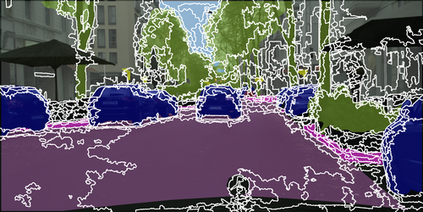
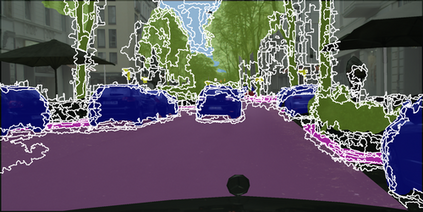
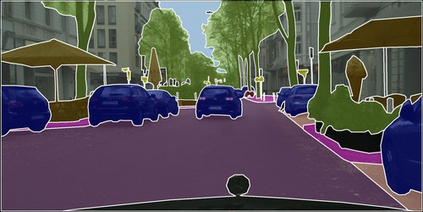
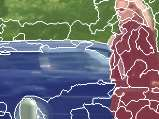
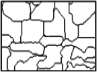
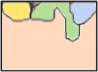
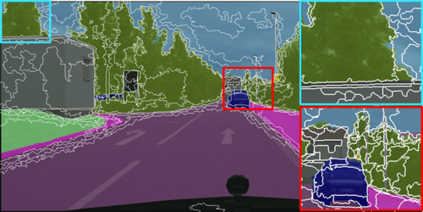
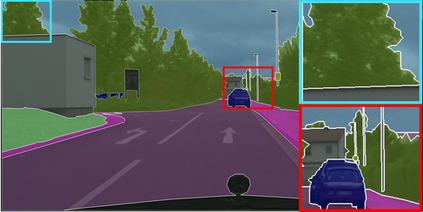
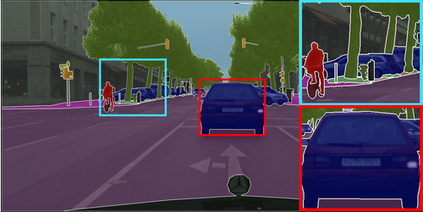
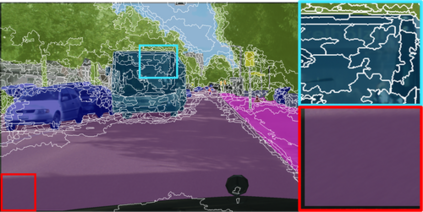
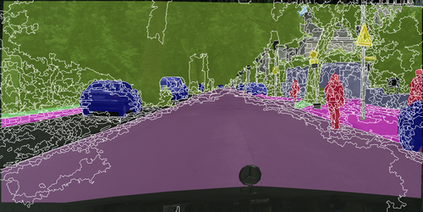
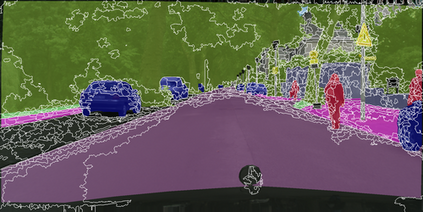
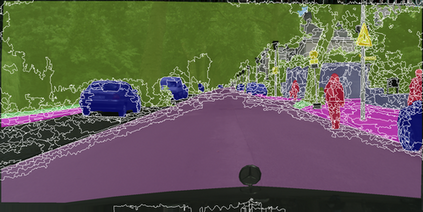
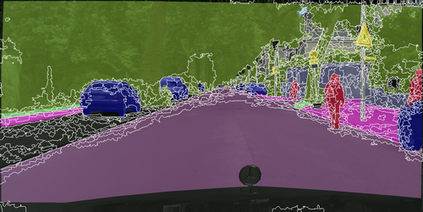
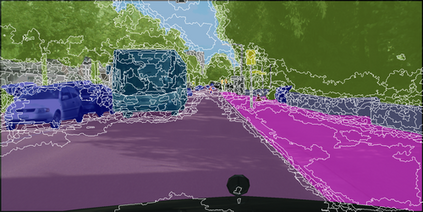
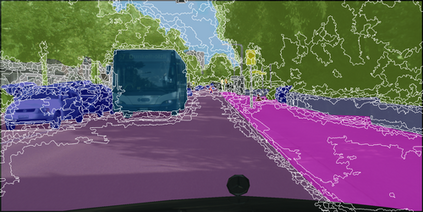
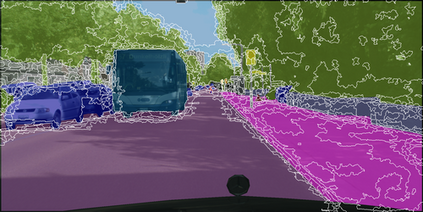
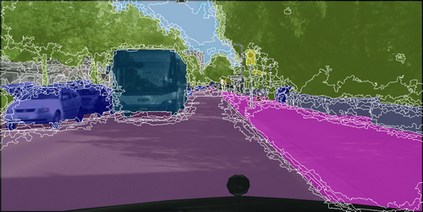
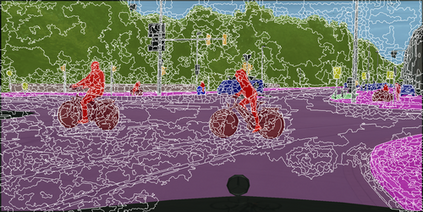
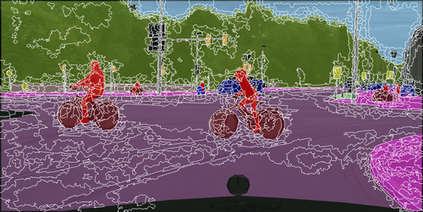
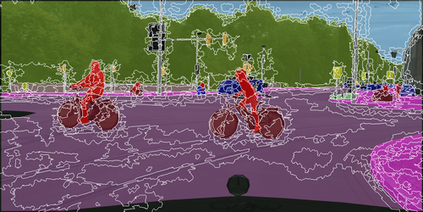
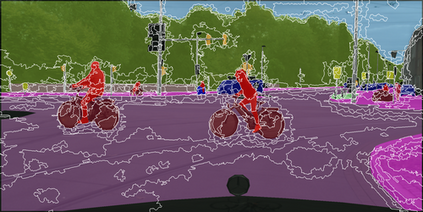
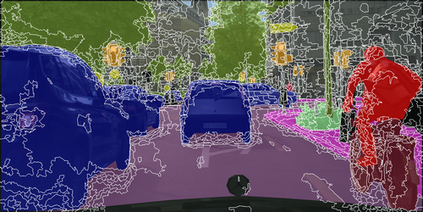
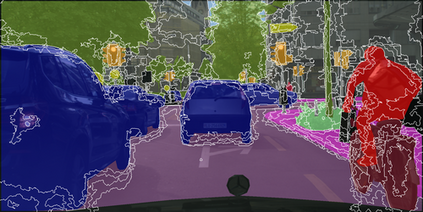
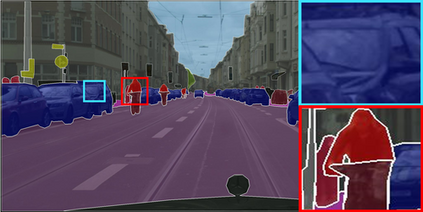
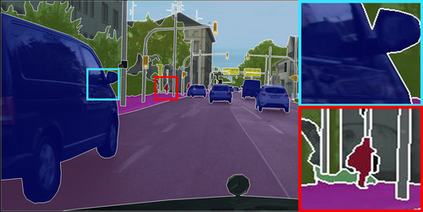
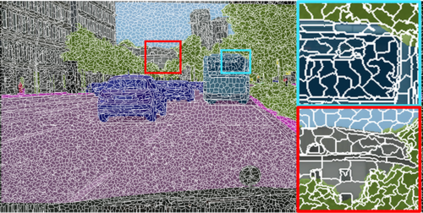
Learning semantic segmentation requires pixel-wise annotations, which can be time-consuming and expensive. To reduce the annotation cost, we propose a superpixel-based active learning (AL) framework, which collects a dominant label per superpixel