赛尔原创 | AAAI 2019 动词短语省略恢复:一种神经网络方法
论文名称:A Neural Approach for Verb Phrase Ellipsis Resolution
论文作者:张伟男,张岳,刘元兴,狄东林,刘挺
原创作者:哈工大 SCIR 本科生胡景雯、硕士生刘元兴
摘要
动词短语省略(VPE)是一种语言现象,表现为句子中省略一些由辅助动词指示的动词短语。这种现象在正式和非正式的文本中都是普遍存在的,比如新闻和对话。先前的相关工作主要集中在从辅助动词和句法树等资源中手动构建特征。然而,先前的工作并没有很好地解决特征表示的优化,连续特征的有效性和特征的自动组合等问题。在本文中我们探索神经网络模型对动词短语省略恢复任务(包括管道和端到端过程)的优势,并比较统计模型和神经网络模型之间的差异。我们使用两种神经网络模型(MLP 和 Transformer)分别进行动词短语省略恢复的两个子任务:VPE 检测和 VPE 消解。实验结果表明,神经网络模型在子任务和端到端过程的结果均优于最先进的基线。
1 引言
省略是一种语言现象,一些句法成分被省略但是能从上下文中恢复出来。动词短语省略(VPE)是语言省略现象的一种,指的是动词短语的省略。在英语中,VPE 通常指辅助动词没有动词短语的情况。例如,在句子 “Not only is development of the new company’s initial machine tied directly to Mr. Cray, so is its balanced sheet.” 中,动词短语 “tied directly to Mr. Cray” 是 “its balanced sheet” 在辅助动词 “is” 的指示下被省略的内容。在上述例子中,辅助动词通常被称为触发词,被省略的动词短语被称为先行短语。和动词短语省略恢复关联的 NLP 任务 [8, 19, 22, 23] 有两个:
VPE 检测,检测出触发词
VPE 消解,判断给定触发词的先行短语
图 1 是一个动词短语省略恢复过程的例子。

图 1. 一个动词短语省略恢复过程的例子,其中”is“是 VPE 的触发词,括号中的 VP “tied directly to Mr. Cray” 是 VPE 的先行短语。
VPE 经常发生在正式和非正式的文本中,比如新闻和对话 [22]。因此,动词短语省略恢复对于下游的 NLP 任务非常重要,例如事件抽取,对话系统等等[14]。动词短语省略恢复的先前工作分别解决了 VPE 检测([8, 9, 11, 19, 20, 21] 和 VPE 消解 [10, 18, 22, 4] 的子任务, 管道处理 VPE 检测和 VPE 消解 [3, 5, 13, 16, 2], 并且端到端建模了两个过程[14, 17]。现有的很多工作使用了启发式的规则,从助动词和句法结构中人工构建的特征和语言理论例如 DRS[5],SPC[17] 等等。尽管现有的工作已经取得不小的成功,但是启发式规则和人工构建的特征很稀疏,不能通过一个句子完全探索深度语义信息。我们可以通过使用神经网络模型解决这个问题[7]。
在本文中,我们探索了管道和端到端过程中动词短语省略恢复的神经网络模型。并且在研究新型词法特征和槽模式特征中比较统计模型和神经网络模型。对于 VPE 检测,我们选择使用非线性的核函数的 SVM 模型作为先进的统计模型,选择 MLP 和 Transformer 作为我们的神经网络模型。对于 VPE 消解,我们应用 MLP 和 Transformer 模型。最后,对于动词短语省略恢复任务,我们提出一个新型的端到端神经网络框架来统一地结合两个子任务。
