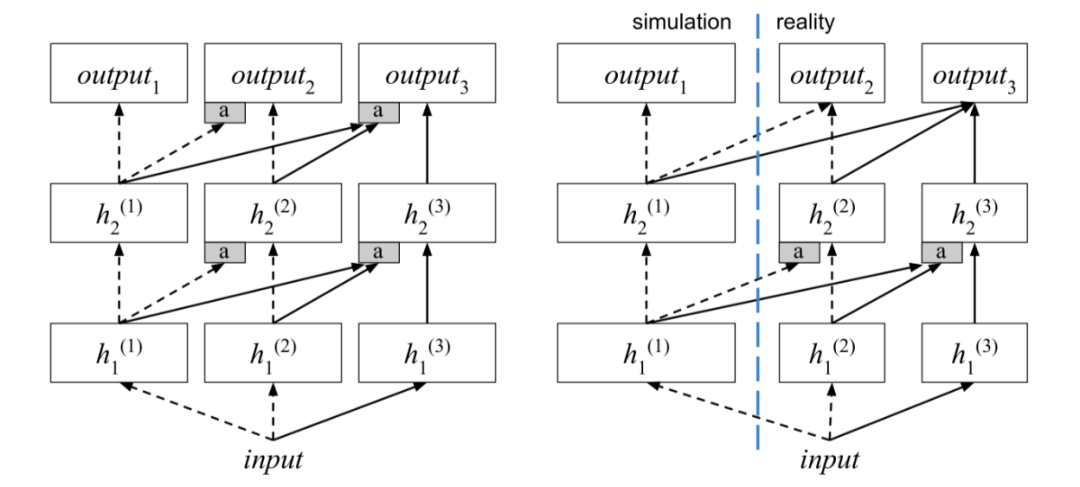
左图中每一列(column)代表一个独立的任务,任务训练顺序从左到右。虽然任务训练顺序从简单到复杂从直觉上来看是比较合理的,但是 PNN 并不一定要满足这个规律, 其任务训练顺序可以是任意的。
-
现实环境中使用的神经网络要比模拟环境中要小。原因主要是由于原 PNN 论文发现,当列数越多时每一列网络的参数都很稀疏,完全可以进行网络压缩或者剪枝。 -
输出层不再接受前置任务的输入。由于模拟环境与现实环境在动作空间上可能存在差异,因而在输出层借鉴前面任务的知识反而容易产生误导。 为了让智能体在现实环境中训练所需的样本量更小,因而输出层的参数直接复制之前任务的参数用来初始化,用以提升算法训练初期的探索度。
3.4 Christiano et al.

