iOS启动时间优化
本公众号内容均为本号转发,已尽可能注明出处。因未能核实来源或转发内容图片有权利瑕疵的,请及时联系本号,本号会第一时间进行修改或删除。 QQ : 3442093904
原文链接:http://www.zoomfeng.com/blog/launch-time.html
背景
一个项目做的时间长了,启动流程往往容易杂乱,库也用的越来越多,APP的启动时间也会慢慢变长。本次将针对iOS APP的启动时间优化一波。
通常针对一个技术点做优化的时候,都要先了解清楚这个技术点有哪些流程,优化的方向往往是减少流程的数量,以及减少每个流程的消耗。
本次优化从结果上来看,main阶段的优化效果最显著,尤其是启动时的一些IO操作处理,对启动时间的减少有很大作用。多线程启动的设计和验证最有意思,但是在实践上由于我们业务本身的原因,只开了额外一个子线程来并行启动,且仅在子线程做了少量的独立操作,主要还是我们的业务之间耦合性太强了,不太适合拆分到子线程。
一般说来,pre-main阶段的定义为APP开始启动到系统调用main函数这一段时间;main阶段则代表从main函数入口到主UI框架的viewDidAppear函数调用的这一段时间。(本文后续main阶段的时间统计都用viewDidAppear作为基准而非的applicationWillFinishLaunching)
本文前半部分讲原理(内容基本是从网上借鉴/摘录),后半部分讲实践,pre-main阶段的原理比较难理解,不过实践倒是根据结论直接做就好了。
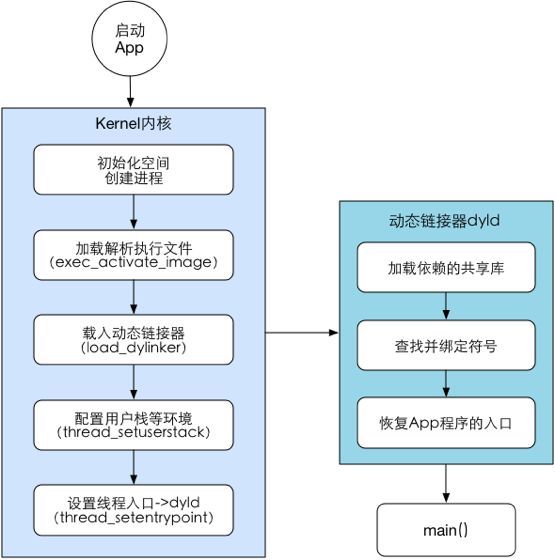
App启动过程
①解析Info.plist
加载相关信息,例如闪屏
沙箱建立、权限检查
②Mach-O加载
如果是胖二进制文件,寻找合适当前CPU架构的部分
加载所有依赖的Mach-O文件(递归调用Mach-O加载的方法)
定位内部、外部指针引用,例如字符串、函数等
执行声明为__attribute__((constructor))的C函数
加载类扩展(Category)中的方法
C++静态对象加载、调用ObjC的 +load 函数
③程序执行
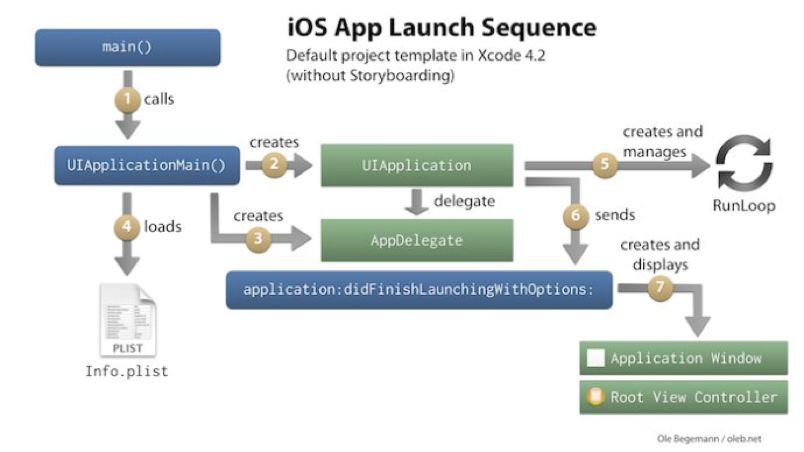
调用main()
调用UIApplicationMain()
调用applicationWillFinishLaunching
换成另一个说法就是:
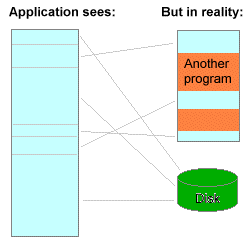
App开始启动后,系统首先加载可执行文件(自身App的所有.o文件的集合),然后加载动态链接器dyld,dyld是一个专门用来加载动态链接库的库。 执行从dyld开始,dyld从可执行文件的依赖开始, 递归加载所有的依赖动态链接库。
动态链接库包括:iOS 中用到的所有系统 framework,加载OC runtime方法的libobjc,系统级别的libSystem,例如libdispatch(GCD)和libsystem_blocks (Block)。
可执行文件的内核流程
如图,当启动一个应用程序时,系统最后会根据你的行为调用两个函数,fork和execve。fork功能创建一个进程;execve功能加载和运行程序。这里有多个不同的功能,比如execl,execv和exect,每个功能提供了不同传参和环境变量的方法到程序中。在OSX中,每个这些其他的exec路径最终调用了内核路径execve。
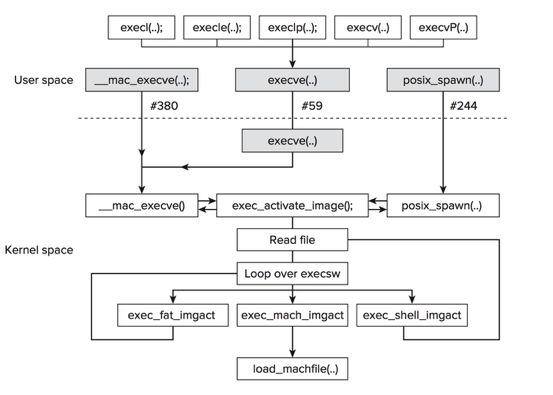
1、执行exec系统调用,一般都是这样,用fork()函数新建立一个进程,然后让进程去执行exec调用。我们知道,在fork()建立新进程之后,父进程与子进程共享代码段(TEXT),但数据空间(DATA)是分开的,但父进程会把自己数据空间的内容copy到子进程中去,还有上下文也会copy到子进程中去。
2、为了提高效率,采用一种写时copy的策略,即创建子进程的时候,并不copy父进程的地址空间,父子进程拥有共同的地址空间,只有当子进程需要写入数据时(如向缓冲区写入数据),这时候会复制地址空间,复制缓冲区到子进程中去。从而父子进程拥有独立的地址空间。而对于fork()之后执行exec后,这种策略能够很好的提高效率,如果一开始就copy,那么exec之后,子进程(确定不是父进程?)的数据会被放弃,被新的进程所代替。
启动时间的分布,pre-main和main阶段原理浅析

rebase修复的是指向当前镜像内部的资源指针; 而bind指向的是镜像外部的资源指针。
rebase步骤先进行,需要把镜像读入内存,并以page为单位进行加密验证,保证不会被篡改,所以这一步的瓶颈在IO。bind在其后进行,由于要查询符号表,来指向跨镜像的资源,加上在rebase阶段,镜像已被读入和加密验证,所以这一步的瓶颈在于CPU计算。这两个步骤在下面会详细阐述。
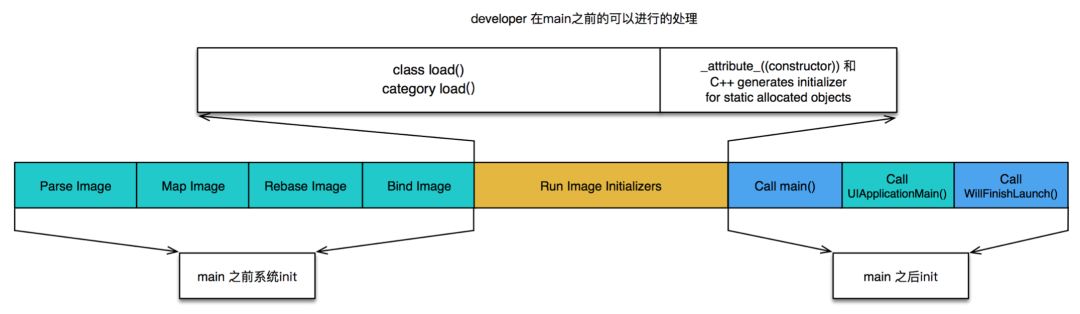
pre-main过程
main过程
一些概念
什么是dyld?
动态链接库的加载过程主要由dyld来完成,dyld是苹果的动态链接器。
系统先读取App的可执行文件(Mach-O文件),从里面获得dyld的路径,然后加载dyld,dyld去初始化运行环境,开启缓存策略,加载程序相关依赖库(其中也包含我们的可执行文件),并对这些库进行链接,最后调用每个依赖库的初始化方法,在这一步,runtime被初始化。