instead. To be specific, it consists of adaptive superpixel and sieving mechanisms, fully dedicated to AL. At each round of AL, we adaptively merge neighboring pixels of similar learned features into superpixels. We then query a selected subset of these superpixels using an acquisition function assuming no uniform superpixel size. This approach is more efficient than existing methods, which rely only on innate features such as RGB color and assume uniform superpixel sizes. Obtaining a dominant label per superpixel drastically reduces annotators' burden as it requires fewer clicks. However, it inevitably introduces noisy annotations due to mismatches between superpixel and ground truth segmentation. To address this issue, we further devise a sieving mechanism that identifies and excludes potentially noisy annotations from learning. Our experiments on both Cityscapes and PASCAL VOC datasets demonstrate the efficacy of adaptive superpixel and sieving mechanisms.
翻译:学习语义分割需要像素级别的注释,这可能耗时且昂贵。为了减少注释成本,我们提出了一种基于超像素的主动学习(AL)框架,该框架收集每个超像素的主导标签。具体而言,它由适应性超像素和筛选机制组成,专门用于AL。在每个AL回合中,我们自适应地将相似学习特征的邻近像素合并为超像素。然后,我们使用获取函数查询所选子集的这些超像素,假定没有统一的超像素大小。这种方法比现有方法更有效,现有方法只依赖于固有特征(例如RGB颜色)并假定统一的超像素大小。获取每个超像素的主导标签可以显著降低注释员的负担,因为它需要点击的数量较少。然而,它不可避免地会由于超像素和地面实况分割之间的不匹配而引入嘈杂的注释。为解决这个问题,我们进一步设计了一个筛选机制,可以识别和排除学习中可能存在噪声的注释。我们在Cityscapes和PASCAL VOC数据集上的实验证明了自适应超像素和筛选机制的有效性。