伸手党福利-从零开始玩转图库
本文已经获得作者的授权转载,如需转载,请联系作者授权
名词解释
vetex:节点
edge:边
graph:图
Tinkerpop
tinkerpop是一个图库标准,一个框架,学习图库,先从这个项目入手比较合适, neo4j, janusGraph只是它两个组件(图storage-engine)的vendor而已。图库是节点&边的集合,边描述了节点间的关联关系。

Tourist
打开gremlin-console,我们可以通过groovy语言对图进行curd操作,也可以使用gremlin语法进行遍历
$ bin/gremlin.sh
\,,,/
(o o)
-----oOOo-(3)-oOOo-----
plugin activated: tinkerpop.server
plugin activated: tinkerpop.utilities
plugin activated: tinkerpop.tinkergraph
gremlin>
ourist过程用到的数据库,可视化展示如下: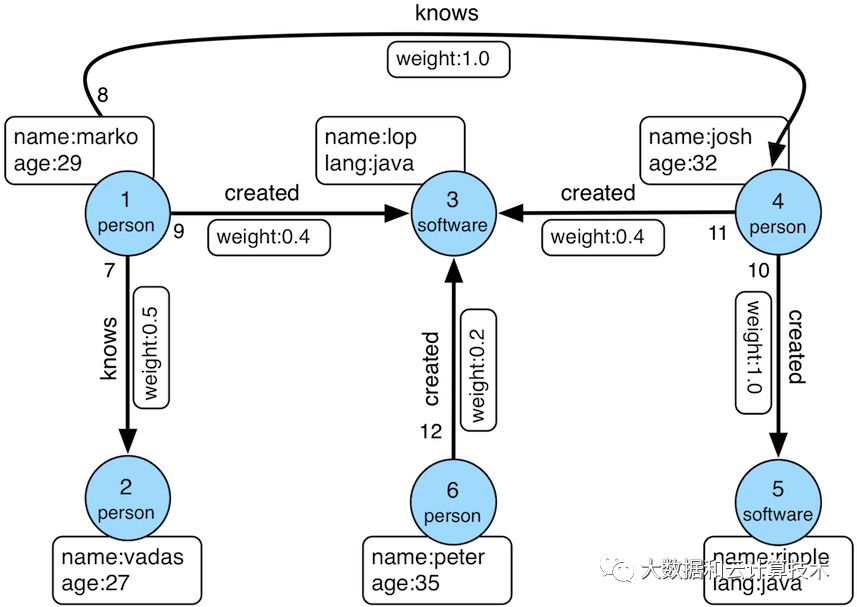
gremlin> graph = TinkerFactory.createModern()
==>tinkergraph[vertices:6 edges:6]
gremlin> g = graph.traversal()
==>graphtraversalsource[tinkergraph[vertices:6 edges:6], standard]
开始遍历
gremlin> g.V() //1
==>v[1]
==>v[2]
==>v[3]
==>v[4]
==>v[5]
==>v[6]
gremlin> g.V(1) //2
==>v[1]
gremlin> g.V(1).values('name') //3
==>marko
gremlin> g.V(1).outE('knows') //4
==>e[7][1-knows->2]
==>e[8][1-knows->4]
gremlin> g.V(1).outE('knows').inV().values('name') //5
==>vadas
==>josh
gremlin> g.V(1).out('knows').values('name') //6
==>vadas
==>josh
gremlin> g.V(1).out('knows').has('age', gt(30)).values('name') //7
==>josh
gremlin查询语法就不在此赘述了,请查阅官网文档。
模型
tinkerpop3 模型核心概念
Graph: 维护节点&边的集合,提供访问底层数据库功能,如事务功能
Element: 维护属性集合,和一个字符串label,表明这个element种类
Vertex: 继承自Element,维护了一组入度,出度的边集合
Edge: 继承自Element,维护一组入度,出度vertex节点集合.
Property: kv键值对
VertexProperty: 节点的属性,有一组健值对kv,还有额外的properties 集合。同时也继承自element,必须有自己的id, label.