当所有依赖库的初始化后,轮到最后一位(程序可执行文件)进行初始化,在这时runtime会对项目中所有类进行类结构初始化,然后调用所有的load方法。最后dyld返回main函数地址,main函数被调用,我们便来到了熟悉的程序入口。
当加载一个 Mach-O 文件 (一个可执行文件或者一个库) 时,动态链接器首先会检查共享缓存看看是否存在其中,如果存在,那么就直接从共享缓存中拿出来使用。每一个进程都把这个共享缓存映射到了自己的地址空间中。这个方法大大优化了 OS X 和 iOS 上程序的启动时间。

问题:测试发现,由于手机从开机后,连续两次启动同一个APP的pre-main实际时间的差值比较大,这一步可以在真机上复现,那么这两次启动pre-main的时间差值,是跟系统的framework关系比较大,还是跟APP自身依赖的第三方framework关系比较大呢?
Mach-O 镜像文件
Mach-O 被划分成一些 segement,每个 segement 又被划分成一些 section。segment 的名字都是大写的,且空间大小为页的整数。页的大小跟硬件有关,在 arm64 架构一页是 16KB,其余为 4KB。
section 虽然没有整数倍页大小的限制,但是 section 之间不会有重叠。几乎所有 Mach-O 都包含这三个段(segment): __TEXT,__DATA和__LINKEDIT。
__TEXT 包含 Mach header,被执行的代码和只读常量(如C 字符串)。只读可执行(r-x)。
__DATA 包含全局变量,静态变量等。可读写(rw-)。
__LINKEDIT 包含了加载程序的『元数据』,比如函数的名称和地址。只读(r–)。
ASLR(Address Space Layout Randomization):地址空间布局随机化,镜像会在随机的地址上加载。
传统方式下,进程每次启动采用的都是固定可预见的方式,这意味着一个给定的程序在给定的架构上的进程初始虚拟内存都是基本一致的,而且在进程正常运行的生命周期中,内存中的地址分布具有非常强的可预测性,这给了黑客很大的施展空间(代码注入,重写内存);
如果采用ASLR,进程每次启动,地址空间都会被简单地随机化,但是只是偏移,不是搅乱。大体布局——程序文本、数据和库是一样的,但是具体的地址都不同了,可以阻挡黑客对地址的猜测 。
代码签名:可能我们认为 Xcode 会把整个文件都做加密 hash 并用做数字签名。其实为了在运行时验证 Mach-O 文件的签名,并不是每次重复读入整个文件,而是把每页内容都生成一个单独的加密散列值,并存储在 __LINKEDIT 中。这使得文件每页的内容都能及时被校验确并保不被篡改。
关于虚拟内存
我们开发者开发过程中所接触到的内存均为虚拟内存,虚拟内存使App认为它拥有连续的可用的内存(一个连续完整的地址空间),这是系统给我们的馈赠,而实际上,它通常是分布在多个物理内存碎片,系统的虚拟内存空间映射vm_map负责虚拟内存和物理内存的映射关系。
ARM处理器64bit的架构情况下,也就是0x000000000 - 0xFFFFFFFFF,每个16进制数是4位,即2的36次幂,就是64GB,即App最大的虚拟内存空间为64GB。
共享动态库其实就是共享的物理内存中的那份动态库,App虚拟内存中的共享动态库并未真实分配物理内存,使用时虚拟内存会访问同一份物理内存达到共享动态库的目的。
iPhone7 PLUS(之前的产品最大为2GB)的物理内存RAM也只有3GB,那么超过3GB的物理内存如何处理呢,系统会使用一部分硬盘空间ROM来充当内存使用,在需要时进行数据交换,当然磁盘的数据交换是远远慢于物理内存的,这也是我们内存过载时,App卡顿的原因之一。
系统使用动态链接有几点好处:
代码共用:很多程序都动态链接了这些 lib,但它们在内存和磁盘中中只有一份。
易于维护:由于被依赖的 lib 是程序执行时才链接的,所以这些 lib 很容易做更新,比如libSystem.dylib 是 libSystem.B.dylib 的替身,哪天想升级直接换成libSystem.C.dylib 然后再替换替身就行了。
减少可执行文件体积:相比静态链接,动态链接在编译时不需要打进去,所以可执行文件的体积要小很多。
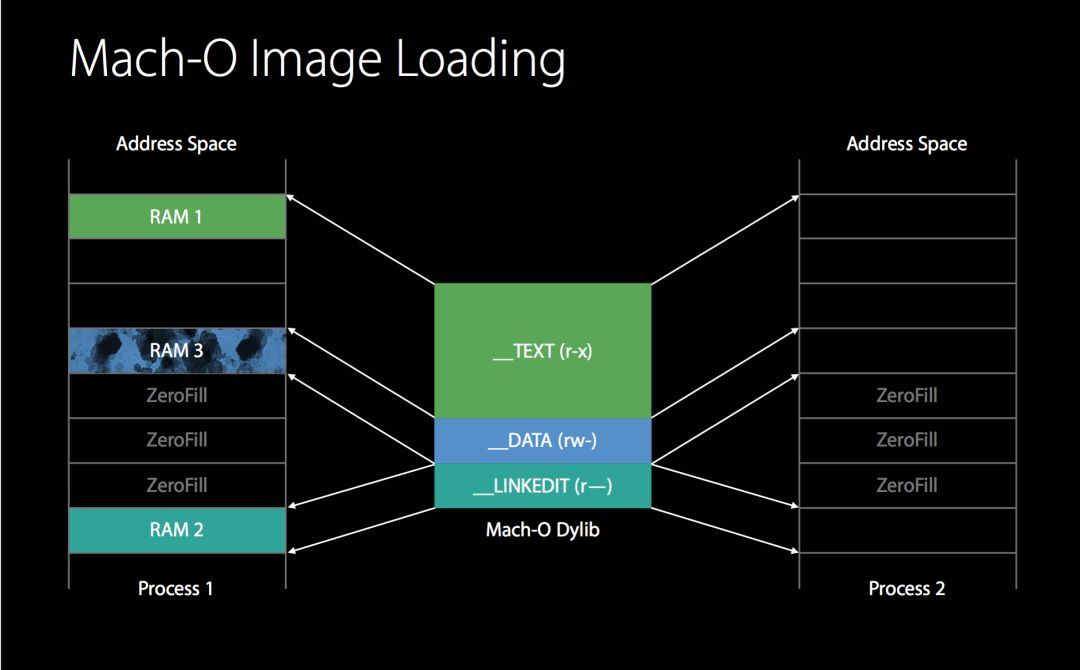
上图中,TEXT段两个进程共用,DATA段每个进程各一份。
下面开始详细分析pre-main的各个阶段
加载 Dylib
从主执行文件的 header 获取到需要加载的所依赖动态库列表,而 header 早就被内核映射过。然后它需要找到每个 dylib,然后打开文件读取文件起始位置,确保它是 Mach-O 文件。接着会找到代码签名并将其注册到内核。然后在 dylib 文件的每个 segment 上调用 mmap()。
应用所依赖的 dylib 文件可能会再依赖其他 dylib,所以 dyld 所需要加载的是动态库列表一个递归依赖的集合。一般应用会加载 100 到 400 个 dylib 文件,但大部分都是系统 dylib,它们会被预先计算和缓存起来,加载速度很快。
加载系统的 dylib 很快,因为有优化(因为操作系统自己要用部分framework所以在操作系统开机后就已经缓存了?)。但加载内嵌(embedded)的 dylib 文件很占时间,所以尽可能把多个内嵌 dylib 合并成一个来加载,或者使用 static archive。使用 dlopen() 来在运行时懒加载是不建议的,这么做可能会带来一些问题,并且总的开销更大。
在每个动态库的加载过程中, dyld需要:
分析所依赖的动态库
找到动态库的mach-o文件
打开文件
验证文件
