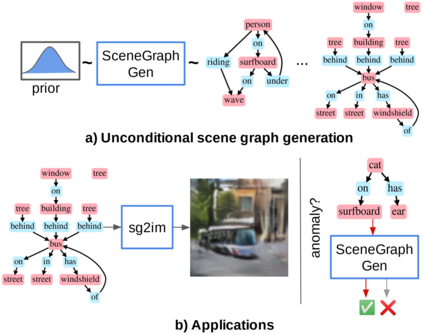
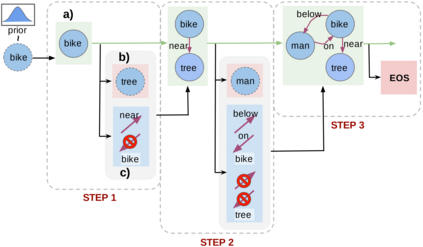
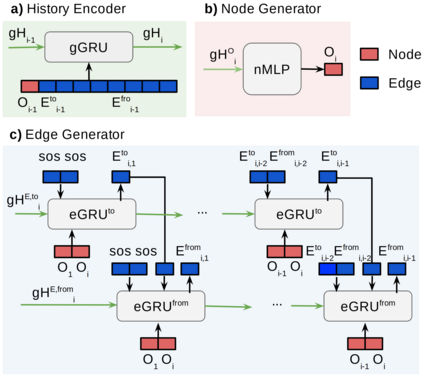
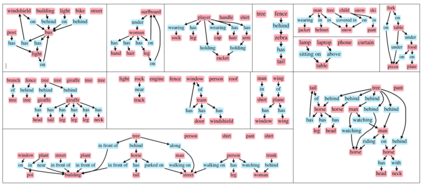
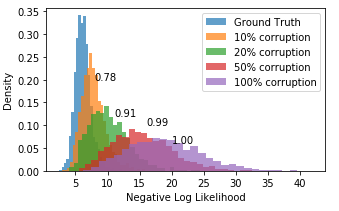
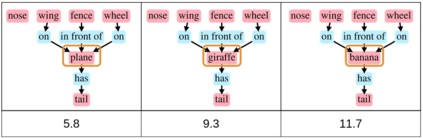
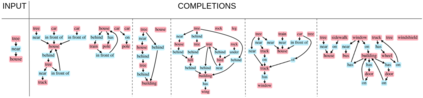
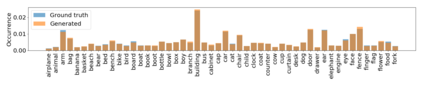
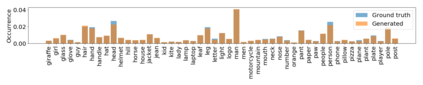
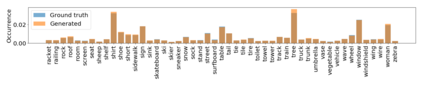
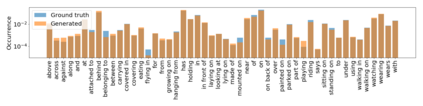
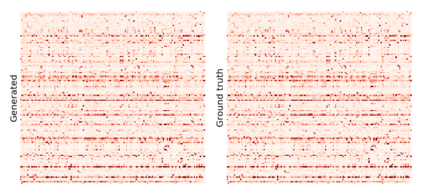
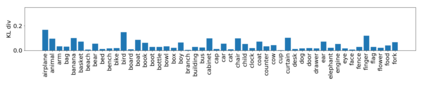
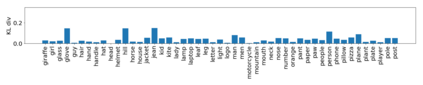
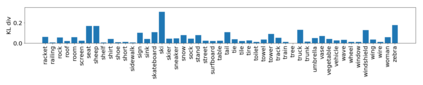
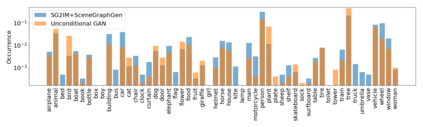
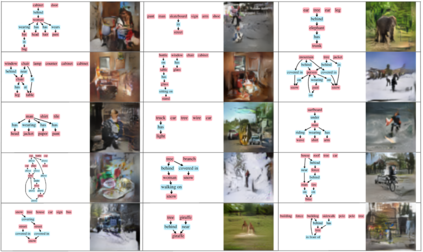
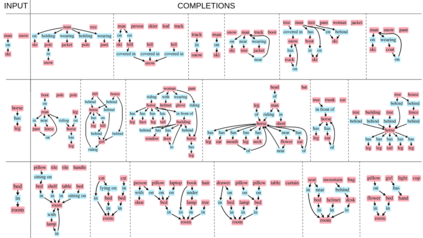
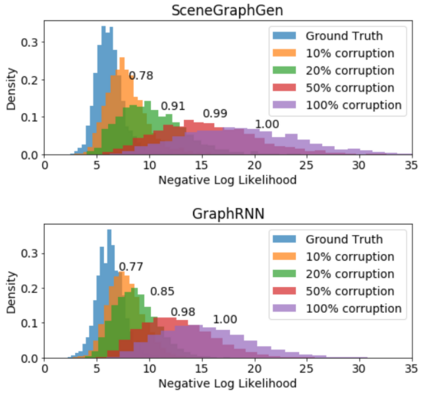
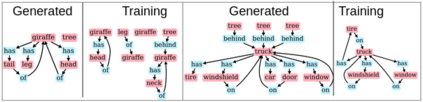
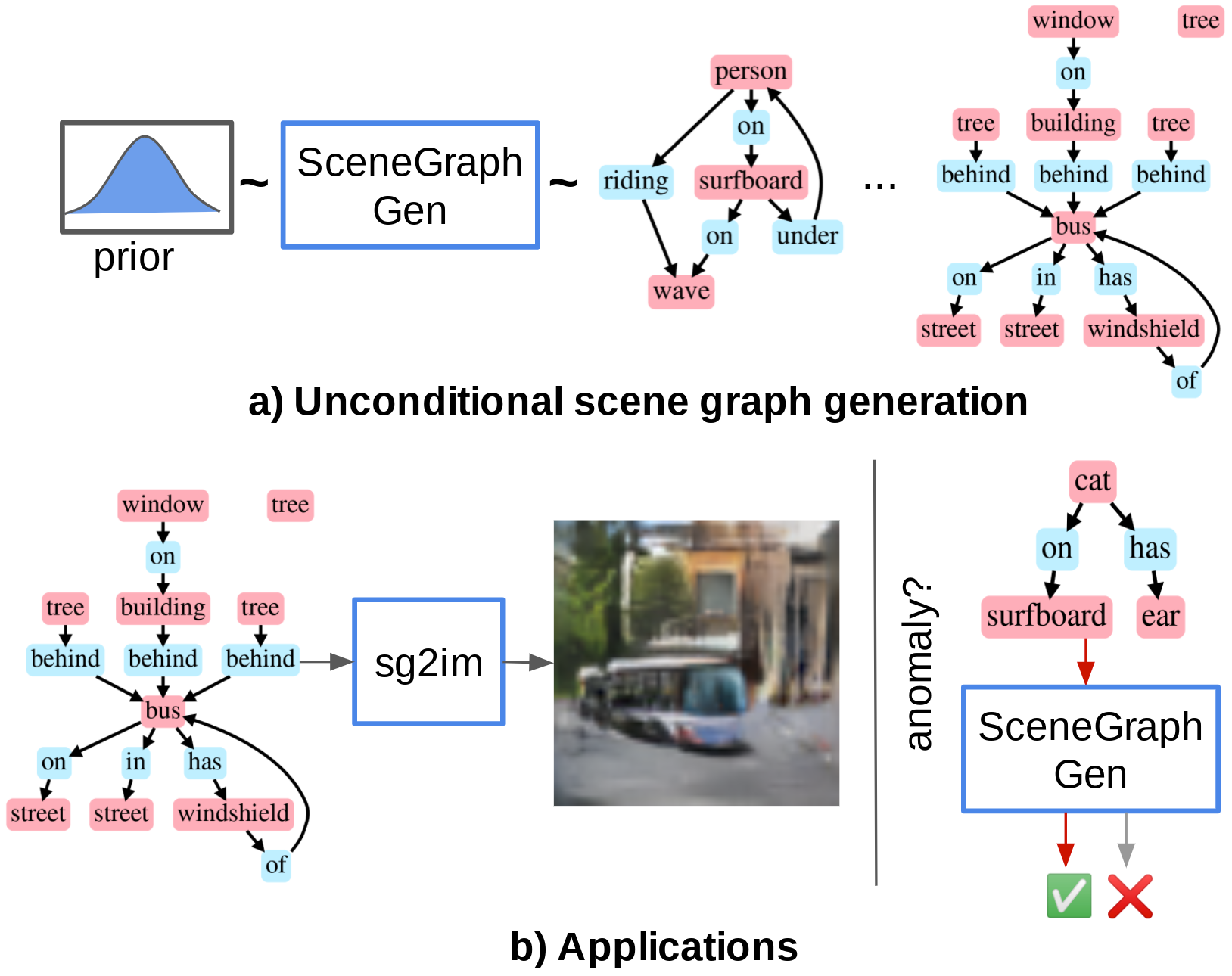
Despite recent advancements in single-domain or single-object image generation, it is still challenging to generate complex scenes containing diverse, multiple objects and their interactions. Scene graphs, composed of nodes as objects and directed-edges as relationships among objects, offer an alternative representation of a scene that is more semantically grounded than images. We hypothesize that a generative model for scene graphs might be