语义分割 | context relation
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
作者:Xavier CHEN
来源:https://zhuanlan.zhihu.com/p/56156570
问题背景
近年来,语义分割的模型几乎都是基于FCN框架,利用Dilated Conv、Up sample、skip connection等各种组件来变化。 但是这种模型有很大的问题:无法对不同的像素之间的关系进行显式的建模,像素之间的唯一联系就是“感受野”的重叠。所以从本质上来说,这种语义分割框架是一种Dense prediction, 是分立的对每个像素进行预测。
这显然不符合人类对事物的认知方式,人脑中的分割类似于:把一个场景中相似的像素聚成一团,然后宏观的判断这一团像素是什么,在判断类别时,还会利用类别之间的依赖关系联合推理。肯定不会一个点一个点的看这是什么。
由此,对语义分割中的不同像素/上下文之间的关系建模就非常重要,近期的研究中,很多论文着眼于“context”和“relation”,于是结合之前的方法,对于这些建模idea做一个总结。每篇文章只说核心思想,不详细介绍。
1. 近期比较火的利用self-attention建立spatial-wise关系
2. 利用self-attention或者context encoding建立channel之间的关系
3. 利用图卷积建模不同区域/类别之间的依赖关系
4. 利用Metric learning, 建立像素之间的关系
5. 基于CRF思想的各种变种
1.利用self-attention建立spatial-wise关系
《OCNet: Object Context Network for Scene Parsing》
《CCNet: Criss-Cross Attention for Semantic Segmentation》
《Dual Attention Network for Scene Segmentation》
《Non-local Neural Networks》
这几篇的本质思想是一样的,前三篇很像是对最后一篇的发展和应用。以第一篇为例。
之前对神经网络的研究表明,大的感受野对于各种视觉问题都是很重要的,但是后来研究发现,由于感受野会有退化的问题,即使使用Global pooling也不能带来全图的感受野。于是建立长距离的context关系成为了一个要点。
1.1 《OCNet: Object Context Network for Scene Parsing》
OCNet依据像素间的特征相似性,为每一个像素建立了一个Object context map,即把 “ 对一个像素点决策” 变成 “所有相似的像素点放在一起决策”,利用像素之间依赖关系不仅仅是像ensemble一样使得结果更加鲁棒, 并且可以再训练中利用各个像素的特征相互提升。

如图第一行第一列,判断十字位置的像素时,不仅仅看单个位置的特征,而是把所有车子的特征放在一起来判断。
实现上采用non-local方法,记输入OC模块之前的特征为 H*W*C,为例避免计算量过大,可以先对C进行降维。
1)把H*W*C展平为 N*C
2)计算像素之间的Affinity: ( N*C) x (N*C)T = (N,N)代表像素间的吸引力
3)用softmax或者其他方式归一化,使得像素间的依赖成为概率分布