论文标题:Transfer from Simulation to Real World through Learning Deep Inverse Dynamics Model
本文属于 Inverse Dynamic Model 类别。其主要基于的假设是即使虚拟环境无法对现实世界进行完全准确的建模,但是其状态的变化还是合理的。
例如,对于一个将物体推到指定目标位置的任务来说,一个机械臂将冰球往前推那么下一个状态就是冰球往推动方向前进一些,但是不会往相反的方向移动。
基于这个假设,首先在虚拟环境训练好一个策略,其输入是前 n 个时间步的状态(这里同样考虑到部分观察的问题),将输出的动作输入到虚拟环境模型中,就会转移到虚拟环境中的下一个状态。
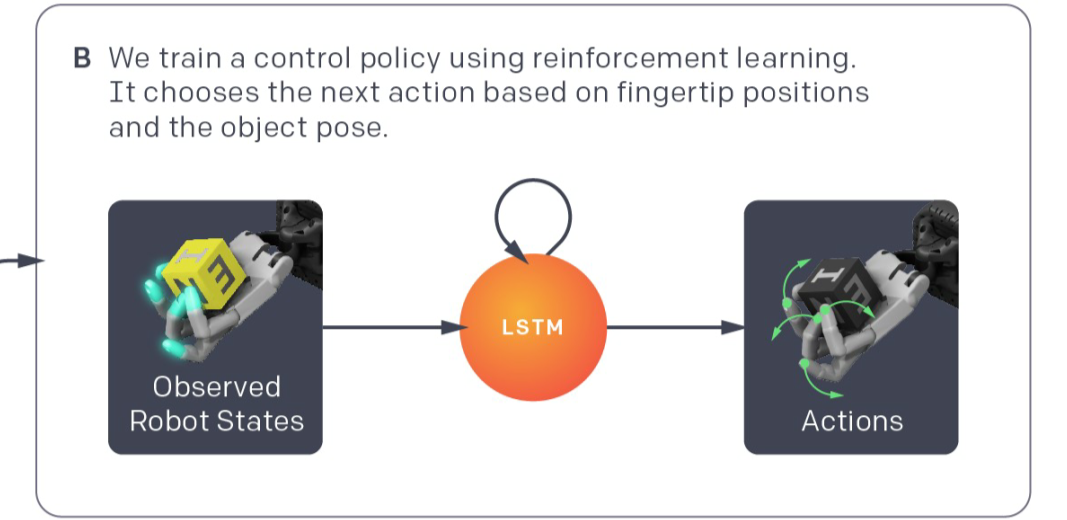
将这个状态与现实环境中的前 n 个时间步的状态输入到真实环境中学习到的逆动态模型中,就会得出能够输出这下一个状态所需要采取的动作。具体见下图:
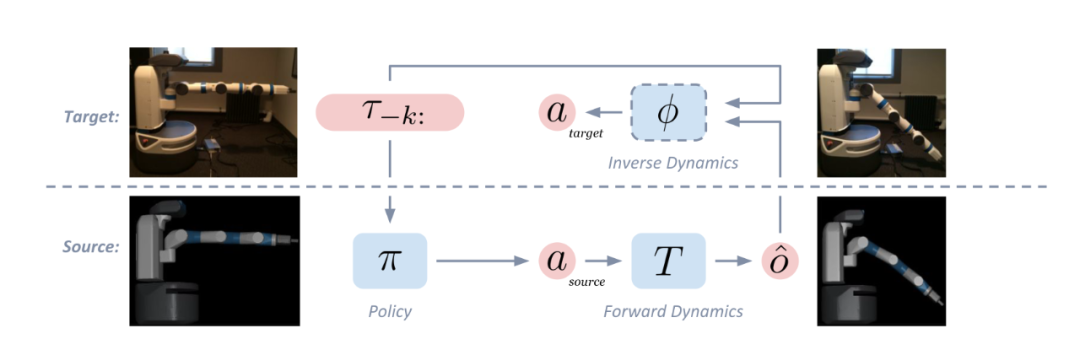
以上过程唯一需要详细说明的便是如何在现实环境中学习一个逆动态模型,其实非常简单:
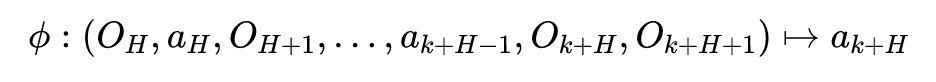
-
不需要每个时间步都加入噪声。 -
当现实环境中智能体执行动作发生状态转移时转移到一个与虚拟环境差别很大的状态时,就应当即时停止这一轮的采样。
3.5 ICRA 2018

本文属于 Domain Randomization 类别。本文出发点在于深度强化学习算法具有以下特性:
DeepRL policies are prone to exploiting idiosyncrasies of the simulator to realize behaviours that are infeasible in the real world.
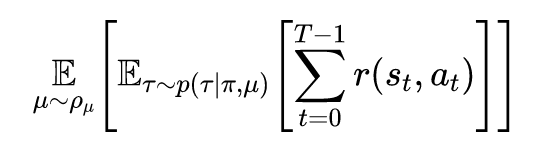