WSJ 数据集的结果 [3] 显示我们提出的神经网络模型比其他最先进的基线效果好。除此之外,我们通过标注数据进一步分析了动词短语省略现象的分布。动词短语省略现象可以分为以下四类:
有触发词,有动词短语省略
有触发词,没有动词短语省略
没有触发词,有动词短语省略
没有触发词,没有动词短语省略
我们开源了扩展语料以及动词短语省略恢复研究的代码。(点击文末阅读原文可获取代码)
2 相关工作
VPE 检测: [8]提出三阶段算法,包括在 VPlist 和 VPE 上的移除,分配和挑选。[9]第一个进行 VPE 检测研究。他们应用了基于句法的匹配模式并且提出四种偏向因素来判断 VPE。[11]在论述中引入一种平行理论来分析 VPE 现象。[19]验证了不同的统计机器学习方法的结合在 VPE 检测上的效果。[20, 21]验证了 VPE 检测(或者目标检测)在自动解析的数据上的表现并且构建了一个健壮的、准确的、领域独立的 VPE 检测系统。虽然我们在使用词法和句法的特征时沿用了 [9, 20, 21] 的方法,但是我们是第一个在 VPE 检测方面使用神经网络模型探索句子级别的更深的语义信息的工作。
VPE 消解:[10] 应用一个基于转化学习的方法来生成 VPE 消解的模式。[18] 第一个提出基于语料的方法来解决 VPE 消解。并且提出了一个管道框架,包括 VPE 检测,先行短语判定和 VPE 消解。[4] 通过样例分析研究了 VPE 和粗略判定。前人的工作使用统计特征,然而我们使用神经网络模型来优化 VPE 消解的特征表示和组成。
尽管在 BNC 数据集上面有一些 VPE 检测和消解的研究,但是由于 BNC 数据集依赖于预处理的一些特定的工具集 [14],所以很难去使用 BNC 数据集。最近,[3] 扩展并开源了一个从 WSJ 数据集的 25 个章节产生的 VPE 标注语料。[5]应用 DRS 来解决 VPE 检测,定位和消解任务。[13]分析了 VPE 一致条件并且为不加区分的条件提供了初步的构想。[16]探索了 VPE 的不同步骤并且将目标检测和先行短语的识别分割成三个任务,即目标检测,先行短语头部消解和先行短语边界确定。[2]提出一个框架将比较和省略建模成一个谓语参数的互联结构。[17]考虑了 VPE 检测和消解的句法并行性,模态相关性和句子成分。[14]探索了三方面的特征(辅助动词、词法和句法)并提出了一个基于 MIRA 方法的对齐算法来解决动词短语省略恢复。前人的工作在两个分开的任务上和端到端任务上,集中于启发式规则和在统计模型下人工构建的特征。对比之下,我们的工作在三个任务上探索了神经网络模型建模句子深度语义的优点。
3 本文方法
如图 2 所示,我们研究了一种端到端的学习框架将 VPE 检测和 VPE 消解整合到一起。对每个子任务,我们提供了可替换模型。例如,对于 VPE 检测,分类器可以是 SVM、MLP 或者 Transformer。对于 VPE 消解,模型可以是 MLP 或者 Transformer。
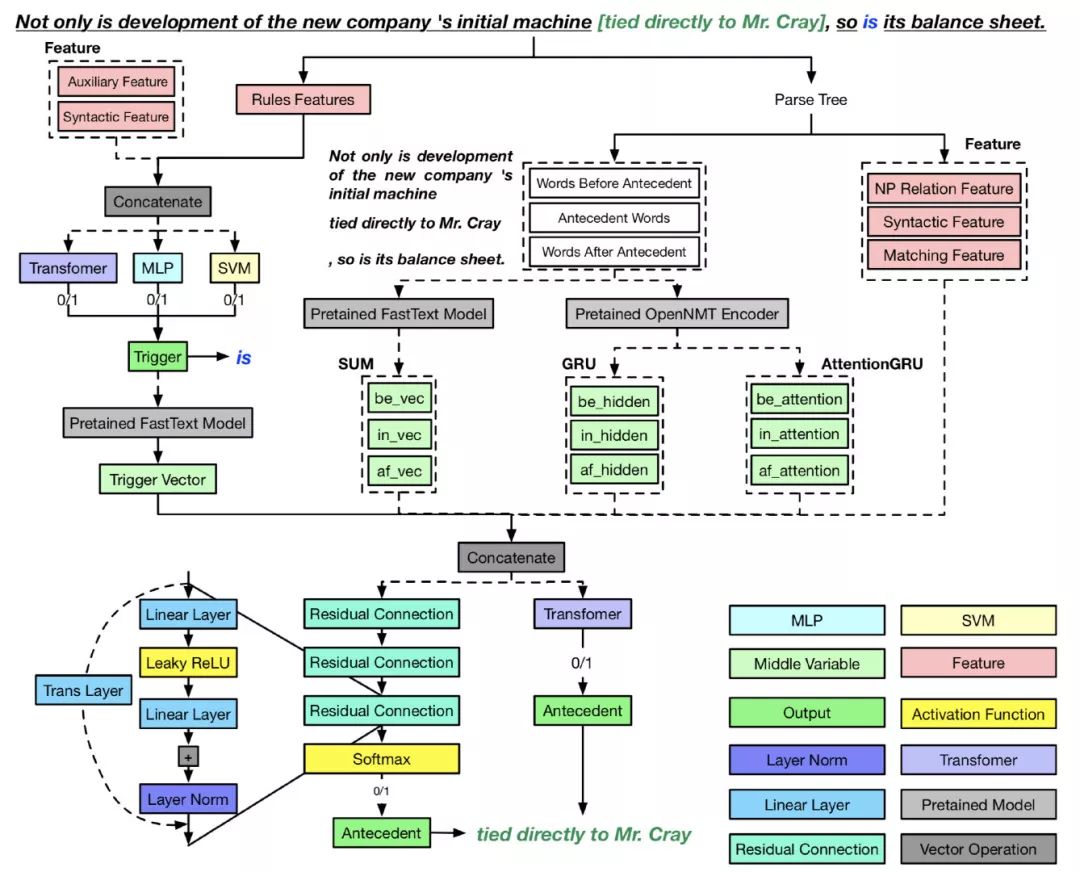
图 2. 我们提出的动词短语省略恢复端到端方法的框架
3.1 VPE 检测
