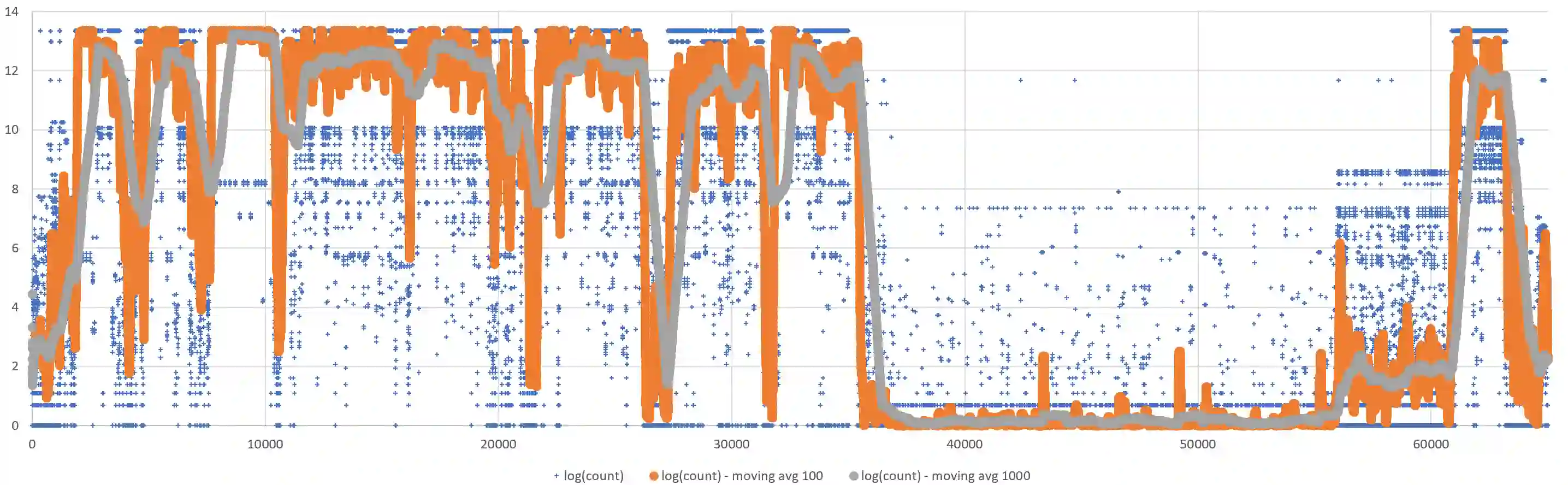
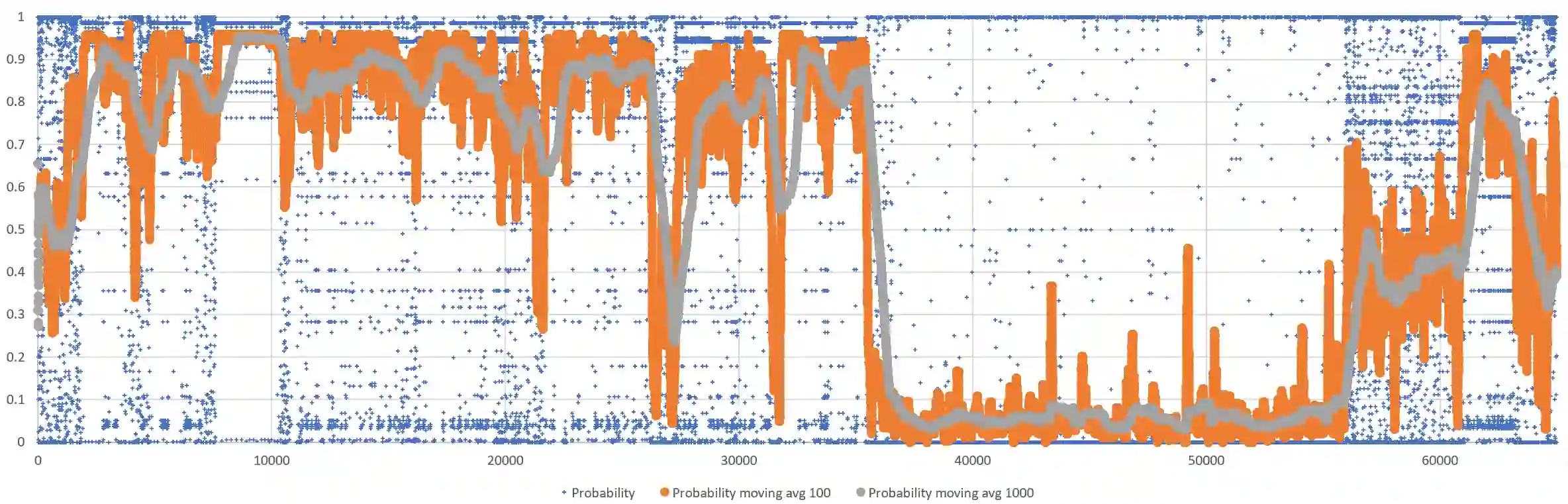
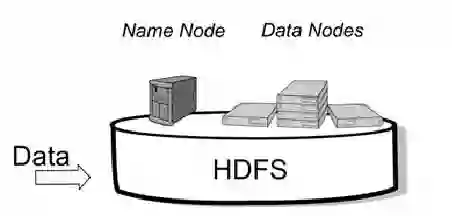
As stability testing execution logs can be very long, software engineers need help in locating anomalous events. We develop and evaluate two models for scoring individual log-events for anomalousness, namely an N-Gram model and a Deep Learning model with LSTM (Long short-term memory). Both are trained on normal log sequences only. We evaluate the models with long log sequences of Android stability testing in our company case and with short log sequences from HDFS (Hadoop Distributed File System) public dataset. We evaluate next event prediction accuracy and computational efficiency. The N-Gram model is more accurate in stability testing logs (0.848 vs 0.831), whereas almost identical accuracy is seen in HDFS logs (0.849 vs 0.847). The N-Gram model has superior computational efficiency compared to the Deep model (4 to 13 seconds vs 16 minutes to nearly 4 hours), making it the preferred choice for our case company. Scoring individual log events for anomalousness seems like a good aid for root cause analysis of failing test cases, and our case company plans to add it to its online services. Despite the recent surge in using deep learning in software system anomaly detection, we found no benefits in doing so. However, future work should consider whether our finding holds with different LSTM-model hyper-parameters, other datasets, and with other deep-learning approaches that promise better accuracy and computational efficiency than LSTM based models.
翻译:由于稳定性测试执行日志可能很长,软件工程师需要帮助定位异常事件。我们开发和评价两种模型,用于为异常事件评分单日志,即N-Gram模型和LSTM(长短期内存)的深学习模型。两种模型都只接受正常日志序列的培训。我们用公司案例的Android稳定性测试的长日志序列和从HDFS(Hatoop 分布式文件系统)公开数据集的短日志序列来评估模型。我们评估下一个事件的预测准确性和计算效率。N-Gram模型在稳定性测试日志(0.848848对0.831)中更为准确,而HDFS日志(0.849对0.847)中则几乎相同准确。N-Gram模型比深模型(4至13秒对16分钟至近4小时进行长期稳定测试)的计算效率测试。我们评估了这些模型的首选。我们分析案例的单个日志事件似乎有助于对失败的测试案例进行根源分析。N-Gram模型(0.848和0.831)中,而我们的案例公司计划几乎相同精确的精确的精确的精确的精确的准确性记录模型将维持着它的未来探测系统。我们将来的运行系统。我们是如何的测算。