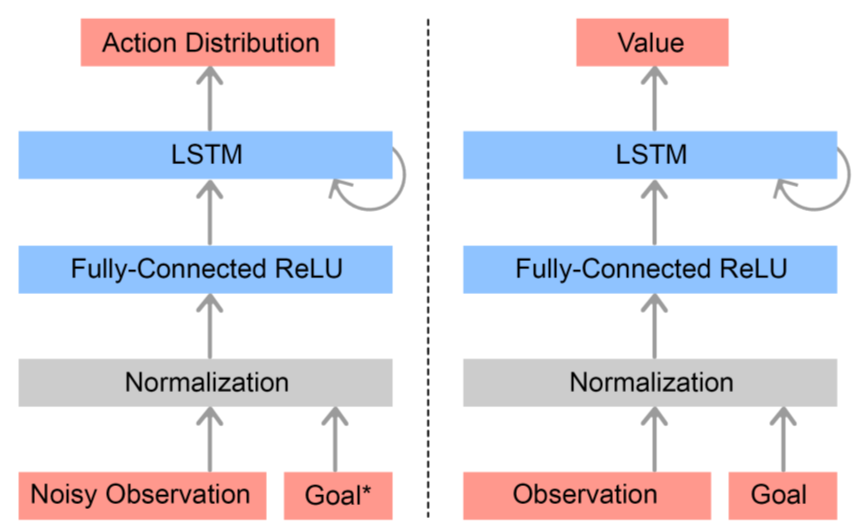
其中的策略网络以及值函数网络采用如下方式进行建模:
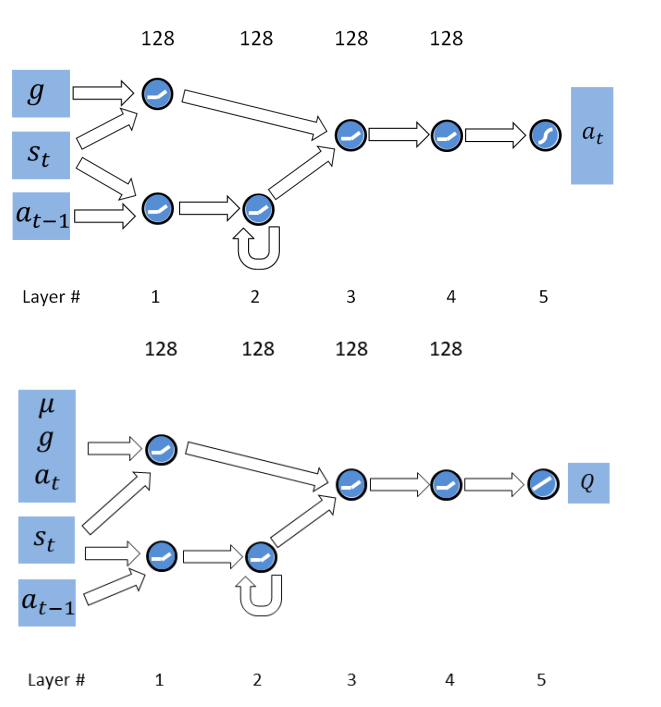
3.6 IROS 2017

论文标题:Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World

具体需要随机化的视觉信息包括:
-
桌子上所有目标物体的位置以及纹理 -
桌子、地板、背景以及机械臂的纹理 -
摄像机的位置、朝向以及可视范围 -
场景中光源的数量 -
场景中光源的位置、朝向以及光谱特征 -
加入到图像中噪声的类型以及数量


为了建立一个足够精细(但是依旧存在无法建模的物理量)的虚拟环境,OpenAI 以机械手为球心半径为 80 厘米的球面上均匀分布了 16 个精度为 20 微米的追踪器,能够定位机械手任意位置的微小位移。
之所以采用如此高精度的追踪器是为了尽可能准确地对机械手的相关物理参数,例如手指关节处的阻尼等等,这样的物理参数有将近 500 个。