在本文中,我们沿着之前的研究 [19, 20, 21, 22, 5, 16, 14] 把 VPE 检测当作一个关于触发词的二分类任务。给定一个辅助动词和辅助动词所在的句子作为输入,VPE 检测任务是提取特征和预测辅助动词是否是触发词。
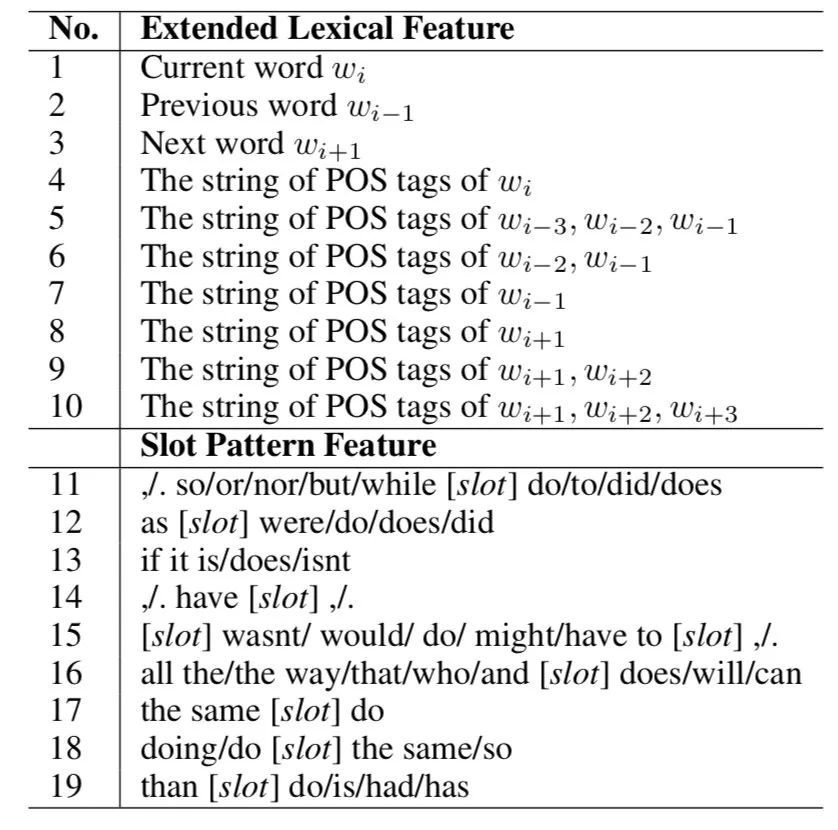
对于 VPE 检测,我们使用了 [14] 提出的特征,并且提出了一系列新特征。表 1 总结了从 [14]] 扩展的词法特征和槽模式特征。对于扩展的词法特征,我们的目标是捕获单词(No.1-3)和 POS 标签(No.4)的语义分布以及 POS 标签的顺序上下文信息(No.5-10)。对于槽模式特征,我们提出探索辅助相关的句法结构。 槽用来泛化匹配的范围。No.11-16 与助动词有关。No.17 和 18 是针对特定现象 “the same” 的参考,而 No.19 是针对 “comparative deletion” 的现象。[11]对这两种现象进行了探索。
表 1. 用于 VPE 检测的建议的扩展词汇特征和时隙模式特征的总结
我们比较了 SVM 和基于注意力机制的神经网络模型的有效性。 对于 SVM 分类器,我们使用 scikit-learn 对训练和测试进行了 5 折交叉验证。对于基于注意力机制的神经网络模型,我们采用了 Transformer[24]。Transformer 模型的数据拆分和特征输入与 SVM 分类器相同。
3.2 VPE 消解
VPE 消解被定义为动词短语和副词短语的二分类任务。形式上,给定一个句子,让 

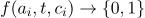
其中 1 表示候选先行短语

图 3. VPE 训练数据示例,方括号中的 VP 表示候选先行短语
表示学习:为了获得
Sum Pooling:直接对
,
和
的词向量求和,以获得联合表示。
和
分别表示第
个候选先行短语和第
个上下文中的第
个和第
个词的向量。
GRU:使用两个单独 GRU[6] 模型的最后隐层状态的输出来表示
和
。GRU 模型的输入是词向量。我们使用
来表示候选的先行短语,触发词和上下文的词向量。最初,对于
,输出向量是
。GRU 模型可以表示为:
这里
,
,
,
分别表示输入向量,输出向量,更新门和重置门。
和
是参数矩阵,
是偏差。
和
分别代表 sigmoid 函数和双曲正切函数。
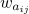
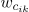
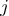
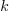
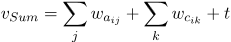
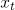
 ,输出向量是
,输出向量是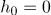 。GRU 模型可以表示为:
。GRU 模型可以表示为: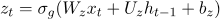
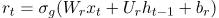
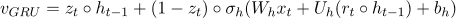
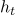