4)(N*N)x (N*C) = (N*C)之后再展为H*W*C。
由此每一个position都是一个C维的向量,该向量融合了图中相似的所有像素的特征。细节看代码:https://github.com/PkuRainBow/OCNet.pytorch 利用该模块得到一个新特征可以直接和原特征concat,也可以用来改进Pyramid Pooling和ASPP模块。
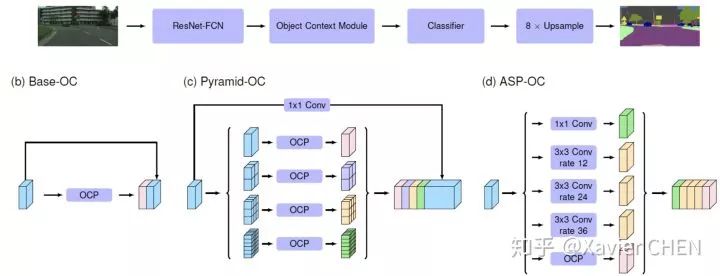
作者在很多数据集包括LIP上都做了实验,都达到SOTA效果。和下面几篇文章相比,这篇不一样的地方就是利用OC机制改进了Pyramid Pooling和ASPP模块了。
1.2《CCNet: Criss-Cross Attention for Semantic Segmentation》
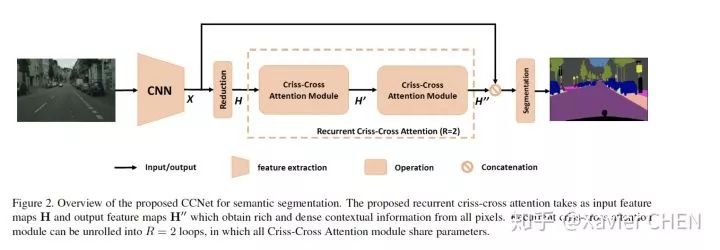
这些论文都是同期出来的,这篇的思想可以说本质上和OCNet是一样的,OCNet的亮点是把non-local融入了SPP, ASPP module, CCNet是利用一个Criss-Cross机制,大大化简了Non-local中求解Affinity的计算量,速度和计算量小了很多,但是release的结果比OCNet差不了多少。
Non-local在做Affinity Matrix的时候,是在整张图所有的Pixel之间求similarity, 这样就要求W*H*W*H个pairwise similarity,这是很大的计算量。CCNet提出只需要在十字路径上做no-local操作,通过循环两次,就基本可以把信息传播到全图,如下图( 具体推导看原文)
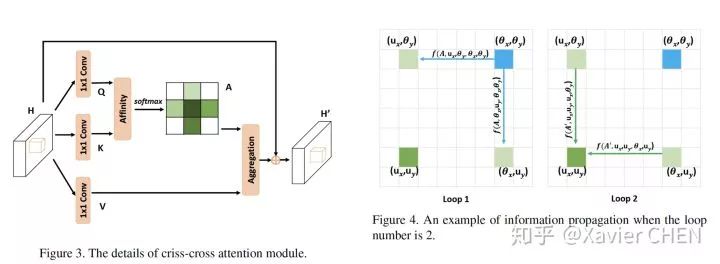
从Pipeline上看,CCNet和OCNet的本质是一样的
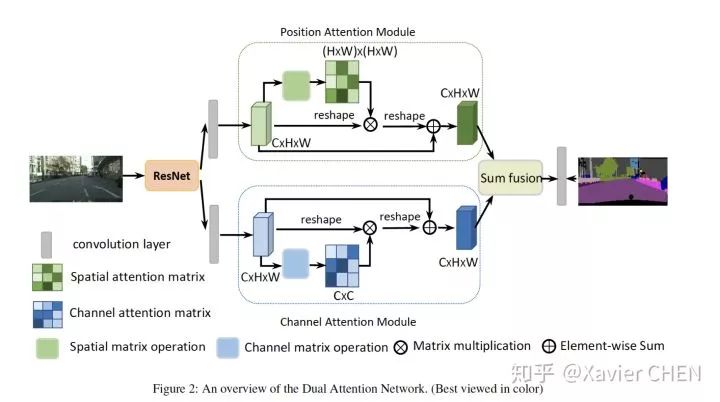
1.3《Dual Attention Network for Scene Segmentation》
在spatial维度是完全一样的思路,利用Non-local结构建立long range relation。不仅如此,这篇文章还把self-attention的思想拓展到了channel维度,由于不同的channel代表不同的滤波器响应,在高层特征中可以代表不同的语义概念,作者希望利用channel-wise attention建立不同语义类别之间的依赖关系。
2.利用self-attention或者context encoding建立channel之间的关系
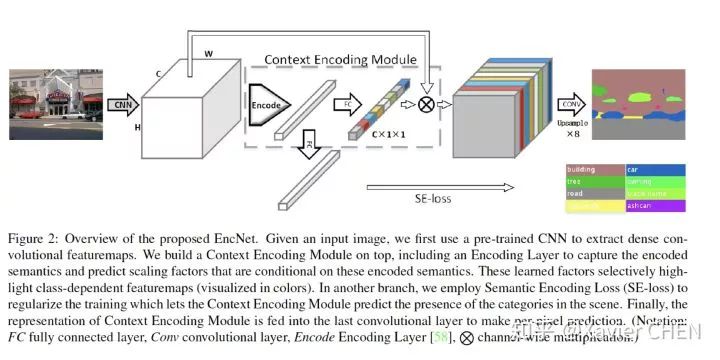
Attention机制就如同刚刚介绍的DANet, 和spatial wise attention都是一样的。另外还有一篇早一点的《Context Encoding for Semantic Segmentation》
这篇算很有代表性的文章,文章的主旨是建立一个Context Encoding Module用于对场景进行编码,由于不同的场景中不同的物件出现的可能性不一样。比如在天空的场景中,就要强化飞机的概率,不能强化船的概率。本文用Global Pooling得到场景特征,利用类似于senet的思想建立channel之间的关系。