▲ 真实环境 vs 虚拟环境
整个系统的训练步骤大致可分为以下三个部分(最后是训练完毕的执行部分):
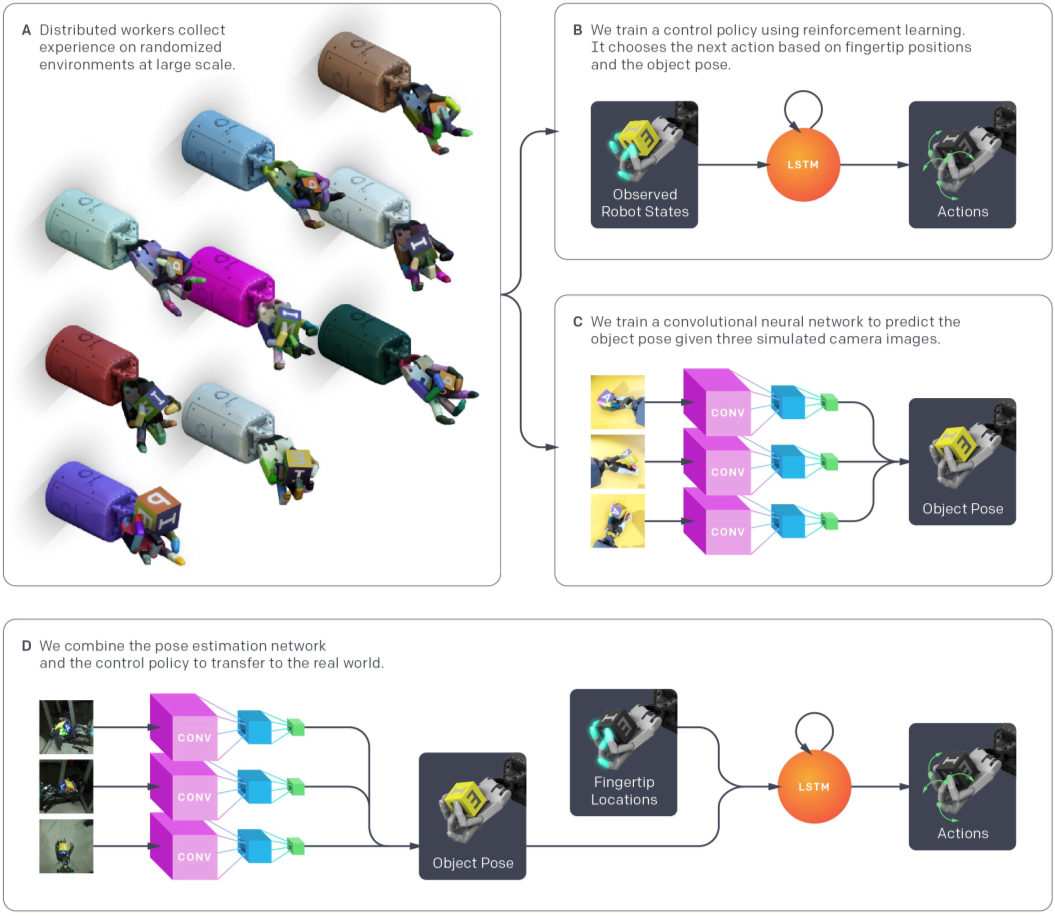
▲ 系统流程图