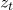
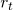
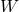
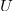
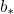
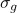
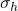
基于注意力的 GRU[1]:使用两个单独的 GRU 模型上每个隐层状态的加权求和输出表示
和
。给定词向量
这个词,我们计算每个词和最后一个词之间的相似度:
 这个词,我们计算每个词和最后一个词之间的相似度:
这个词,我们计算每个词和最后一个词之间的相似度: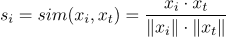
然后,我们计算每个词的注意力(权重)。
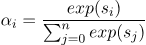
最后,句子的向量表示 $v_{AttGRU}$ 的计算公式为:
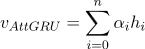
其中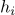
神经网络模型: 对于 VPE 消解,我们使用了两个神经网络模型。第一个 VPE 消解模型是 MLP。 线性层定义为:
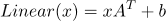
其中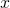
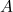
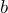
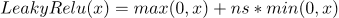
其中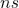

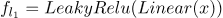
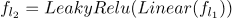
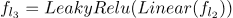
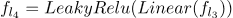
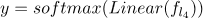
其中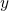
第二个 VPE 消解模型是 Transformer 模型 [24],它基于自我注意力机制。在我们的任务中,我们将二分类过程建模为基于自注意的编码器,如下面公式所示。
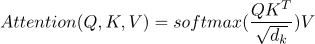
这里,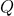
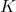
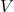
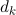
