Hadoop的数据仓库框架-Hive 基础知识及快速入门



来源: 软件架构
数据猿官网 | www.datayuan.cn

今日头条丨一点资讯丨腾讯丨搜狐丨网易丨凤凰丨阿里UC大鱼丨新浪微博丨新浪看点丨百度百家丨博客中国丨趣头条丨腾讯云·云+社区

Hive是一个构建在Hadoop上的数据仓库框架。最初,Hive是由Facebook开发,后来移交由Apache软件基金会开发,并作为一个Apache开源项目。
Hive和传统数据仓库一样,主要用来协助分析报表,支持决策。与传统数据仓库较大的区别是:Hive 可以处理超大规模的数据,可扩展性和容错性非常强。
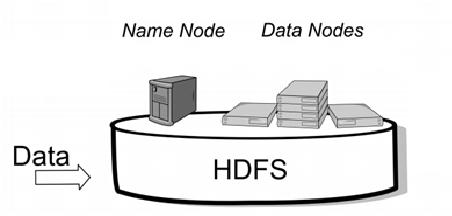
Hive 将所有数据存储在HDFS中,并建立在Hadoop 之上,大部分的查询、计算由MapReduce完成。

Hadoop 生态系统
Hadoop是一个开源框架来存储和处理大型数据在分布式环境中。它包含两个模块,一个是MapReduce,另外一个是Hadoop分布式文件系统(HDFS)。
Hadoop生态系统包含了用于协助Hadoop的不同的子项目(工具)模块,如Sqoop, Pig 和 Hive。
·Sqoop: 它是用来在HDFS和RDBMS之间来回导入和导出数据。
·Pig: 主要用于数据仓库的ETL(Extract-Transformation-Loading)环节。
·Hive: 主要用于数据仓库海量数据的批处理分析。

Hive 和传统数据库的异同
Hive采用了类SQL的查询语言HQL(Hive Query Language),底层还是MapReduce。Hive本身是数据仓库,并不是数据库系统。
Hive数据访问执行延迟高,不适合在线查询数据。

Hive在企业大数据分析平台中的应用
当前企业中部署的大数据分析平台,除Hadoop的基本组件HDFS和MapReduce外,还结合使用Hive、Pig、Hbase、Mahout,从而满足不同业务场景需求。

上图是企业中一种常见的大数据分析平台部署框架 ,在这种部署架构中:
·Hive和Pig用于报表中心,Hive用于分析报表,Pig用于报表中数据的ETL工作。
·HBase用于在线业务,HDFS不支持随机读写操作,而HBase正是为此开发,可较好地支持实时访问数据。
·Mahout 提供一些可扩展的机器学习领域的经典算法实现,用于创建商务智能(BI)应用程序。
Hive 系统架构
下图显示Hive的主要组成模块、Hive如何与Hadoop交互工作、以及从外部访问Hive的几种典型方式。

Hive主要由以下三个模块组成:
·用户接口模块,含CLI、HWI、JDBC、Thrift Server等,用来实现对Hive的访问。CLI是Hive自带的命令行界面;HWI是Hive的一个简单网页界面;JDBC、ODBC以及Thrift Server可向用户提供进行编程的接口,其中Thrift Server是基于Thrift软件框架开发的,提供Hive的RPC通信接口。
·驱动模块(Driver),含编译器、优化器、执行器等,负责把HiveQL语句转换成一系列MR作业,所有命令和查询都会进入驱动模块,通过该模块的解析变异,对计算过程进行优化,然后按照指定的步骤执行。
·元数据存储模块(Metastore),是一个独立的关系型数据库,通常与MySQL数据库连接后创建的一个MySQL实例,也可以是Hive自带的Derby数据库实例。此模块主要保存表模式和其他系统元数据,如表的名称、表的列及其属性、表的分区及其属性、表的属性、表中数据所在位置信息等。
把SQL 转化为MapReduce 任务的步骤
当Hive接收到一条HQL语句后,需要与Hadoop交互工作来完成该操作。HQL首先进入驱动模块,由驱动模块中的编译器解析编译,并由优化器对该操作进行优化计算,然后交给执行器去执行。执行器通常启动一个或多个MR任务,有时也不启动(如SELECT * FROM tb1,全表扫描,不存在投影和选择操作)。

END
找大数据,搜数据猿