Cardinality: 「single, list, set」 节点属性对应的value是单值,还是列表,或者set。
内存图库(TinkerGraph)数据结构
首先必须明确tinkerpop自带的内存图库(TinkerGraph)是全内存存储,数据条目不会太多。数据结构也就是标准的图的结构,持久化存储方式可参考janusGraph图库方式 让我们先了解Graph,vetex,Edge等数据结构。
Graph
Graph成员变量,可以看到有vertices,edges两个集合,分别管理节点、边。
protected Map<Object, Vertex> vertices = new ConcurrentHashMap<>();
protected Map<Object, Edge> edges = new ConcurrentHashMap<>();
vertex
自身的成员变量有属性,出度,入度的edge集合
protected Map<String, List<VertexProperty>> properties;
protected Map<String, Set<Edge>> outEdges;
protected Map<String, Set<Edge>> inEdges;
private final TinkerGraph graph; //引用
edge
一条边有传递方向,成员变量有入度及出度的节点
protected Map<String, Property> properties;
protected final Vertex inVertex;
protected final Vertex outVertex;
这样就完成了图的组织,可以看的出来从任意图中的一个起始节点,可以先找到出度的边,然后查询边的出度节点,这样travesal就跳到了下一个节点,反复如此即可完成对图的遍历。
highlevel-arch

gremlin server: httpserver/websocket server接收标准的gremlin dsl语法,自身相当于一个计算节点,完成图的遍历,或者操作DML语言,操作底层OLTP图库。
gremlin traversal language: 图的查询遍历语言及语言解释实现,类似sqlparser
provider strategies:vendor可自定义的策略,如对某些遍历步骤可优化,g.v(“filter”)可走全文搜索,而非全表scan。
core api(api for OLTP) 图库的curd操作,包括traveral,追求低延时,高吞吐,尽量少的慢查询。
graph computer(api for OLAP) 有MR/spark引擎,通过MR分治思想或DAG图做一些大数据处理,充分利用多机计算能力,这个规范是可选实现,此篇我们不会过多讨论。
核心在于提供gremlin查询语法及引擎,类似sqlparse,把查询语言转变成执行计划。还有core-api 节点,边的抽象,为底层OLTP&OLAP引擎可以自由切换成其他厂商实现,当然也内嵌了一套内存图库实现,以供vendor参考。
OLTP&OLAP
OLTP: real-time, limited data accessed, random data access, sequential processing, querying
OLAP: long running, entire data set accessed, sequential data access, parallel processing, batch processing
oltp vs olap
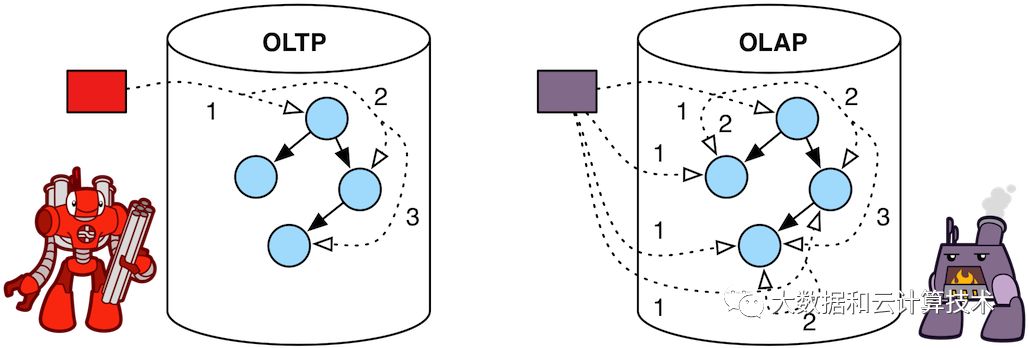
Graph Process
OLTP对于图的写操作都比较简单,我们就不讲了。我们来了解下traversal操作 GraphTraversal是由一组step组成,任何gremlin语法都会最终生成一个traversal,由多个步骤组成,如下示例
g.V(1).out("knows").values("name").iterate()
==>[TinkerGraphStep(vertex,[1]), VertexStep(OUT,[knows],vertex), PropertiesStep([name],value), NoneStep]
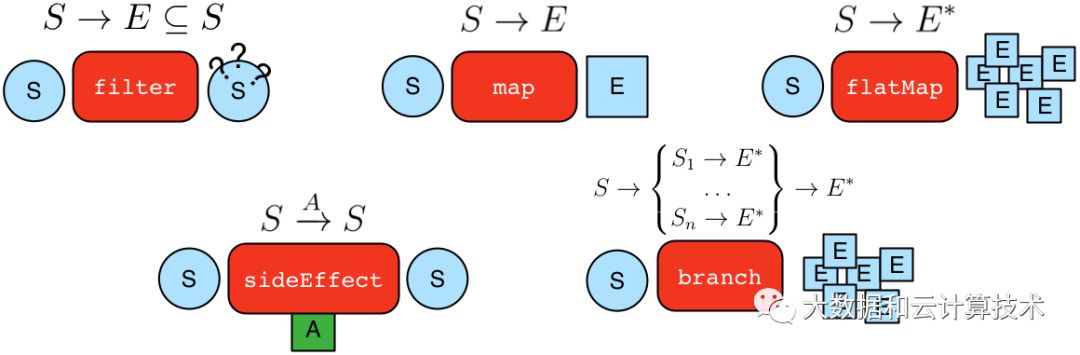
每个步骤都会变换上个步骤的输出,像管道pipe一样,抽像出以下5种变换方式,每个step其实都从这5种方式派生出来。
map: transform the incoming traverser’s object to another object (S → E).