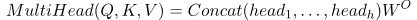
其中
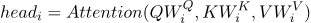
这里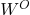
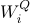
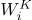
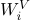
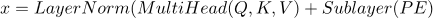
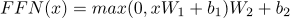
其中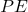
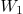
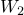
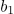

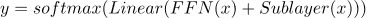
其中线性函数的形式类似于下面等式但具有不同的参数。
除了通过表示学习获得的密集表示特征之外,神经网络模型还可以利用手动特征,也可以使用依赖于专家经验的手动构建的特征。 除了神经网络特征外,我们还整合了 [14] 的特征。
4 实验
我们在标准基准数据集上进行实验,以验证神经网络模型的有效性,3 个方法在获得上下文表示方面的性能,以及传统手动特征对改善神经模型性能的实用性。 我们手动标注了 820 个句子来分析额外的 VPE 现象,并将标注的句子作为扩展数据发布。
4.1 数据集
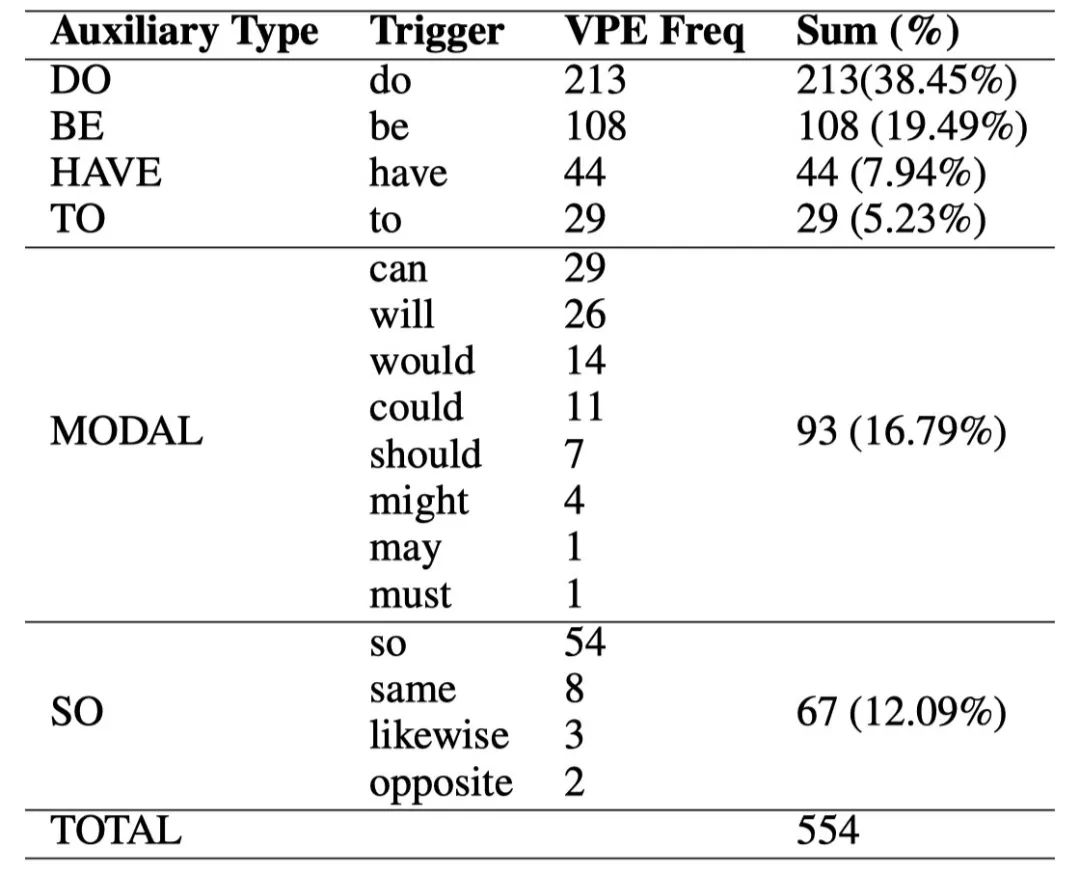
我们使用 [3] 发布的数据集。 我们沿着之前的设置 [14] 将助动词分为六种类型,包括 DO,BE,HAVE,TO,MODAL 和 SO,如表 2 所示。对于 VPE 检测任务,训练集包含 554 触发词作为正实例和 554 句子。 对于 VPE 消解任务,我们首先使用 Berkeley parser 获取每个句子的句法树。 然后我们使用 NLTK 提取句子中的所有动词短语(VP)和形容词短语(ADJP)作为 VPE 的候选先行短语。 训练集还包含 554 个句子,其中正确的先行短语为正实例,其余随机抽取提取的 VP 和 ADJP 先行短语为负实例。
表 2. 实验数据集中助动词和相应触发词和 VPE 的统计。 Auxiliary, Trigger 和 VPE Freq 分别表示助动词类型,触发词和 VPE 频率
4.2 基线
分别为 VPE 检测和 VPE 消解选择了三种最先进的基线。 对于 VPE 检测,前两个基线包括基于规则的方法(Rule)和基于机器学习的方法(ML)。 两者均由 [14] 提出。 第三个基线是 [16] 提出的三步法,包括 VPE 检测,先行短语识别和 VPE 消解。
对于 VPE 消解,第一个基线是 [6] 提出的基于 DR 理论的 VPE 消解方法(DRVPE)。 第二种是 [14] 提出的基于 Margin-Infused-Relaxed-Algorithm 的方法(MIRA)。 第三个是 [16] 提出的的三步 VPE 消解方法。 我们直接使用 [14, 16] 的 VPE 检测和 VPE 消解的实验结果进行比较。