3.利用图卷积建模不同区域/类别之间的依赖关系
3.1《Graph-Based Global Reasoning Networks》
我觉得这是最好的一篇文章,利用GCN建立不同region之间的relation。本文的核心思想如下图,在图像几何空间(coordinate space),由于每一个像素都有特征表示,所以特征维度非常高,这么多的特征之间,不容易进行信息流动。如下图:最好的情况就是把a图投影到一个Interaction space, 把每个像素投影到不同的节点,比如:人,墙壁,电视机。。。然后再利用这些节点之间的依赖关系进行信息流动,之后再把这些信息交互过的节点,投影回到之前的坐标空间。
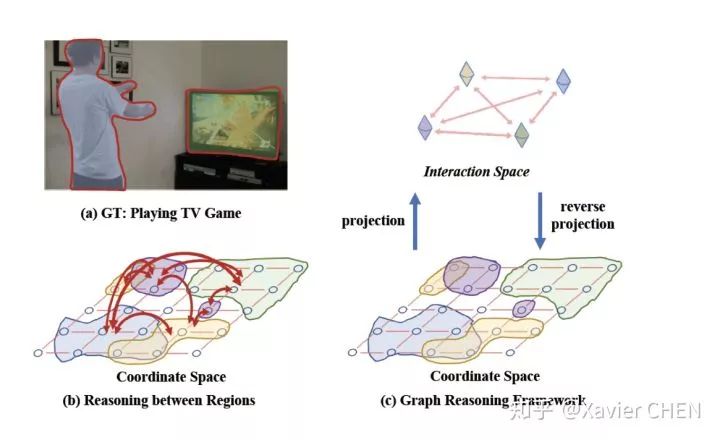
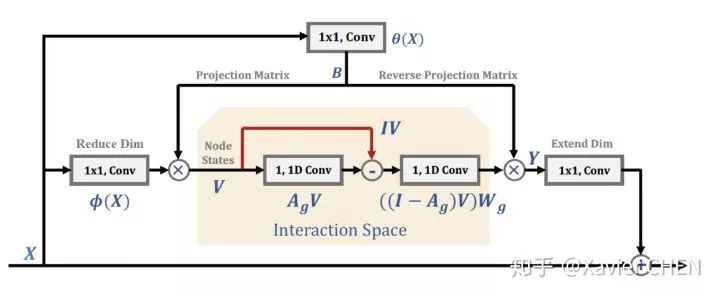
作者找到了一种简介的表示方法来实现上述目的,使用简单的1x1卷积做空间投影,使用图卷积做information diffusion。图卷积中不同节点的依赖关系也是依靠1x1的卷积学习得到。
其实这篇文章的出发点和上述的文章有相似之处: 在宏观上把每个像素的决策问题转变成一团像素的决策问题,spatial-wise self-attention的方法只能让信息在同一个类别的像素之间流动,这里作者利用图卷积使得信息在不同的类别之间流动,建立了不同类别/区域间的依赖关系。
感觉这篇文章,作者的设计只是在空间“维度”上满足了自己的设想,在具体如何对不同的region或者semantic class建模上其实还有很多内容可以继续探究。
4.利用Metric learning, 建立像素之间的关系
《Adaptive Affinity Fields for Semantic Segmentation》
上述的文章都是全图之间,比较宏观的语义依赖于关连,这篇文章讲的是利用局部像素之间的关系使得网络学习到更好的表征能力。
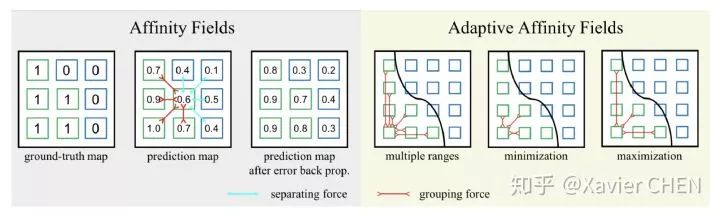
这篇文章的思路很简洁:属于同一个类别的两个像素之间的语义表示要尽可能相似,属于不同类别的语义表示需要距离更远,于是作者引入度量学习的思想,在一定的区域内利用Affinity Fields, 使得每个小区域内属于同一个类别的像素特征尽可能相似,不同类别像素尽可能有区别。这个思想其实也是“把逐像素预测问题变成一个更加宏观的预测”
5.CRF的变种
CRF在语义分割中早已经得到了广泛的应用,CRF能work那就说明了基于底层特征和位置特征简历像素之间的依赖关系是可行的,这样其实也可以为no-local类似的方法提供思路。
其余变种的还有把CRF套到卷积中以提高计算效率,把类似CRF的东西写到Loss中
《 Convolutional CRFs for Semantic Segmentation 》
:https://arxiv.org/abs/1805.04777
《On Regularized Losses for Weakly-supervised CNN Segmentation》
*延伸阅读
TorchSeg:基于pytorch的语义分割算法开源了
有关语义分割的奇技淫巧有哪些?
每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击左下角“阅读原文”立刻申请入群~

觉得有用麻烦给个好看啦~





