ICML 2019 | 神经网络的可解释性,从经验主义到数学建模

针对不同自然语言应用的神经网络,寻找恰当的数学工具去建模其中层特征所建模的信息量,并可视化其中层特征的信息分布,进而解释不同模型的性能差异。
AI 科技评论按,本文作者张拳石,上海交通大学副教授,研究方向为机器学习、计算机视觉,本文首发于知乎(https://zhuanlan.zhihu.com/p/67831834),AI 科技评论获其授权转载。以下为正文内容。
本来想把题目取为「从炼丹到化学」,但是这样的题目太言过其实,远不是近期可以做到的,学术研究需要严谨。但是,寻找适当的数学工具去建模深度神经网络表达能力和训练能力,将基于经验主义的调参式深度学习,逐渐过渡为基于一些评测指标定量指导的深度学习,是新一代人工智能需要面对的课题,也是在当前深度学习浑浑噩噩的大背景中的一些新的希望。
这篇短文旨在介绍团队近期的 ICML 工作——「Towards a Deep and Unified Understanding of Deep Neural Models in NLP」(这篇先介绍 NLP 领域,以后有时间再介绍类似思想解释 CV 网络的论文)。这是我与微软亚洲研究院合作的一篇论文。其中,微软研究院的王希廷研究员在 NLP 方向有丰富经验,王老师和关超宇同学在这个课题上做出了非常巨大的贡献,这里再三感谢。
大家说神经网络是「黑箱」,其含义至少有以下两个方面:一、神经网络特征或决策逻辑在语义层面难以理解;二、缺少数学工具去诊断与评测网络的特征表达能力(比如,去解释深度模型所建模的知识量、其泛化能力和收敛速度),进而解释目前不同神经网络模型的信息处理特点。
过去我的研究一直关注第一个方面,而这篇 ICML 论文同时关注以上两个方面——针对不同自然语言应用的神经网络,寻找恰当的数学工具去建模其中层特征所建模的信息量,并可视化其中层特征的信息分布,进而解释不同模型的性能差异。
其实,我一直希望去建模神经网络的特征表达能力,但是又一直迟迟不愿意下手去做。究其原因,无非是找不到一套优美的数学建模方法。深度学习研究及其应用很多已经被人诟病为「经验主义」与「拍脑袋」,我不能让其解释性算法也沦为经验主义式的拍脑袋——不然解释性工作还有什么意义。
研究的难点在于对神经网络表达能力的评测指标需要具备「普适性」和「一贯性」。首先,这里「普适性」是指解释性指标需要定义在某种通用的数学概念之上,保证与既有数学体系有尽可能多的连接,而与此同时,解释性指标需要建立在尽可能少的条件假设之上,指标的计算算法尽可能独立于神经网络结构和目标任务的选择。
其次,这里的「一贯性」指评测指标需要客观的反应特征表达能力,并实现广泛的比较,比如
1. 诊断与比较同一神经网络中不同层之间语义信息的继承与遗忘;
2. 诊断与比较针对同一任务的不同神经网络的任意层之间的语义信息分布;
3. 比较针对不同任务的不同神经网络的信息处理特点。
具体来说,在某个 NLP 应用中,当输入某句话 x=[x1,x2,…,xn] 到目标神经网络时,我们可以把神经网络的信息处理过程,看成对输入单词信息的逐层遗忘的过程。即,网络特征每经过一层传递,就会损失一些信息,而神经网络的作用就是尽可能多的遗忘与目标任务无关的信息,而保留与目标任务相关的信息。于是,相对于目标任务的信噪比会逐层上升,保证了目标任务的分类性能。
我们提出一套算法,测量每一中层特征 f 中所包含的输入句子的信息量,即 H(X|F=f)。当假设各单词信息相互独立时,我们可以把句子层面的信息量分解为各个单词的信息量 H(X|F=f) = H(X1=x1|F=f) + H(X2=x2|F=f) + … + H(Xn=xn|F=f). 这评测指标在形式上是不是与信息瓶颈理论相关?但其实两者还是有明显的区别的。信息瓶颈理论关注全部样本上的输入特征与中层特征的互信息,而我们仅针对某一特定输入,细粒度地研究每个单词的信息遗忘程度。
其实,我们可以从两个不同的角度,计算出两组不同的熵 H(X|F=f)。
(1)如果我们只关注真实自然语言的低维流形,那么 p(X=x|F=f) 的计算比较容易,可以将 p 建模为一个 decoder,即用中层特征 f 去重建输入句子 x。(2)在这篇文章中,我们其实选取了第二个角度:我们不关注真实语言的分布,而考虑整个特征空间的分布,即 x 可以取值为噪声。在计算 p(X=x,F=f) = p(X=x) p(F=f|X=x) 时,我们需要考虑「哪些噪声输入也可以生成同样的特征 f」。举个 toy example,当输入句子是「How are you?」时,明显「are」是废话,可以从「How XXX you?」中猜得。这时,如果仅从真实句子分布出发,考虑句子重建,那些话佐料(「are」「is」「an」)将被很好的重建。而真实研究选取了第二个角度,即我们关注的是哪些单词被神经网络遗忘了,发现原来「How XYZ you?」也可以生成与「How are you?」一样的特征。
这时,H(X|F=f) 所体现的是,在中层特征 f 的计算过程中,哪些单词的信息在层间传递的过程中逐渐被神经网络所忽略——将这些单词的信息替换为噪声,也不会影响其中层特征。这种情况下,信息量 H(X|F=f) 不是直接就可以求出来的,如何计算信息量也是这个课题的难点。具体求解的公式推导可以看论文,知乎上只放文字,不谈公式。
首先,从「普适性」的角度来看,中层特征中输入句子的信息量(输入句子的信息的遗忘程度)是信息论中基本定义,它只关注中层特征背后的「知识量」,而不受网络模型参数大小、中层特征值的大小、中层卷积核顺序影响。其次,从「一贯性」的角度来看,「信息量」可以客观反映层间信息快递能力,实现稳定的跨层比较。如下图所示,基于梯度的评测标准,无法为不同中间层给出一贯的稳定的评测。
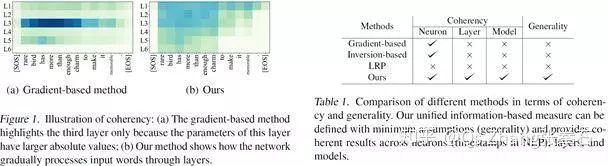
下图比较了不同可视化方法在分析「reverse sequence」神经网络中层特征关注点的区别。我们基于输入单词信息量的方法,可以更加平滑自然的显示神经网络内部信息处理逻辑。