在系统核心注册文件签名
对动态库的每一个segment调用mmap()
针对这一步骤的优化有:
减少非系统库的依赖;
使用静态库而不是动态库;
合并非系统动态库为一个动态库;
Rebase && Binding
Fix-ups
在加载所有的动态链接库之后,它们只是处在相互独立的状态,需要将它们绑定起来,这就是 Fix-ups。代码签名使得我们不能修改指令,那样就不能让一个 dylib 的调用另一个 dylib。这时需要加很多间接层。
现代 code-gen 被叫做动态 PIC(Position Independent Code),意味着代码可以被加载到间接的地址上。当调用发生时,code-gen 实际上会在 __DATA 段中创建一个指向被调用者的指针,然后加载指针并跳转过去。
所以 dyld 做的事情就是修正(fix-up)指针和数据。Fix-up 有两种类型,rebasing 和 binding。
Rebase
Rebasing:在镜像内部调整指针的指向,针对mach-o在加载到内存中不是固定的首地址(ASLR)这一现象做数据修正的过程;
由于ASLR(address space layout randomization)的存在,可执行文件和动态链接库在虚拟内存中的加载地址每次启动都不固定,所以需要这2步来修复镜像中的资源指针,来指向正确的地址。 rebase修复的是指向当前镜像内部的资源指针; 而bind指向的是镜像外部的资源指针。
在iOS4.3前会把dylib加载到指定地址,所有指针和数据对于代码来说都是固定的,dyld 就无需做rebase/binding了。
iOS4.3后引入了 ASLR ,dylib会被加载到随机地址,这个随机的地址跟代码和数据指向的旧地址会有偏差,dyld 需要修正这个偏差,做法就是将 dylib 内部的指针地址都加上这个偏移量,偏移量的计算方法如下:
Slide = actual_address - preferred_address
然后就是重复不断地对 __DATA 段中需要 rebase 的指针加上这个偏移量。这就又涉及到 page fault 和 COW。这可能会产生 I/O 瓶颈,但因为 rebase 的顺序是按地址排列的,所以从内核的角度来看这是个有次序的任务,它会预先读入数据,减少 I/O 消耗。
在 Rebasing 和 Binding 前会判断是否已经 Prebinding。如果已经进行过预绑定(Prebinding),那就不需要 Rebasing 和 Binding 这些 Fix-up 流程了,因为已经在预先绑定的地址加载好了。
rebase步骤先进行,需要把镜像读入内存,并以page为单位进行加密验证,保证不会被篡改,所以这一步的瓶颈在IO。bind在其后进行,由于要查询符号表,来指向跨镜像的资源,加上在rebase阶段,镜像已被读入和加密验证,所以这一步的瓶颈在于CPU计算。
Binding
Binding:将指针指向镜像外部的内容,binding就是将这个二进制调用的外部符号进行绑定的过程。比如我们objc代码中需要使用到NSObject, 即符号_OBJC_CLASS_$_NSObject,但是这个符号又不在我们的二进制中,在系统库 Foundation.framework中,因此就需要binding这个操作将对应关系绑定到一起;
lazyBinding就是在加载动态库的时候不会立即binding, 当时当第一次调用这个方法的时候再实施binding。 做到的方法也很简单: 通过dyld_stub_binder这个符号来做。lazyBinding的方法第一次会调用到dyld_stub_binder, 然后dyld_stub_binder负责找到真实的方法,并且将地址bind到桩上,下一次就不用再bind了。
Binding 是处理那些指向 dylib 外部的指针,它们实际上被符号(symbol)名称绑定,也就是个字符串。__LINKEDIT段中也存储了需要 bind 的指针,以及指针需要指向的符号。dyld 需要找到 symbol 对应的实现,这需要很多计算,去符号表里查找。找到后会将内容存储到 __DATA 段中的那个指针中。Binding 看起来计算量比 Rebasing 更大,但其实需要的 I/O 操作很少,Binding的时间主要是耗费在计算上,因为IO操作之前 Rebasing 已经替 Binding 做过了,所以这两个步骤的耗时是混在一起的。
可以从查看 __DATA 段中需要修正(fix-up)的指针,所以减少指针数量才会减少这部分工作的耗时。对于 ObjC 来说就是减少 Class,selector 和 category 这些元数据的数量。从编码原则和设计模式之类的理论都会鼓励大家多写精致短小的类和方法,并将每部分方法独立出一个类别,其实这会增加启动时间。
对于 C++ 来说需要减少虚方法,因为虚方法会创建 vtable,这也会在 __DATA 段中创建结构。虽然 C++ 虚方法对启动耗时的增加要比 ObjC 元数据要少,但依然不可忽视。最后推荐使用 Swift 结构体,它需要 fix-up 的内容较少。
Objective-C 中有很多数据结构都是靠 Rebasing 和 Binding 来修正(fix-up)的,比如 Class 中指向父类的指针和指向方法的指针。
Rebase&&Binding该阶段的优化关键在于减少__DATA segment中的指针数量。我们可以优化的点有:
减少Objc类数量, 减少selector数量,把未使用的类和函数都可以删掉
减少C++虚函数数量
转而使用swift stuct(其实本质上就是为了减少符号的数量,使用swift语言来开发?)