flatMap: transform the incoming traverser’s object to an iterator of other objects (S → E*).
filter: allow or disallow the traverser from proceeding to the next step (S → E ⊆ S).
sideEffect: allow the traverser to proceed unchanged, but yield some computational sideEffect in the process (S ↬ S).
branch: split the traverser and send each to an arbitrary location in the traversal (S → { S1 → E, …, Sn → E } → E*).
图示
The Traverser
gremlin> g.V(marko).out('knows').values('name')
==>vadas
==>josh
当开始执行traversal时,traversal的源在表达式的左边(示例中的vertex1,marko节点)这些steps在traversal中间(示例种 out(‘knows’)以及values(‘name’)) 通过不断执行”traversal.next”输出到右边的结果(示例中的’vadas’和’josh’)
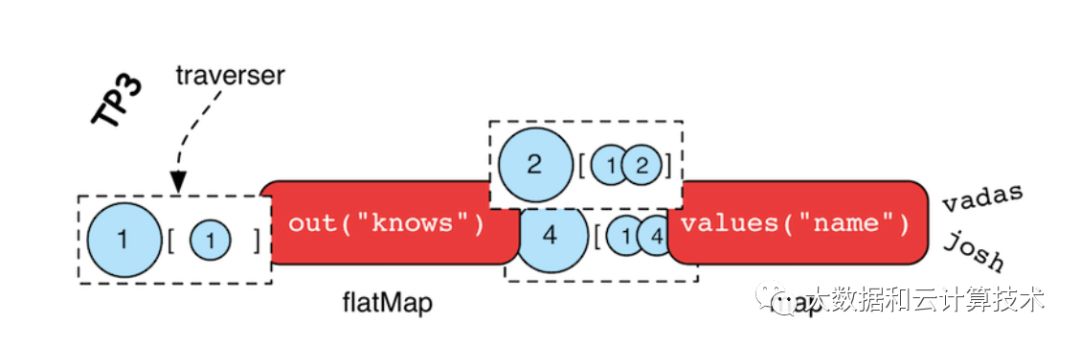
GraphTraversal inside
GraphTraversal通过了顶点,边等提供了对图数据的一种解释,并因此提供图形遍历DSL。S是起点,E是终点,包含如下4个主要组件
Step<S,E>: 独立的函数用于应用S到生产E,在traversal内部steps是链式串起来的。
TraversalStrategy: 方法拦截器,用于改变默认遍历执行
TraversalSideEffects: 键值对方式保存了traversal执行的全局信息。
Traverser: 代表了在当前遍历过程中数据流的一个状态,维护了到当前对象的引用 限于篇幅,更多内容查阅org.apache.tinkerpop.gremlin.process.traversal包对应的源码
局限
g.V(… ids) 或g.E(… ids) 指向性query,配合hbase使用没问题,但g.V().has(filter) 可就是全表扫描了,避免该问题要配合全文搜索引擎使用。 g.V()默认实现GraphStep会把vetex信息拉倒当前进程,会dump图库所有节点信息,操作重,条目过多很容易就OOM。
DSL语言设计之初就没有考虑过MPP体系,计算能力全压在当前进程,架设成常驻进程很容易出现CPU打满,QPS不足等问题。
JanusGraph
tinkerpop自带的图库基于内存,demo例子而已,我们看看其他一些供应商使用的一些持久化方案。
janusGraph集成了各大开源存储系统,如hbase,Cassandra,BerkeleyDB,以及整合开源搜索引擎,如solr, ElasticSearch. 总体来说实现了一个OLTP图库,OLAP标准在tinkerpop框架里面是可选的,我们暂时不关心janusGraph在OLAP方面工作.因为我们生产环境只使用hbase+solr,其他组件实现功能是镜像的,重点分析hbase+solr模式就好了。
官方文档所述优点
重点在强调scale-up
Support for very large graphs. JanusGraph graphs scale with the number of machines in the cluster.
Support for very many concurrent transactions and operational graph processing. JanusGraph’s transactional capacity scales with the number of machines in the cluster and answers complex traversal queries on huge graphs in milliseconds.
Support for global graph analytics and batch graph processing through the Hadoop framework.