4.3 参数设定
VPE 检测:对于 SVM 模型,超参数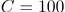
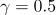
VPE 消解:对于 MLP 模型,批训练大小等于 64,学习率和重量衰减均为 0.005。 我们使用交叉熵损失函数和 Adam 优化器 [15]。 对于 Transformer 模型,我们使用[25] 中的默认参数设置,除了 beam size 等于 4 并且长度损失
4.4 结果
VPE 检测:根据训练和测试数据的划分,我们有两个实验设置。我们从表 3 中可以看出,ML 和 SVM 具有相当的性能,其中 SVM 模型使用的是我们提出的特征。在具有相同的特征的情况下,Transformer 模型优于 ML 和 SVM 模型,证明神经网络模型(Transformer)可以更好地探索特征组成并提高预测性能。
表 3. 通过 5 折交叉验证获得的 VPE 检测的 F1 得分。Rule 和 ML 是基线。SVM,SVM + F,MLP,MLP + F,Transformer 和 Transformer+ F 是 VPE 检测的方法。 †和‡表示实验结果分别对 Rule,ML 的结果在统计上显著,p <0.05。粗体结果表示最佳性能。
除了表 1 中提出的特征之外,为了进行实证比较,我们还整合了 [14] (ML) 提出的特征,用 F 表示。通过集成 ML 模型使用的特征来改进 SVM 和 Transformer 模型, 我们可以看到两者的表现。我们得出结论:
[14] 提出的特征可以集成到神经网络模型(Transformer)中,进一步提高 VPE 检测的性能;
在 VPE 检测任务上,通过比较 SVM + F 和 Transformer + F 的性能,发现神经网络模型(Transformer)可以比统计模型(SVM)更好地利用这些特征。
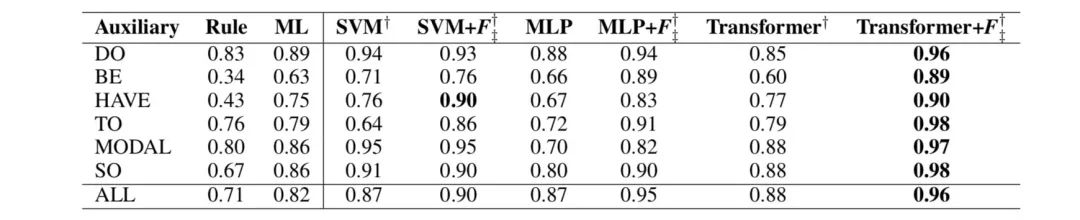
我们还比较了 [3, 16, 14] 使用的训练 - 测试数据分割中 VPE 检测的精确率 (P),召回率(R) 和 F1 得分(F)。实验结果如表 4 所示。我们可以看到 SVM,MLP 和 Transformer的表现优于基线模型(规则和 ML)。它再次验证了 [14] 提出的特征可以进一步提高统计模型和神经模型的性能。
表 4. 使用 [3] 的训练和测试数据分割获得的 VPE 检测的精确率 (P),召回(R) 和 F1 分数 (F)。 †和‡表示结果在 Liu et al. (2016))[16] 和 ML[14]的基线上有显著性提升,p <0.05。 粗体结果表示最佳性能。
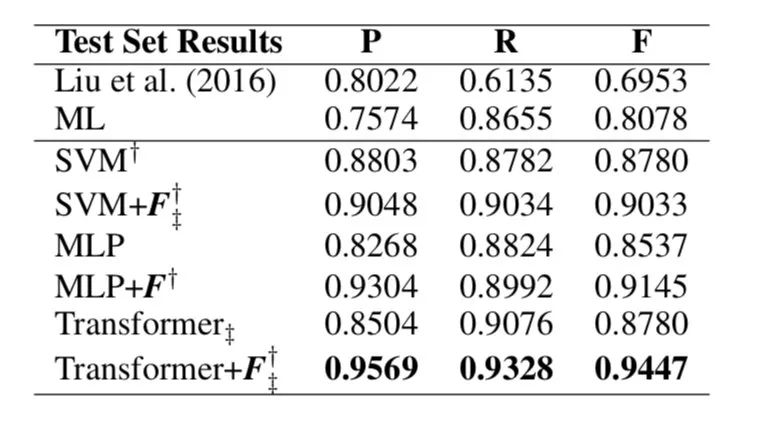
VPE 消解:我们遵循 [14] 关于训练和测试数据分割的设置。如上一节所述,使用三个不同的方法获得先行短语
表 5. 通过 5 折交叉验证获得的 VPE 消解结果。 这里,DRVPE 和 MIRA 是两个基线。 Sum,GRU 和 AttGRU 分别表示三种编码机制,即 sum-pooling,GRU 和基于注意力的 GRU。 Sum + F,GRU + F 和 AttGRU + F 分别代表具有手动构造特征的三种编码机制。 †和‡表示性能在 DRVPE 和 MIRA 的基线上分别有显著性提升,p <0.05。 粗体结果表示最佳性能。
