谷歌足球游戏环境使用介绍
Google Research Football: A Novel Reinforcement Learning Environment

https://github.com/google-research/football
1. Installation (Ubuntu16.04):
$ pip install tensorflow-gpu(==1.12 for cuda 9 )
$ pip install git+https://github.com/openai/baselines.git
issues you may encounter:

$ cd /usr/lib/x86_64-linux-gnu/
$ sudo ln -s libboost_python-py35.so libboost_python-py36.so
Install required apt packages:
$ sudo apt-get install git cmake build-essential libgl1-mesa-dev libsdl2-dev libsdl2-image-dev libsdl2-ttf-dev libsdl2-gfx-dev libboost-all-dev libdirectfb-dev libst-dev mesa-utils xvfb x11vnc libsqlite3-dev glee-dev libsdl-sge-dev python3-pip
$ cd football
$ pip install .
The Football Engine is out of the box compatible with the widely used OpenAI Gym API:

FUNCTIONS
create_environment (env_name='', stacked=False, representation='extracted', with_checkpoints=False, enable_goal_videos=False, enable_full_episode_videos=False, render=False, write_video=False, dump_frequency=1, logdir='', data_dir=None, font_file=None, away_player=None):
Creates a Google Research Football environment.
Args:
env_name: a name of a scenario to run, e.g. "11_vs_11_stochastic". The list of scenarios can be found in directory "scenarios".
stacked: If True, stack 4 observations, otherwise, only the last observation is returned by the environment. Stacking is only possible when representation is one of the following: "pixels", "pixels_gray" or "extracted". In that case, the stacking is done along the last (i.e. channel) dimension.
representation: String to define the representation used to build the observation. It can be one of the following:
'pixels': the observation is the rendered view of the football field downsampled to w=96, h=72. The observation size is: 72x96x3 (or 72x96x12 when "stacked" is True).
'pixels_gray': the observation is the rendered view of the football field in gray scale and downsampled to w=96, h=72. The observation size is 72x96x1 (or 72x96x4 when stacked is True).
'extracted': also referred to as super minimap. The observation is composed of 4 planes of size w=96, h=72. Its size is then 72x96x4 (or 72x96x16 when stacked is True). The first plane P holds the position of the 11 player of the home team, P[y,x] is one if there is a player at position (x,y), otherwise, its value is zero. The second plane holds in the same way the position of the 11 players of the away team. The third plane holds the active player of the home team. The last plane holds the position of the ball.
'simple115': the observation is a vector of size 115. It holds:
- the ball_position and the ball_direction as (x,y,z)
- one hot encoding of who controls the ball. [1, 0, 0]: nobody, [0, 1, 0]: home team, [0, 0, 1]: away team.
- one hot encoding of size 11 to indicate who is the active player in the home team.
- 11 (x,y) positions for each player of the home team.
- 11 (x,y) motion vectors for each player of the home team.
- 11 (x,y) positions for each player of the away team.
- 11 (x,y) motion vectors for each player of the away team.
- one hot encoding of the game mode. Vector of size 7 with the following meaning: {NormalMode, KickOffMode, GoalKickMode, FreeKickMode, CornerMode, ThrowInMode, PenaltyMode}. Can only be used when the scenario is a flavor of normal game (i.e. 11 versus 11 players).
with_checkpoints: True to add intermediate checkpoint rewards to guide the agent to move to the opponent goal. If False, only scoring provides a reward.
enable_goal_videos: whether to dump traces up to 200 frames before goals.
enable_full_episode_videos: whether to dump traces for every episode.
render: whether to render game frames. Must be enable when rendering videos or when using pixels representation.
write_video: whether to dump videos when a trace is dumped.
dump_frequency: how often to write dumps/videos (in terms of # of episodes). Sub-sample the episodes for which we dump videos to save some disk space.
logdir: directory holding the logs.
data_dir: location of the game engine data. Safe to leave as the default value.
font_file: location of the game font file
Safe to leave as the default value.
away_player: Away player (adversary) to use in the environment.
2. Football benchmarks
Average Goal Difference on Football Benchmarks for IMPALA and DQN with SCORING and CHECKPOINT rewards:
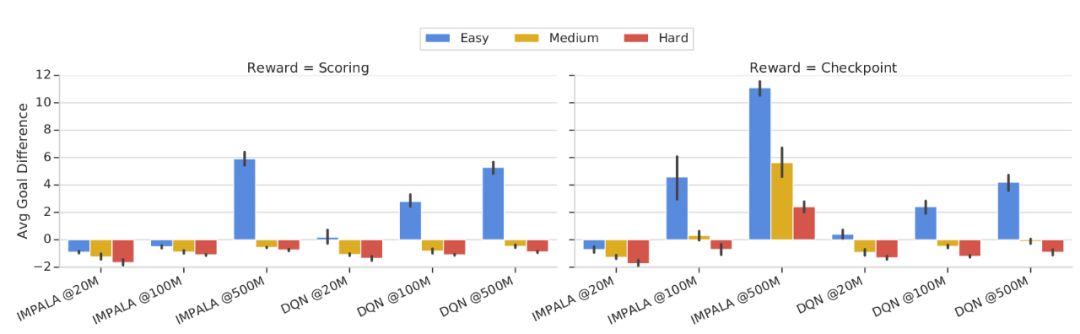
First, the impact of different difficulty levels is clear from the plots. Harder tasks take significantly more steps to make some progress.
Second, with the raw scoring reward, Impala is only able to convincingly solve the easy task. Even in this case, it finds a way to consistently score only after 100M training steps. However, performance slowly improves over training steps in all tasks. On the other hand, the checkpoint rewards speed up training for Impala, especially after 20M steps. In particular, after 500M steps, Impala is able to repeatedly score in games at all levels. Despite the fact that the agent ends up scoring, the amount of required experience is simply enormous, and improved sample efficiency remains a big open question.
Third, Ape-X DQN does not seem to benefit from the checkpoint reward; its performance is very similar with both reward functions. Notably, DQN makes progress in the easy scenario quickly (actually, it wins games on average at all stages shown in the plot). Unfortunately, learning progress on the medium and hard cases seems minimal, and further training is probably required.
3. Football academy
Training agents for the Football Benchmarks can be challenging. Accordingly, we also provide the Football Academy: a diverse set of scenarios of varying difficulty. Its main goal is to allow researchers to get started on new research ideas quickly, and iterate on them.