able to learn the underlying semantic structure of real-world scenes more effectively than images, and hence, generate realistic novel scenes in the form of scene graphs. In this work, we explore a new task for the unconditional generation of semantic scene graphs. We develop a deep auto-regressive model called SceneGraphGen which can directly learn the probability distribution over labelled and directed graphs using a hierarchical recurrent architecture. The model takes a seed object as input and generates a scene graph in a sequence of steps, each step generating an object node, followed by a sequence of relationship edges connecting to the previous nodes. We show that the scene graphs generated by SceneGraphGen are diverse and follow the semantic patterns of real-world scenes. Additionally, we demonstrate the application of the generated graphs in image synthesis, anomaly detection and scene graph completion.
翻译:尽管最近单一域或单一对象图像生成工作有所进展,但生成包含不同、多个天体及其相互作用的复杂场景仍具有挑战性。由作为对象的节点构成的场景图和作为对象间关系的定向屏蔽镜像,提供了比图像更精度基础的场景的替代表象。我们假设,场景图的基因模型能够比图像更有效地学习真实世界场景的基本语义结构,从而产生以图像形式出现的现实新场景。我们在此工作中探索了无条件生成语义图像的新任务。我们开发了一个叫做SteneGraphen的深度自动递增模型,它可以直接学习标注和定向图形的概率分布,而使用一个等级的经常性结构。模型将种子对象作为输入,并在一系列步骤中生成一个场景图,每个步骤产生一个对象节点,然后以与前节点相连接的一系列关系边缘为背景。我们展示了SeneGraphen生成的场景图象图形图形是多种多样的,并遵循了真实图像的合成图状图状。我们展示了真实的图状图状图状。