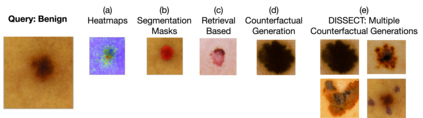
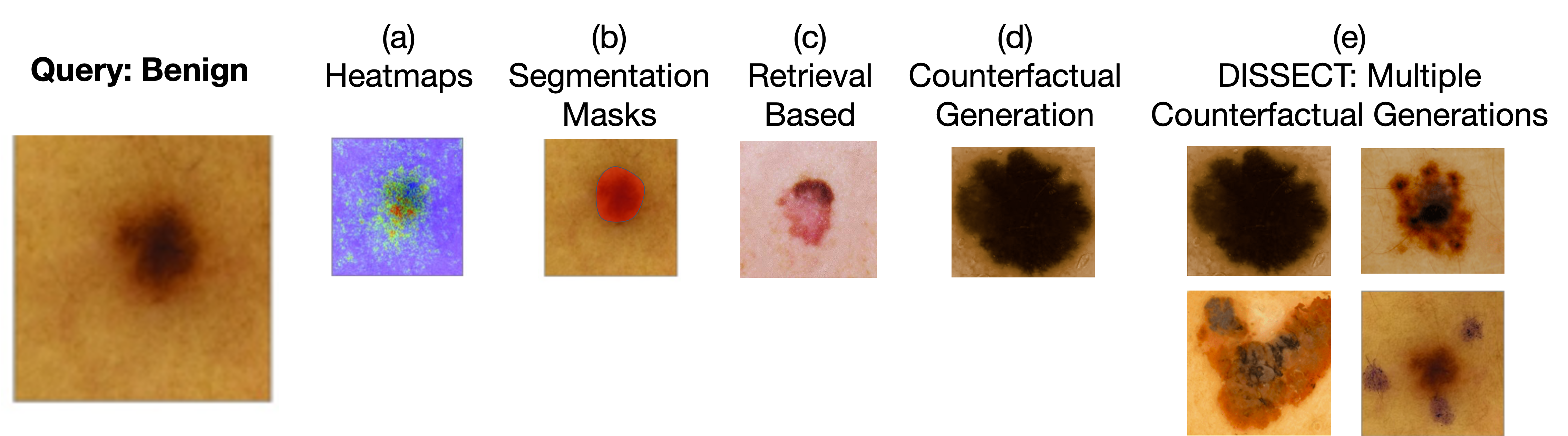
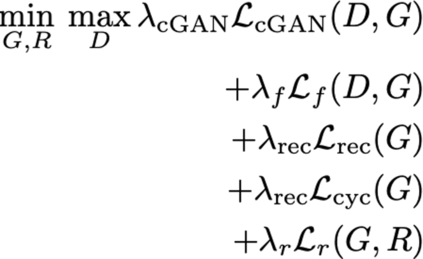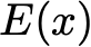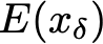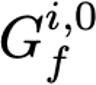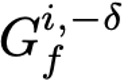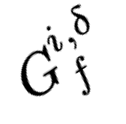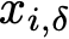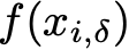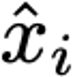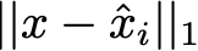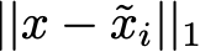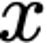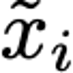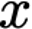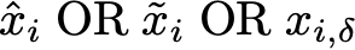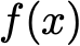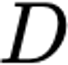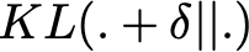Explaining deep learning model inferences is a promising venue for scientific understanding, improving safety, uncovering hidden biases, evaluating fairness, and beyond, as argued by many scholars. One of the principal benefits of counterfactual explanations is allowing users to explore "what-if" scenarios through what does not and cannot exist in the data, a quality that many other forms of explanation such as heatmaps and influence functions are inherently incapable of doing. However, most previous work on generative explainability cannot disentangle important concepts effectively, produces unrealistic examples, or fails to retain relevant information. We propose a novel approach, DISSECT, that jointly trains a generator, a discriminator, and a concept disentangler to overcome such challenges using little supervision. DISSECT generates Concept Traversals (CTs), defined as a sequence of generated examples with increasing degrees of concepts that influence a classifier's decision. By training a generative model from a classifier's signal, DISSECT offers a way to discover a classifier's inherent "notion" of distinct concepts automatically rather than rely on user-predefined concepts. We show that DISSECT produces CTs that (1) disentangle several concepts, (2) are influential to a classifier's decision and are coupled to its reasoning due to joint training (3), are realistic, (4) preserve relevant information, and (5) are stable across similar inputs. We validate DISSECT on several challenging synthetic and realistic datasets where previous methods fall short of satisfying desirable criteria for interpretability and show that it performs consistently well and better than existing methods. Finally, we present experiments showing applications of DISSECT for detecting potential biases of a classifier and identifying spurious artifacts that impact predictions.
翻译:许多学者认为,解释深层次学习模型的推理是科学理解、改善安全、发现隐蔽偏见、评价公平等有希望的场所。反事实解释的主要好处之一是允许用户通过数据中不存在和无法存在的东西探索“什么是”情景,而数据中不存在和无法存在的东西是许多其他形式的解释,如热图和影响功能等,其质量本质上是无法做到的。然而,以前关于基因解释性的工作大多无法有效地解析重要概念,无法产生不切实际的实例,或无法保留相关信息。我们提出了一种创新方法,即DISSECT,即联合培训一个发电机、一个导师和一个概念不连贯的概念,以便利用很少的监督来克服这些挑战。DISECT产生“什么是”的假设情景。DISECT产生一系列生成的范例,其概念程度越来越高,能够影响分类者的决定。通过从分类信号中培训一个归正模型,DISSECT提供一种自我们发现不同概念内在的“注释”,而不是依赖用户定义的概念。我们显示的是,具有更精确的直观的直观和精确的直观性,我们表明,其精确的直观的直观的直观的直观的直观的直观的直观的直观性,SLECT 。