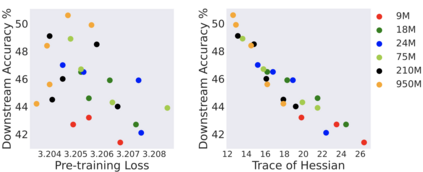
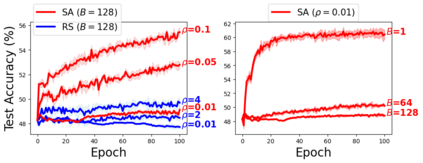
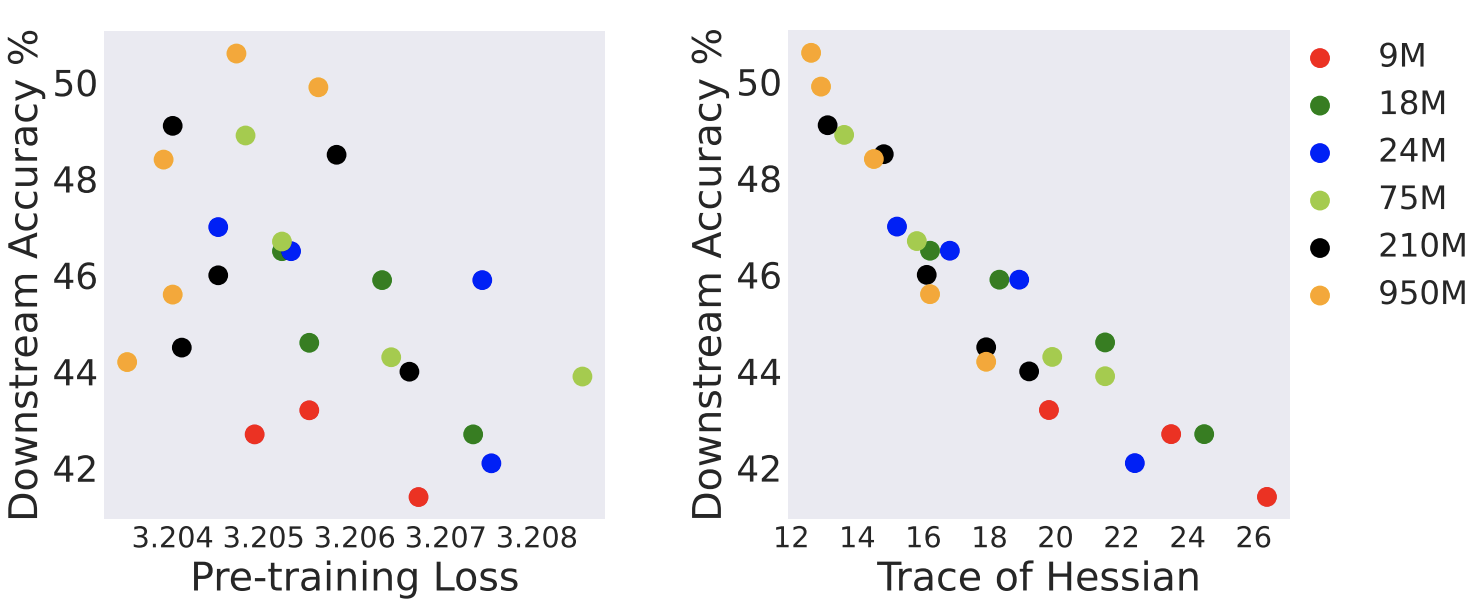
Modern machine learning applications have witnessed the remarkable success of optimization algorithms that are designed to find flat minima. Motivated by this design choice, we undertake a formal study that (i) formulates the notion of flat minima, and (ii) studies the complexity of finding them. Specifically, we adopt the trace of the Hessian of the cost function as a measure of flatness, and use it to formally define the notion of approximate flat minima. Under this notion, we then analyze algorithms that find approximate flat minima efficiently. For general cost functions, we discuss a gradient-based algorithm that finds an approximate flat local minimum efficiently. The main component of the algorithm is to use gradients computed from randomly perturbed iterates to estimate a direction that leads to flatter minima. For the setting where the cost function is an empirical risk over training data, we present a faster algorithm that is inspired by a recently proposed practical algorithm called sharpness-aware minimization, supporting its success in practice.
翻译:暂无翻译