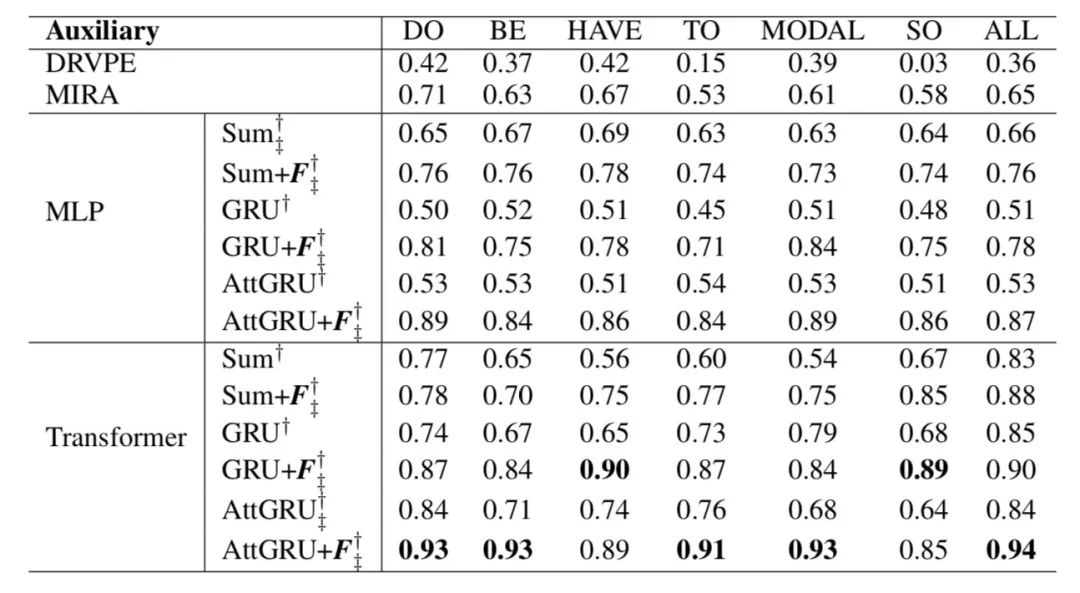
与 VPE 检测实验类似,我们还比较了 [3, 16] 使用的训练和测试数据分割中 VPE 消解的精确率 (P),召回率(R) 和 F1 得分(F)。实验结果如表 6 所示。我们发现 MLP 在三个不同的方法中显著优于基线,即 Sum Pooling,GRU 和 Attention-based GRU。Transformer 的表现在 F 值上也优于基线。它再次验证了特征 F 可以进一步提高 MLP 和 Tranformer 模型的性能,以实现端到端的动词短语省略恢复。
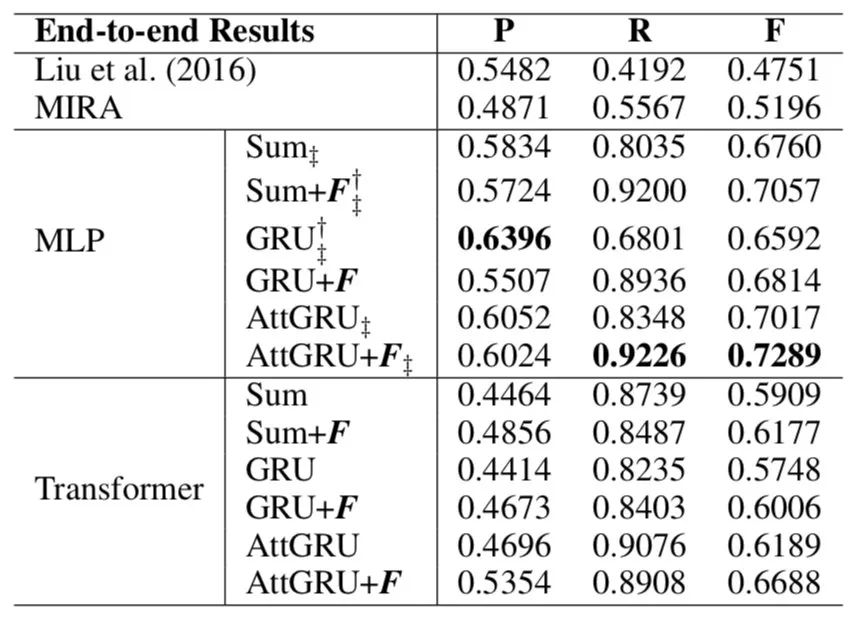
表 6. 使用 [3, 16] 的训练和测试数据分割获得的 VPE 消解的精确率 (P),召回(R) 和 F1 分数 (F) 的端到端结果。†和‡表示性能在 DRVPE 和 MIRA[14] 的基线上有显著性提升, 分别为 p <0.05。 粗体结果表示最佳性能。
5 VPE 的数据扩展
最近的动词短语省略恢复模型主要用于基准数据集 [3],其中每个句子都有一个先行短语和一个触发词。然而,考虑到探索更多的 VPE 现象,我们进一步扩展了四种情况下的数据,如表 7 所示。其中 0,1,2,3 分别表示具有触发词和 VPE 现象,没有触发词但具有 VPE 现象,有触发词但没有 VPE 现象,没有触发词和 VPE 现象。
表 7. 扩展数据标注的标签

扩展数据的比例如图 4 所示,其中标记为 0,1,2,3,s。句子数分别为 15,5,8,784,8。扩展数据的总数等于 820。

图 4. 扩展数据的比例
相应的示例在表 8 中示出。
表 8. 扩展数据的示例

除了这四个条件外,我们还观察到一种现象,即先行短语不是一个连续的序列。我们将此视为 VPE 的特例,并使用标签 “s” 对其进行标注。例如,在 “Since the reforms went in place, for example, no state has posted a higher rate of improvement on the Scholastic Aptitude Test than South Carolina, although the state still posts the lowest average score of the about 21 states who use the as the primary college entrance examination.“。先行短语是 ” posted a rate of improvement“ ,这是由于句子的比较形式。我们将在未来的工作中探索扩展数据中的所有 VPE 现象。
6 总结
我们研究了用于动词短语省略恢复的神经网络模型,提出了一个用于 VPE 检测和 VPE 消解的端到端处理的框架。结果表明,神经网络模型在 VPE 检测和 VPE 消解方面均优于基线,端到端过程比基线有着更高的结果。此外,传统的人工特征仍然可用于改善神经网络模型。我们发布了用于 VPE 检测和消解的扩展数据集。
参考文献
[1] Bahdanau, D.; Cho, K.; and Bengio, Y. 2014. Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473.