未使用类的扫描,可以利用linkmap文件和otool工机具反编译APP的可进行二进制文件得出一个大概的结果,但是不算非常精确,扫描出来后需要手动一个个确认。扫描原理大致是classlist和classref两者的差值,所有的类和使用了的类的差值就是未使用的类啦。因为未使用的类主要优化的是pre-main的时间,根据测试我们的工程pre-main时间并不长,所以本次并没有针对这一块做优化。(TODO:写脚本来验证这一点)。
ObjC SetUp
主要做以下几件事来完成Objc Setup:
读取二进制文件的 DATA 段内容,找到与 objc 相关的信息
注册 Objc 类,ObjC Runtime 需要维护一张映射类名与类的全局表。当加载一个 dylib 时,其定义的所有的类都需要被注册到这个全局表中;
读取 protocol 以及 category 的信息,把category的定义插入方法列表 (category registration),
确保 selector 的唯一性
ObjC 是个动态语言,可以用类的名字来实例化一个类的对象。这意味着 ObjC Runtime 需要维护一张映射类名与类的全局表。当加载一个 dylib 时,其定义的所有的类都需要被注册到这个全局表中。
C++ 中有个问题叫做易碎的基类(fragile base class)。ObjC 就没有这个问题,因为会在加载时通过 fix-up 动态类中改变实例变量的偏移量。
在 ObjC 中可以通过定义类别(Category)的方式改变一个类的方法。有时你想要添加方法的类在另一个 dylib 中,而不在你的镜像中(也就是对系统或别人的类动刀),这时也需要做些 fix-up。
ObjC 中的 selector 必须是唯一的。
由于之前2步骤的优化,这一步实际上没有什么可做的。几乎都靠 Rebasing 和 Binding 步骤中减少所需 fix-up 内容。因为前面的工作也会使得这步耗时减少。
Initializers
以上三步属于静态调整,都是在修改__DATA segment中的内容,而这里则开始动态调整,开始在堆和栈中写入内容。 工作主要有:
Objc的+load()函数
C++的构造函数属性函数 形如attribute((constructor)) void DoSomeInitializationWork()
非基本类型的C++静态全局变量的创建(通常是类或结构体)(non-trivial initializer) 比如一个全局静态结构体的构建,如果在构造函数中有繁重的工作,那么会拖慢启动速度
Objc的load函数和C++的静态构造函数采用由底向上的方式执行,来保证每个执行的方法,都可以找到所依赖的动态库
dyld开始将程序二进制文件初始化
交由ImageLoader读取image,其中包含了我们的类、方法等各种符号
由于runtime向dyld绑定了回调,当image加载到内存后,dyld会通知runtime进行处理
runtime接手后调用mapimages做解析和处理,接下来loadimages中调用 callloadmethods方法,遍历所有加载进来的Class,按继承层级依次调用Class的+load方法和其 Category的+load方法
整个事件由dyld主导,完成运行环境的初始化后,配合ImageLoader 将二进制文件按格式加载到内存,动态链接依赖库,并由runtime负责加载成objc 定义的结构,所有初始化工作结束后,dyld调用真正的main函数
C++ 会为静态创建的对象生成初始化器。而在 ObjC 中有个叫 +load 的方法,然而它被废弃了,现在建议使用 +initialize。对比详见StackOverflow的一个连接;
这一步可以做的优化有:
①使用 +initialize 来替代 +load
②不要使用 atribute((constructor)) 将方法显式标记为初始化器,而是让初始化方法调用时才执行。比如使用 dispatch_once(),pthread_once() 或 std::once()。也就是在第一次使用时才初始化,推迟了一部分工作耗时。也尽量不要用到C++的静态对象。
从效率上来说,在+load 和+initialize里执行同样的代码,效率是一样的,即使有差距,也不会差距太大。 但所有的+load 方法都在启动的时候调用,方法多了就会严重影响启动速度了。 就说我们项目中,有200个左右+load方法,一共耗时大概1s 左右,这块就会严重影响到用户感知了。
而+initialize方法是在对应 Class 第一次使用的时候调用,这是一个懒加载的方法,理想情况下,这200个+load方法都使用+initialize来代替,将耗时分摊到用户使用过程中,每个方法平均耗时只有5ms,用户完全可以无感知。 因为load是在启动的时候调用,而initialize是在类首次被使用的时候调用,不过当你把load中的逻辑移到initialize中时候,一定要注意initialize的重复调用问题,能用dispatch_once()来完成的,就尽量不要用到load方法。
如果程序刚刚被运行过,那么程序的代码会被dyld缓存,因此即使杀掉进程再次重启加载时间也会相对快一点,如果长时间没有启动或者当前dyld的缓存已经被其他应用占据,那么这次启动所花费的时间就要长一点,这就分别是热启动和冷启动的概念。下文中的启动时间统计,均统计的是第二次启动后的数据。(具体dyld缓存的是动态库还是APP的可执行代码,缓存多长时间,需要再研究,有懂的大神可以告知一下?)
