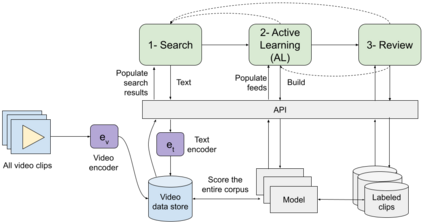
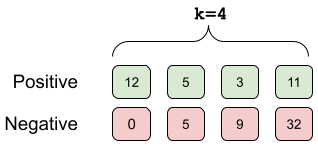
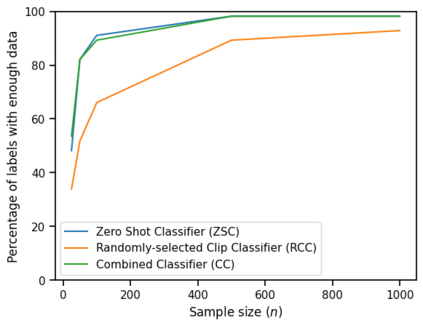
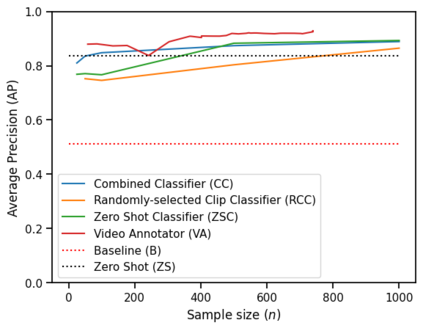
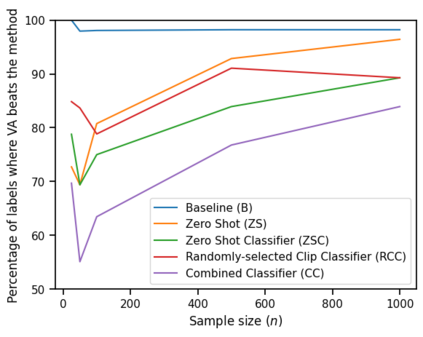
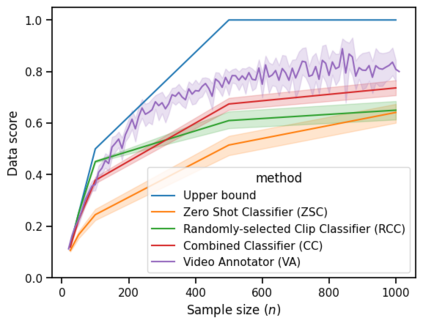
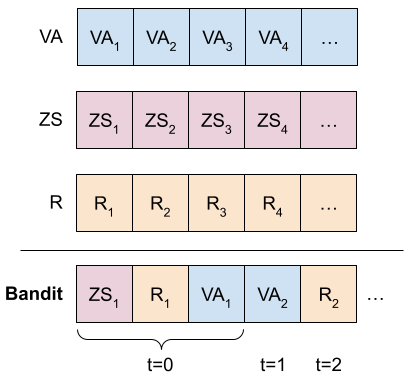
High-quality and consistent annotations are fundamental to the successful development of robust machine learning models. Traditional data annotation methods are resource-intensive and inefficient, often leading to a reliance on third-party annotators who are not the domain experts. Hard samples, which are usually the most informative for model training, tend to be difficult to label accurately and consistently without business context. These can arise unpredictably during the annotation process, requiring a variable number of iterations and rounds of feedback, leading to unforeseen expenses and time commitments to guarantee quality. We posit that more direct involvement of domain experts, using a human-in-the-loop system, can resolve many of these practical challenges. We propose a novel framework we call Video Annotator (VA) for annotating, managing, and iterating on video classification datasets. Our approach offers a new paradigm for an end-user-centered model development process, enhancing the efficiency, usability, and effectiveness of video classifiers. Uniquely, VA allows for a continuous annotation process, seamlessly integrating data collection and model training. We leverage the zero-shot capabilities of vision-language foundation models combined with active learning techniques, and demonstrate that VA enables the efficient creation of high-quality models. VA achieves a median 6.8 point improvement in Average Precision relative to the most competitive baseline across a wide-ranging assortment of tasks. We release a dataset with 153k labels across 56 video understanding tasks annotated by three professional video editors using VA, and also release code to replicate our experiments at: http://github.com/netflix/videoannotator.
翻译:暂无翻译