[2] Bakhshandeh, O.; Wellwood, A. C.; and Allen, J. 2016. Learning to jointly predict ellipsis and comparison structures. In Proceedings of The 20th SIGNLL Conference on Computational Natural Language Learning, 62–74.
[3] Bos, J., and Spenader, J. 2011. An annotated corpus for the analysis of vp ellipsis. Language Resources and Evaluation 45(4):463–494.
[4] Bos, J. 2005. Verb phrase ellipsis and sloppy identity: a corpus-based investigation. Mining for Parsing Failures.
[5] Bos, J. 2012. Robust vp ellipsis resolution in dr theory. From quantification to conversation 19:145–159.
[6] Chung, J.; Gulcehre, C.; Cho, K.; and Bengio, Y. 2014. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv preprint arXiv:1412.3555.
[7] Collobert, R., and Weston, J. 2008. A unified architecture for natural language processing: Deep neural networks with multitask learning. In Proceedings of the 25th international conference on Machine learning, 160–167. ACM.
[8] Hardt, D. 1992. An algorithm for vp ellipsis. In Proceedings of the 30th annual meeting on Association for Computational Linguistics, 9–14. Association for Computational Linguistics.
[9] Hardt, D. 1997. An empirical approach to vp ellipsis. Computational Linguistics 23(4):525–541.
[10] Hardt, D. 1998. Improving ellipsis resolution with transformation-based learning. In Aaai fall symposium, volume 1998.
[11] Hobbs, J. R., and Kehler, A. 1997. A theory of parallelism and the case of vp ellipsis. In Proceedings of the 35th Annual Meeting of the Association for Computational Linguistics and Eighth Conference of the European Chapter of the Association for Computational Linguistics, 394–401. Association for Computational Linguistics.
[12] Kamp, H.; Reyle, U.; et al. 1993. From discourse to logic: Introduction to model-theoretic semantics of natural language, formal logic and discourse representation theory, volume 42 of. Studies in linguistics and philosophy.
[13] Kawai, M. 2013. On vp ellipsis and the identity condition. Proceedings of the 2013 annual conference of the Canadian Linguistic Association.
[14] Kenyon-Dean, K.; Cheung, J. C. K.; and Precup, D. 2016. Verb phrase ellipsis resolution using discriminative and margin-infused algorithms. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, 1734–1743.
[15] Kingma, D. P., and Ba, J. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
[16] Liu, Z.; Pellicer, E. G.; and Gillick, D. 2016. Exploring the steps of verb phrase ellipsis. In Proceedings of the Workshop on Coreference Resolution Beyond OntoNotes (CORBON 2016), 32–40.
[17] McShane, M., and Babkin, P. 2016. Detection and resolution of verb phrase ellipsis. LiLT (Linguistic Issues in Language Technology) 13.
[18] Nielsen, L. A. 2003a. A corpus-based study of verb phrase ellipsis. In Proceedings of the 6th Annual cluk Research Colloquium, 109–115.
[19] Nielsen, L. A. 2003b. Using machine learning techniques for vpe detection. In Proceedings of RANLP, 339–346.
[20] Nielsen, L. A. 2004a. Robust vpe detection using automatically parsed text. In Proceedings of the ACL 2004 workshop on Student research, 25. Association for Computational Linguistics.
[21] Nielsen, L. A. 2004b. Verb phrase ellipsis detection using automatically parsed text. In Proceedings of the 20th international conference on Computational Linguistics, 1093. Association for Computational Linguistics.
[22] Nielsen, L. A. 2005. A corpus-based study of verb phrase ellipsis identification and resolution. Ph.D. Dissertation, King’s College London.
[23] Van Craenenbroeck, J. 2017. Vp-ellipsis. The Wiley Blackwell Companion to Syntax, Second Edition 1–35.
[24] Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A. N.; Kaiser, Ł.; and Polosukhin, I. 2017. Attention is all you need. In Advances in Neural Information Processing Systems, 5998–6008.
[25] Vaswani, A.; Bengio, S.; Brevdo, E.; Chollet, F.; Gomez, A. N.; Gouws, S.; Jones, L.; Kaiser, Ł.; Kalchbrenner, N.; Parmar, N.; et al. 2018. Tensor2tensor for neural machine translation. arXiv preprint arXiv:1803.07416.
本期责任编辑:张伟男
本期编辑:吴 洋
“哈工大SCIR”公众号
主编:车万翔
副主编: 张伟男,丁效
责任编辑: 张伟男,丁效,刘一佳,崔一鸣
编辑: 李家琦,吴洋,刘元兴,蔡碧波,孙卓,赖勇魁
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。