见下图,出处是这里:

其实在我们APP的实践过程中也会遇到类似的事情,只不过我只统计了第二次启动后的时间,也就是定义中的热启动时间。
注:
通过在工程的scheme中添加环境变量DYLD_PRINT_STATISTICS,设置值为1,App启动加载时Xcode的控制台就会有pre-main各个阶段的详细耗时输出。但是DYLD_PRINT_STATISTICS 这个变量对真机的iOS9.3系统不行,iOS10就没问题。估计是iOS系统的bug.
pre-main阶段耗时的影响因素:
动态库加载越多,启动越慢。
ObjC类越多,函数越多,启动越慢。
可执行文件越大启动越慢。
C的constructor函数越多,启动越慢。
C++静态对象越多,启动越慢。
ObjC的+load越多,启动越慢。
整体上pre-main阶段的优化有:
①减少依赖不必要的库,不管是动态库还是静态库;如果可以的话,把动态库改造成静态库;如果必须依赖动态库,则把多个非系统的动态库合并成一个动态库;
②检查下 framework应当设为optional和required,如果该framework在当前App支持的所有iOS系统版本都存在,那么就设为required,否则就设为optional,因为optional会有些额外的检查;
③合并或者删减一些OC类和函数;关于清理项目中没用到的类,使用工具AppCode代码检查功能,查到当前项目中没有用到的类(也可以用根据linkmap文件来分析,但是准确度不算很高);有一个叫做[FUI](https://github.com/dblock/fui)的开源项目能很好的分析出不再使用的类,准确率非常高,唯一的问题是它处理不了动态库和静态库里提供的类,也处理不了C++的类模板。
④删减一些无用的静态变量,
⑤删减没有被调用到或者已经废弃的方法,方法见http://stackoverflow.com/questions/35233564/how-to-find-unused-code-in-xcode-7和https://developer.Apple.com/library/ios/documentation/ToolsLanguages/Conceptual/Xcode_Overview/CheckingCodeCoverage.html。
⑥将不必须在+load方法中做的事情延迟到+initialize中,尽量不要用C++虚函数(创建虚函数表有开销)
⑦类和方法名不要太长:iOS每个类和方法名都在__cstring段里都存了相应的字符串值,所以类和方法名的长短也是对可执行文件大小是有影响的;因还是object-c的动态特性,因为需要通过类/方法名反射找到这个类/方法进行调用,object-c对象模型会把类/方法名字符串都保存下来;
⑧用dispatch_once()代替所有的 attribute((constructor)) 函数、C++静态对象初始化、ObjC的+load函数;
⑨在设计师可接受的范围内压缩图片的大小,会有意外收获。压缩图片为什么能加快启动速度呢?因为启动的时候大大小小的图片加载个十来二十个是很正常的,图片小了,IO操作量就小了,启动当然就会快了,比较靠谱的压缩算法是TinyPNG。
我们的实践
统计了各个库所占的size(使用之前做安装包size优化的一个脚本),基本上一个公共库越大,类越多,启动时在pre-main阶段所需要的时间也越多。
所以去掉了Realm,DiffMatchPatch源码库,以及AlicloudHttpDNS,BCConnectorBundl,FeedBack,SGMain和SecurityGuardSDK几个库;