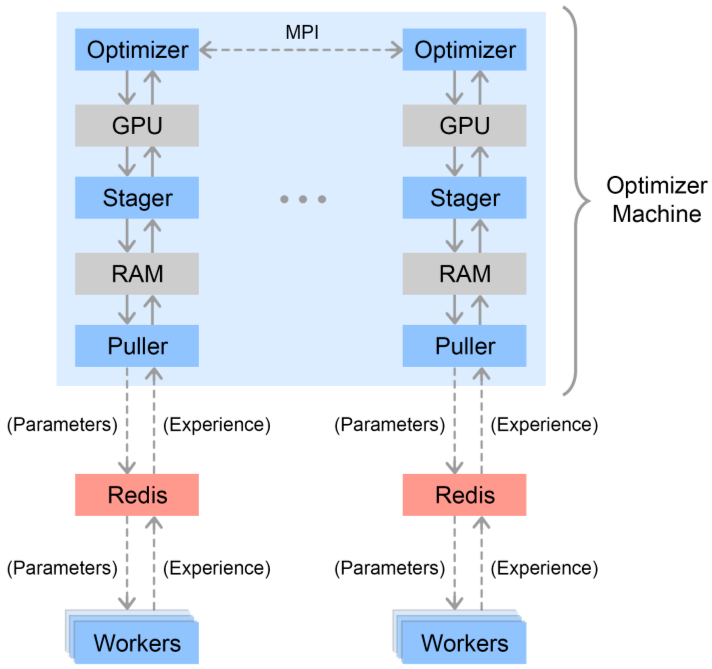
上图中采用的分布式数据收集以及模型训练框架同样也是 OpenAI Five 所采用的。
从左下方开始,多个并行采样的 worker 会将自己根据当前策略采集的样本发送给与自己相关联的 Redis 服务器上,模型更新模块中的 Puller 将会定期异步地从 Redis 服务器中拉取一个 batch 的数据并放到 RAM 中。
之后 Stager 从 RAM 中拉取一个 mini-batch 放到 GPU 上,与其他采用 MPI 协议联系的 GPU 一起对参数进行更新。
更新后的参数将每个 Optimizer 都保存一份。之后 Optimizer 沿着之前相反的路径将更新后的参数存储到 Redis 服务器上,workers 将定期异步地从 Redis 服务器上拉取最新的策略参数进行采样。整个训练过程就是以上过程的迭代。
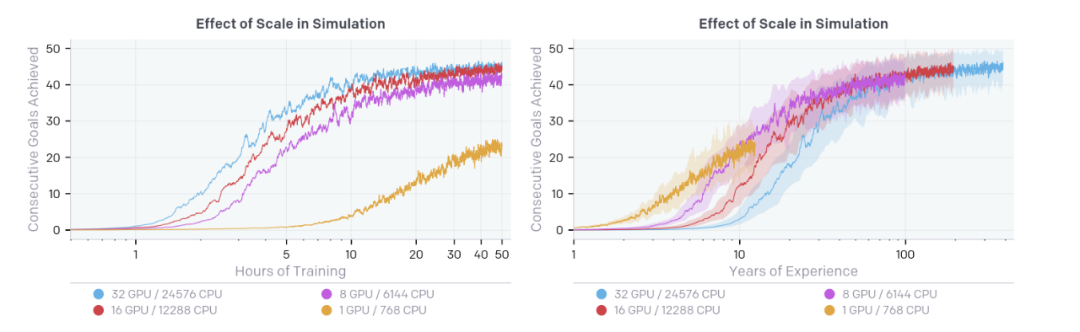
▲ 状态空间
-
Dynamic Randomization -
Domain Randomization -
Unmodeled Effects Randomization
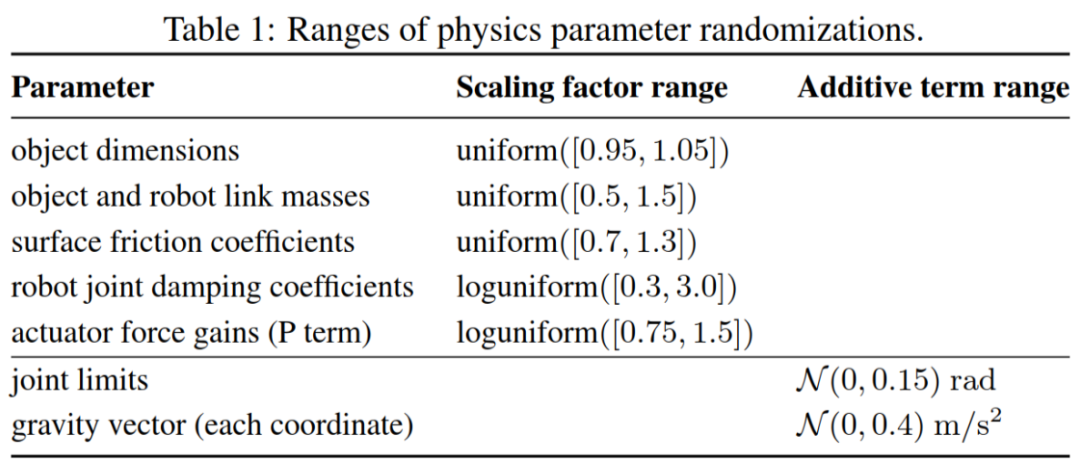