下图分析比较了不同可视化方法在诊断「情感语义分类」应用的神经网络中层特征关注点的区别。我们基于输入单词信息量的方法,可以更加平滑自然的显示神经网络内部信息处理逻辑。

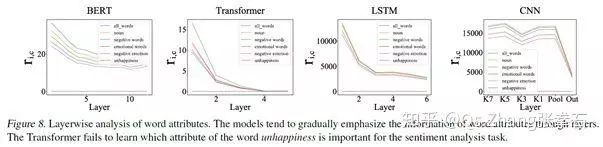
基于神经网络中层信息量指标,分析不同神经网络模型的处理能力。我们分析比较了四种在 NLP 中常用的深度学习模型,即 BERT, Transformer, LSTM, 和 CNN。在各 NLP 任务中,BERT 模型往往表现最好,Transformer 模型次之。
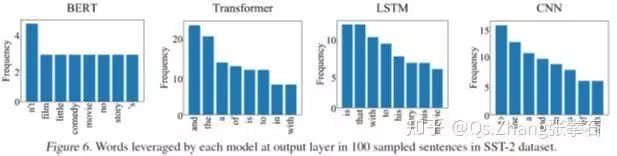
如下图所示,我们发现相比于 LSTM 和 CNN,基于预训练参数的 BERT 模型和 Transformer 模型往往可以更加精确地找到与任务相关的目标单词,而 CNN 和 LSTM 往往使用大范围的邻接单词去做预测。

进一步,如下图所示,BERT 模型在预测过程中往往使用具有实际意义的单词作为分类依据,而其他模型把更多的注意力放在了 and the is 等缺少实际意义的单词上。
如下图所示,BERT 模型在 L3-L4 层就已经遗忘了 EOS 单词,往往在第 5 到 12 层逐渐遗忘其他与情感语义分析无关的单词。相比于其他模型,BERT 模型在单词选择上更有针对性。
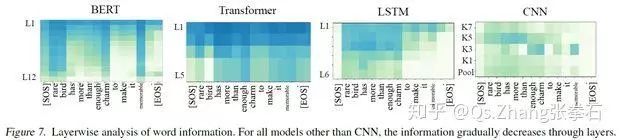
我们的方法可以进一步细粒度地分析,各个单词的信息遗忘。BERT 模型对各种细粒度信息保留的效果最好。
十多年前刚刚接触 AI 时总感觉最难的是独立找课题,后来发现追着热点还是很容易拍脑袋想出一堆新题目,再后来发现真正想做的课题越来越少,虽然 AI 领域中学者们的投稿量一直指数增长。
回国以后,身份从博后变成了老师,带的学生增加了不少,工作量也翻倍了,所以一直没有时间写文章与大家分享一些新的工作,如果有时间还会与大家分享更多的研究,包括这篇文章后续的众多算法。信息量在 CV 方向应用的论文,以及基于这些技术衍生出的课题,我稍后有空再写。
顺便做个广告,欢迎有能力的学生来实验室实习,同时也招博后。目前我的团队有 30 余人,其中不少同学是外校全职访问实习生。我一般会安排每三四人为一个团队做一个课题,由于访问实习生往往不用为上课而分心,可以全天候做实验室工作,在经过一定训练之后往往会担任团队领导。
2019 年 7 月 12 日至 14 日,由中国计算机学会(CCF)主办、雷锋网和香港中文大学(深圳)联合承办,深圳市人工智能与机器人研究院协办的 2019 全球人工智能与机器人峰会(简称 CCF-GAIR 2019)将于深圳正式启幕。
届时,诺贝尔奖得主JamesJ. Heckman、中外院士、世界顶会主席、知名Fellow,多位重磅嘉宾将亲自坐阵,一起探讨人工智能和机器人领域学、产、投等复杂的生存态势。

今日限量赠送3张1000元门票优惠码,门票原价1999元,打开以下任一链接即可使用,券后仅999元,限量3张,先到先得,送完即止。
https://gair.leiphone.com/gair/coupon/s/5d0763011b2e8
https://gair.leiphone.com/gair/coupon/s/5d0763011b077
https://gair.leiphone.com/gair/coupon/s/5d0763011ae43