结果如下:
静态库,少了7M左右:
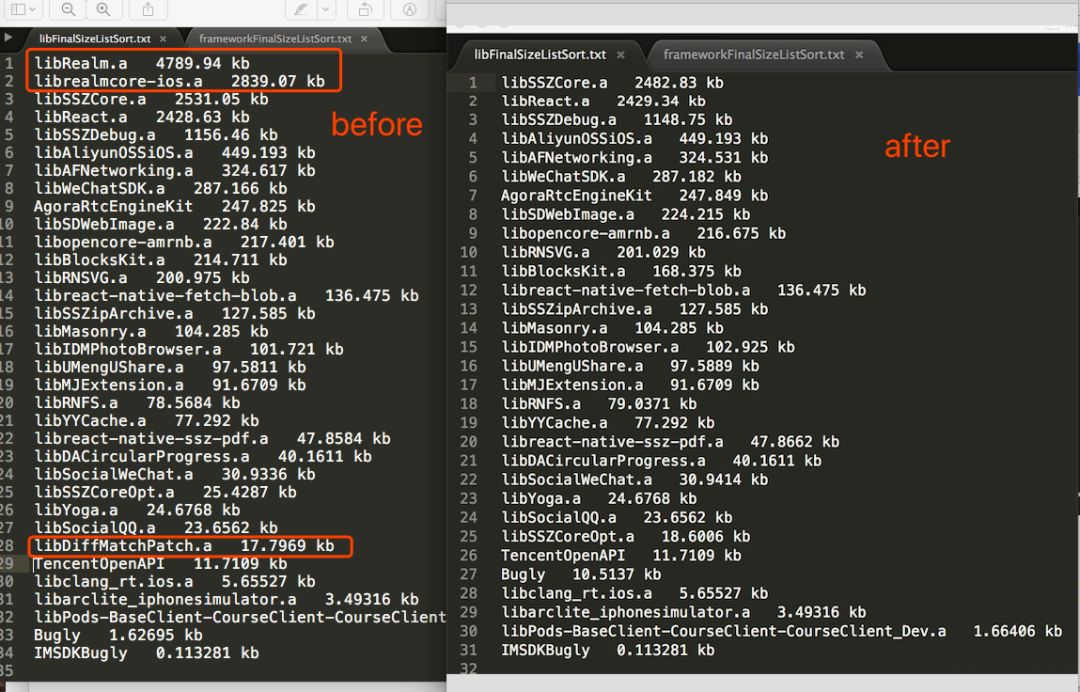
第三方framework(其实也是静态库,只是脚本会分开统计而已),少了1M左右:
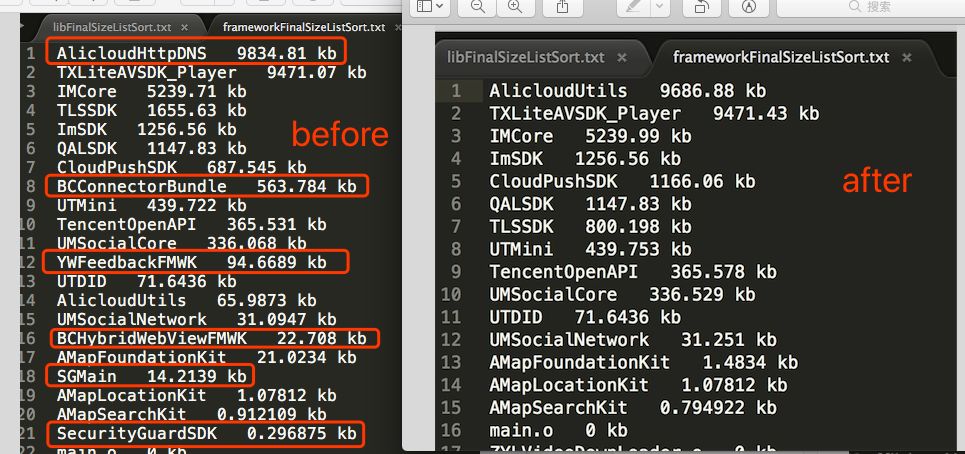
我们使用cocoapodbs并没有设置user_frameworks,所以pod管理的有源码的第三方库都是静态库的形式,而framework形式的静态库基本都是第三方公司提供的服务,上图可以看到,size占比最大的还是阿里和腾讯两家的SDK,比如阿里的推送和腾讯的直播和IM。
上图在统计中,AliCloudHttpDNS的可执行文件在Mac的Finder下的大小大概是10M,AlicloudUtils是3.4M,UTMini是16M,而UTDID只有1.6M。依赖关系上,AliCloudHttpDNS依赖AlicloudUtils,而AlicloudUtils依赖UTMini和UTDID,UTMini依赖UTDID。
上图中在统计上,应该是有所AlicloudUtils在左右两个图中size差值过大,应该是依赖关系中UTMini导致的统计偏差。两边几个库加起来的差值大概是200kb,这也应该是AlicloudHttpDNS这个库所占的size大小。
main阶段
总体原则无非就是减少启动的时候的步骤,以及每一步骤的时间消耗。
main阶段的优化大致有如下几个点:
减少启动初始化的流程,能懒加载的就懒加载,能放后台初始化的就放后台,能够延时初始化的就延时,不要卡主线程的启动时间,已经下线的业务直接删掉;
优化代码逻辑,去除一些非必要的逻辑和代码,减少每个流程所消耗的时间;
启动阶段使用多线程来进行初始化,把CPU的性能尽量发挥出来;
使用纯代码而不是xib或者storyboard来进行UI框架的搭建,尤其是主UI框架比如TabBarController这种,尽量避免使用xib和storyboard,因为xib和storyboard也还是要解析成代码来渲染页面,多了一些步骤;
这里重点讲一下多线程启动设计的原理
首先,iPhone有双核,除了维持操作系统运转和后台进程(包括守护进程等),在打开APP时,猜想双核中的另一个核应该有余力来帮忙分担启动的任务【待验证】;
其次,iPhone7开始使用A10,iPhone8开始使用A11处理器,根据维基百科的定义,A10 CPU包括两枚高性能核心及两枚低功耗核心,A11则包括两个高性能核心和四个高能效核心,而且相比A10,A11两个性能核心的速度提升了25%,四个能效核心的速度提升了70%。而且苹果还准备了第二代性能控制器,因此可以同时发挥六个核心的全部威力,性能提升最高可达70%,多线程能力可见一斑。
多线程测试结果如下图:
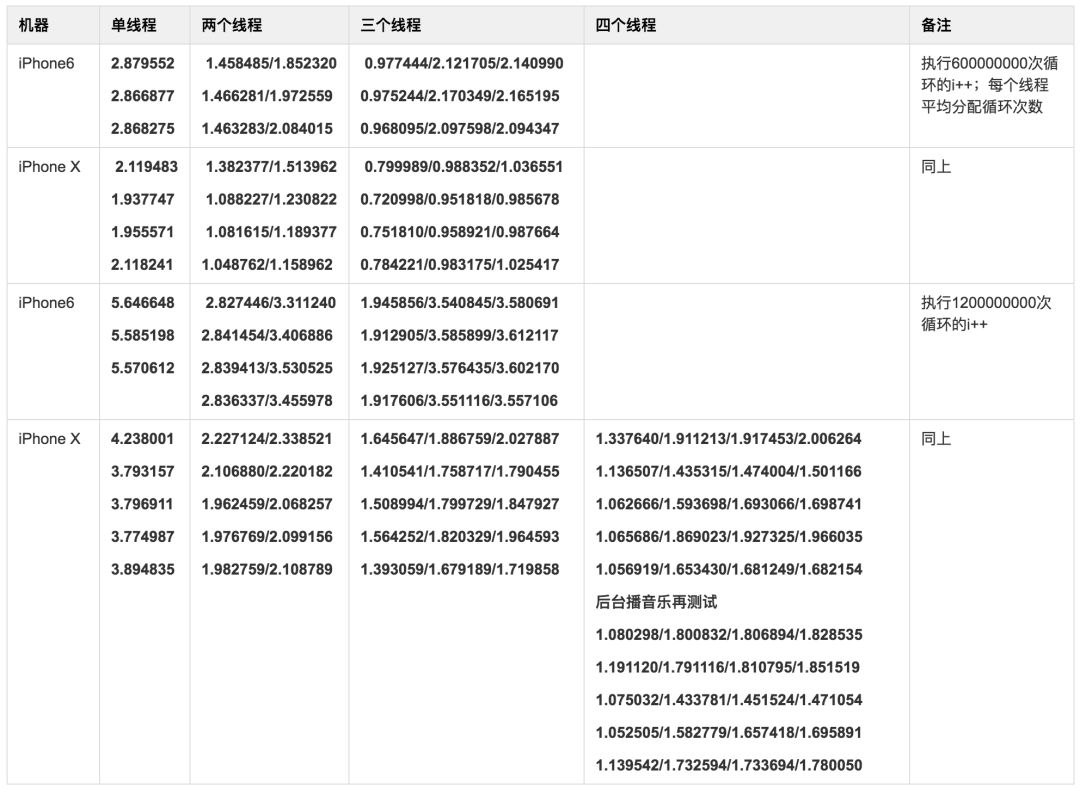
结论如下:
纯算法的CPU运算,指定计算的总数量,对于iPhone6和iPhone X来说,把计算量平均分配到多线程比全部放在主线程执行要快;
.iPhone6三个线程跟两个线程的总体耗时总体一致,甚至要多一点点,所以对于iPhone6来说用两个线程来做启动设计足够了;
iPhone X三个线程的耗时要比两个线程短一些,但是差值已经不算太大了;四个线程跟三个线程的总体一致,偶尔能比三个线程快一点点;
综上,利用多个线程来加速启动时间的设计,是合理的。
但是多线程启动的设计有几个需要注意的点:
黑屏问题;
用状态机来设计,每个状态机有2或3个线程在跑不同的任务,所有线程任务都完成后,进入到下一个状态,方便扩展;