▲ Domain Randomization

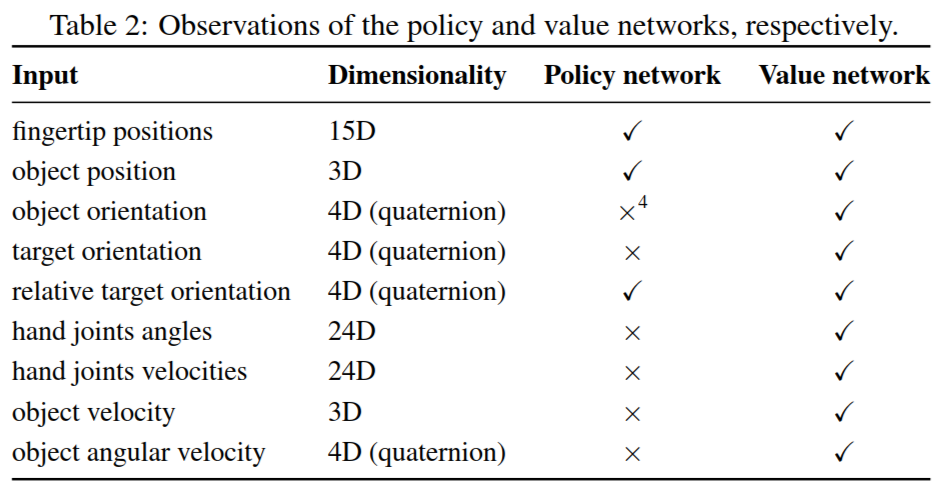
最后一部分,由于机械手的任务不应该局限于转动方块,还应该包括操纵其他物体。而且由第二部分可知策略网络以及值函数网络的输入可知需要立方体的朝向以及位置信息,目前是通过 16 个高精度追踪器确定的。
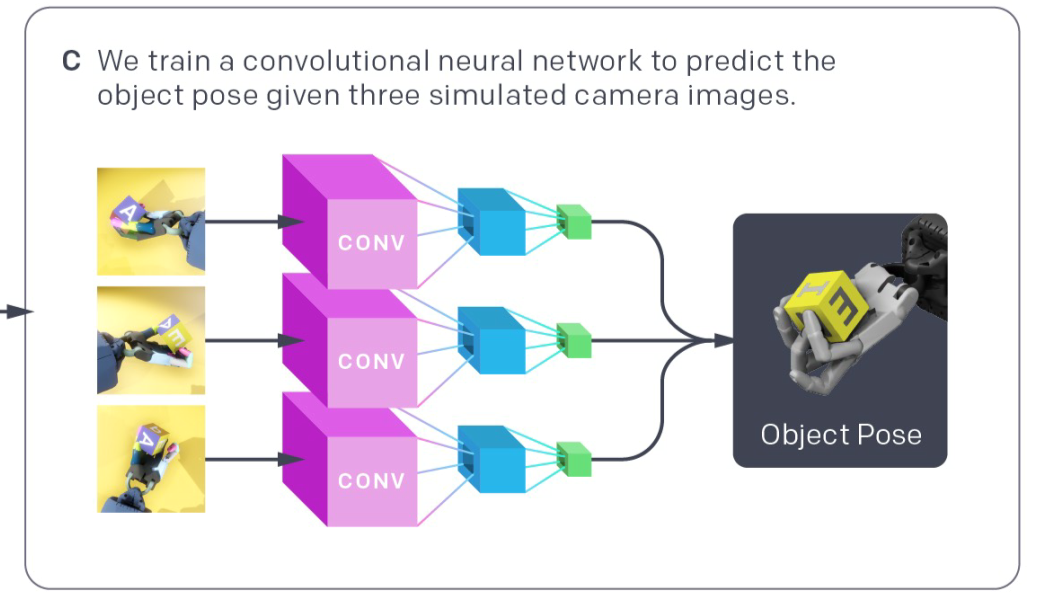
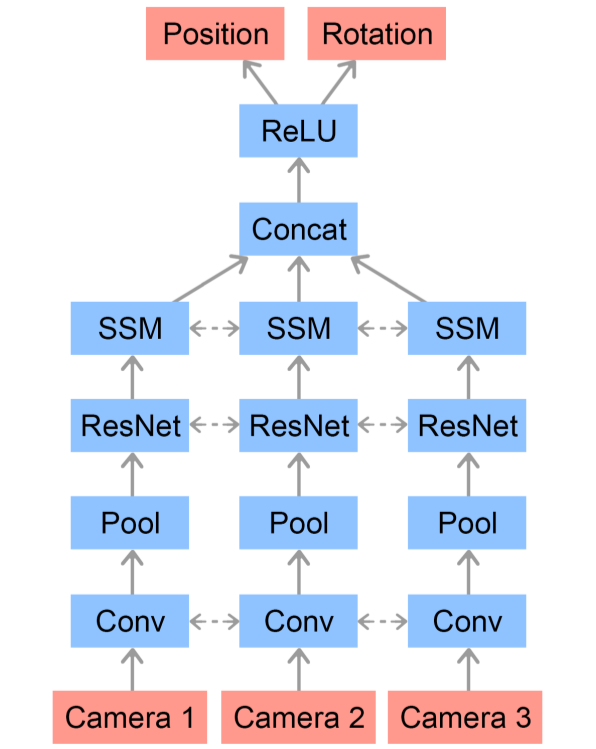
▲ Pose Prediction Network Architecture

点击以下标题查看更多往期内容:

#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。