Support for geo, numeric range, and full text search for vertices and edges on very large graphs.
Native support for the popular property graph data model exposed by Apache TinkerPop.
Native support for the graph traversal language Gremlin.
Easy integration with the Gremlin Server for programming language agnostic connectivity.
Numerous graph-level configurations provide knobs for tuning performance.
Vertex-centric indices provide vertex-level querying to alleviate issues with the infamous super node problem.
Provides an optimized disk representation to allow for efficient use of storage and speed of access.
Open source under the liberal Apache 2 license.
highlevel-arch
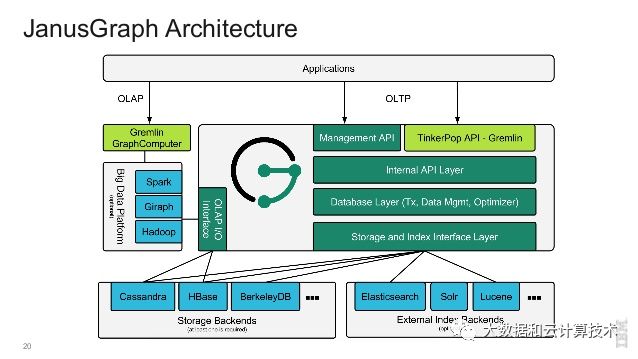
我们关注下OLTP方面,主要有api层,实现tinkpop api,底层storage api,这些是跟hbase/solr等打交道的,比较重要的工作在于database逻辑层,包括事务, 数据管理(节点、边curd),优化。 可以看出janusGraph功能还是比较少的,主要精力在数据建模方面,事务实现方面,底层hbase,solr都不支持事务,所以在hbase+solr模式下不支持事务,这方面我们也可以略过。
持久化模型
JanusGraph内部数据布局
JanusGraph将邻接表按行row保存在后台存储中。使用64位的顶点Id作Key指向相应顶点的邻接表row。每个边或属性在row中都是一个独立的cell,并且这些cell可以高效的完成插入和删除。每行(row)可以存储的cell最大数在hbase做存储场景下没限制,schema free随意新增列。
单条边的数据布局
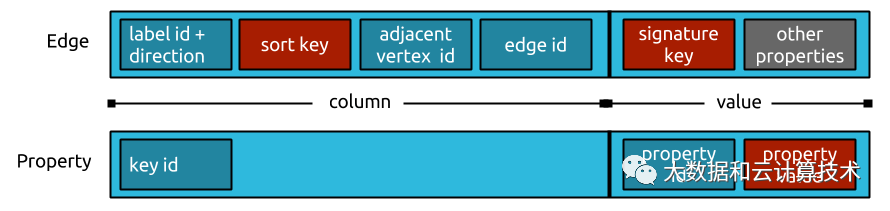
问题
并没有实现事务,无论是hbase还是solr均不支持事务,janusGraph只是号称说支持事务。
没有发挥MPP思想,一个计算节点负责所有的图遍历。存储层hbase分布式化了,但自身计算节点并没有分布式化。janusGraph把hbase当做黑盒,纯客户端,图遍历拉取所有数据,没有深入定制到表格存储里面,这也是可预见可修改的地方。
gremlin-server单机运算处理能力有限,势必要水平扩展,但core包中使用了有很多cache,有状态的,集群模式下要考虑内存状态一致性问题。
结束语-图库使用场景
推荐系统中,总有类似关联推荐
如:用户A喜欢某些item,推荐有相同兴趣其他用户所喜欢的item给用户A,在图库里面很容易实现。
/*"What has userA liked? Who else has liked those things? What have they liked that userA hasn't already liked?"*/
g.V(userA).out('liked').aggregate('x').in('liked').out('liked').
where(without('x')).values('name')
在搜索引擎中作为知识图谱弥补自然语言处理的不足 众所周知搜索引擎使用全文搜索的技术,本质上是term->document倒排索引,如下query ”XX明星的老婆的弟弟的舅舅的儿子叫什么“ 使用全文搜索方式完全丧失了答案的正确性,使用图数据库轻而易举能得到正确答案。另外edge提供权重属性,能帮助搜索引擎做rank打分。
g.V(star).out("wife").out("brother").out("uncle").out("son").values("name")
猜你喜欢
大数据和云计算技术周报(第56期)
加入技术讨论群
《大数据和云计算技术》社区群人数已经3000+,欢迎大家加下面助手微信,拉大家进群,自由交流。

喜欢QQ群的,可以扫描下面二维码:
欢迎大家通过二维码打赏支持技术社区(英雄请留名,社区感谢您,打赏次数超过108+):