线程保活问题,以及用完后要销毁;
资源竞争或线程同步造成卡死的问题。
针对第一点,多线程跑初始化任务的时候,可能主线程会有空闲等待子线程的阶段,而主线程一旦空闲,iOS系统的启动画面就会消失,如果此时APP尚未初始化完全,则可能会黑屏。为了避免黑屏,我们需要一个假的启动画面,在刚开始跑初始化任务时,就生成这个启动画面,启动过程完全结束后再去掉。或者当一个状态机里的主线程跑完时检查下是否所有线程都执行完任务了,如果没有则去生成这个假的初始化页面,避免黑屏。
第二点用状态机来设计启动,每个状态跑两个或者多个线程,单个状态里每个线程的耗时是不一样的,跑完一个状态再继续下一个状态,可以多次测试去动态调整分派到各个线程里的任务。
第三点线程保活则跟runloop有关,每个线程启动后,跑完一个状态,不能立马就回收,不然下一个状态的子线程就永远不会执行了;另外就是,APP初始化完成后,线程要注意回收。
第四点跟具体的业务有关,只要不是一个线程去做初始化,就有可能遇到线程间死锁的问题,比如下面采坑记录里就有提到一个例子。
我们在实践中大概做了以下的几点:
1.把启动时RN包的删除和拷贝操作,仅在APP安装后第一次启动时才做,之后的启动不再做这操作,而是等到网络请求RN数据回来,根据是否需要更新RN包的判断,再去做这些IO操作从而避免启动的耗时。iPhone5C能节省1.4s;
2.OSS token的获取不是一个需要在启动的时候必须要做的操作,放到子线程去处理,大部分时候是节省10-15ms,偶尔能去到50ms;
3.去掉启动状态机里的原有定位服务,原来SSZLocationManager的定位服务因为内部依赖高德的SDK,需要初始化SDK,iPhone5C大概耗时100ms。同时SSZLocationManager这个类代码保留,但是APP的工程去除对其的依赖;
4.打点统计模块里的定位服务权限请求改成异步,大概有50ms;
5.阿里百川的Feedback,在网校并没有使用,直接去掉其初始化流程,大概5ms左右;
6.友盟的分享服务,没有必要在启动的时候去初始化,初始化任务丢到后台线程解决,大概600-800ms;
7.状态机跑完后的启动内存统计,放到后台去做,大概50ms;
8.UserAgentManager里对于webview是否为UIWebview的判断,以前是新创建一个对象使用对象方法来判断,修改为直接使用类方法,避免创建对象的消耗,节省约200ms;
9.阿里云的HTTPDNS已经没有再使用了,所以这里也可以直接去掉。大概20-40ms;
10.SSZAppConfig里把网络请求放到后台线程,这样子就可以配合启动状态机把该任务放到子线程进行初始化了,否则子线程消耗的时间太长了;
11.采用两个线程来进行启动流程的初始化,用状态机来控制状态的变化。但是要针对业务区分开,并不是把一部分业务拆分到子线程,就可以让整体的启动速度更快;因为如果子线程有一些操作是要在主线程做的,有可能会出现等待主线程空闲再继续的情况;或者当两个线程的耗时操作都是IO时,拆开到两个线程,并不一定比单个线程去做IO操作要快。
12.主UI框架tabBarController的viewDidLoad函数里,去掉一些不必要的函数调用。
13.NSUserDefaults的synchronize函数尽量不要在启动流程中去调用,统一在APP进入后台,willTerminate和完全进入前台后把数据落地;
因为我们的项目用到了React Native技术(简称RN),所以会有RN包的拷贝和更新这一操作,之前的逻辑是每次启动都从bundle里拷贝一次到Document的指定目录,本次优化修正为除了安装后第一次启动拷贝,其他时候不在做这个拷贝操作,不过RN包热更新的覆盖操作,还是每次都要做检查的,如果有需要则执行更新操作
其中遇到几个坑:
①并不是什么任务都适合放子线程,有些任务在主线程大概10ms,放到子线程需要几百ms,因为某些任务内部可能会用到UIKit的api,又或者某些操作是需要提交到主线程去执行的,关键是要搞清楚这个任务里边究竟做了啥,有些SDK并不见得适合放到子线程去初始化,需要具体情况具体去测试和分析。
②AccountManager初始化导致的主线程卡死,子线程的任务依赖AccountManager,主线程也依赖,当子线程比主线程先调用时,造成了主线程卡死,其原因是子线程会提交一个同步阻塞的操作到主线程,而此时主线程被dipatch_one的锁锁住了,所以造成子线程不能返回,主线程也无法继续执行。调试的时候还会用到符号断点和LLDB去打印函数入参的值。
实际优化效果对比
由于只是去掉了几个静态库,而且本来pre-main阶段的耗时就不长,基本在200ms-500ms左右,所以pre-main阶段优化前后效果并不明显,有时候还没有前后测试的误差大。。。
main的阶段的优化效果还是很明显的:
iPhone5C iOS10.3.3系统优化前main阶段的时间消耗为4秒左右,优化后基本在1.8秒内;
iPhone7 iOS10.3.3系统优化前main阶段的时间消耗为1.1秒左右,优化后基本在600ms内;
iPhoneX iOS11.3.1系统优化前main阶段的时间消耗基本在1.5秒以上,优化后在1秒内;
可以看到,同样arm64架构的机器,main阶段是iPhone7比iPhoneX更快,说明就操作系统来说,iOS11.3要比iOS10.3慢不少;
详细测试数据见下图
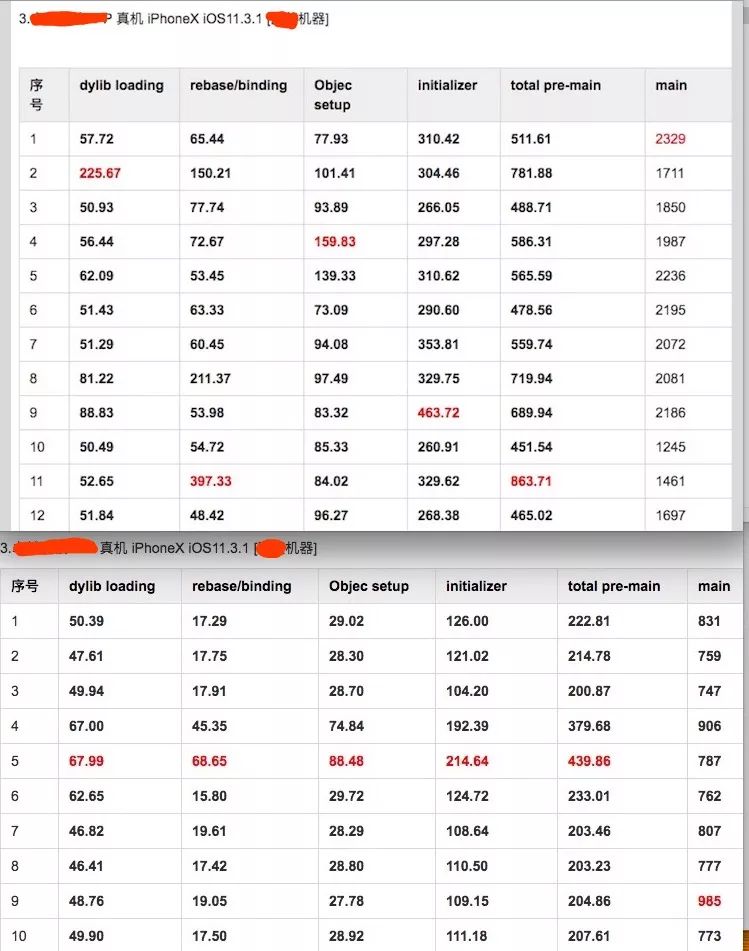
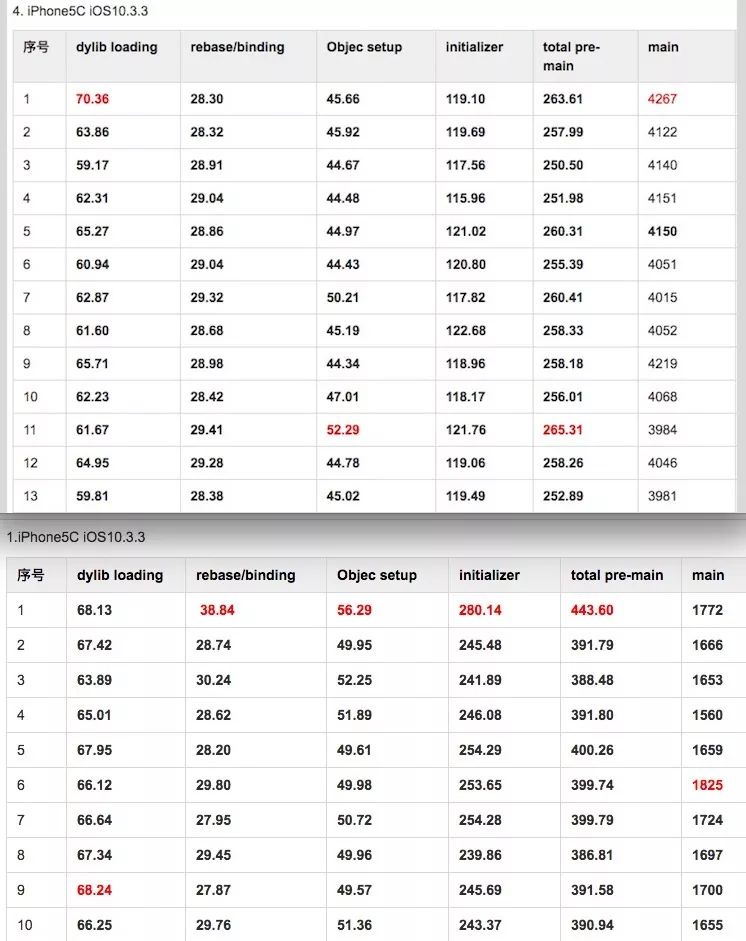
上图中iPhone5C为啥前后测试pre-main时间差值那么大?而且是优化后的值比优化前还要大?我也不知道,大概机器自己才知道吧。。。
注意:
1.关于冷启动和热启动,业界对冷启动的定义没有问题,普遍认为是手机开机后第一次启动某个APP,但是对热启动有不同的看法,有些人认为是按下home键把APP挂到后台,之后点击APP的icon再拉回来到前台算是热启动,也有些人认为是手机开机后在短时间内第二次启动APP(杀掉进程重启)算是热启动(此时dyld会对部分APP的数据和库进行缓存,所以比第一次启动要快)。
笔者认为APP从后台拉起到前台的时间没啥研究的意义,而即使是短时间内第二次启动APP,启动时间也是很重要的,所以在统计启动时间时,笔者会倾向于后一种说法,不过具体怎么定义还是看个人吧,知道其中的区别就好。
2.关于如何区分framework是静态库还是动态库见[这里](https://www.jianshu.com/p/1cfdf363143b )。原理就是在终端使用指令file,输出如果是ar archive就是静态库,如果是动态库则会输出dynamically linked相关信息。
特别鸣谢
在做启动优化的过程中,得到了很多朋友们的帮助和支持。借鉴了淮哥状态机的设计思路,同时也感谢singro大神的指点,感谢刘金哥叫我玩LLDB,感谢长元兄对于动态库和静态库的指教,感谢森哥的鞭策和精神鼓舞,以及展少爷在整个过程中的技术支持,引导和不耐其烦的解释,再次谢谢大家,爱你们哟😘!
参考链接:
相关推荐: