Successor representations 强化学习表示的生物学启发
关键词:
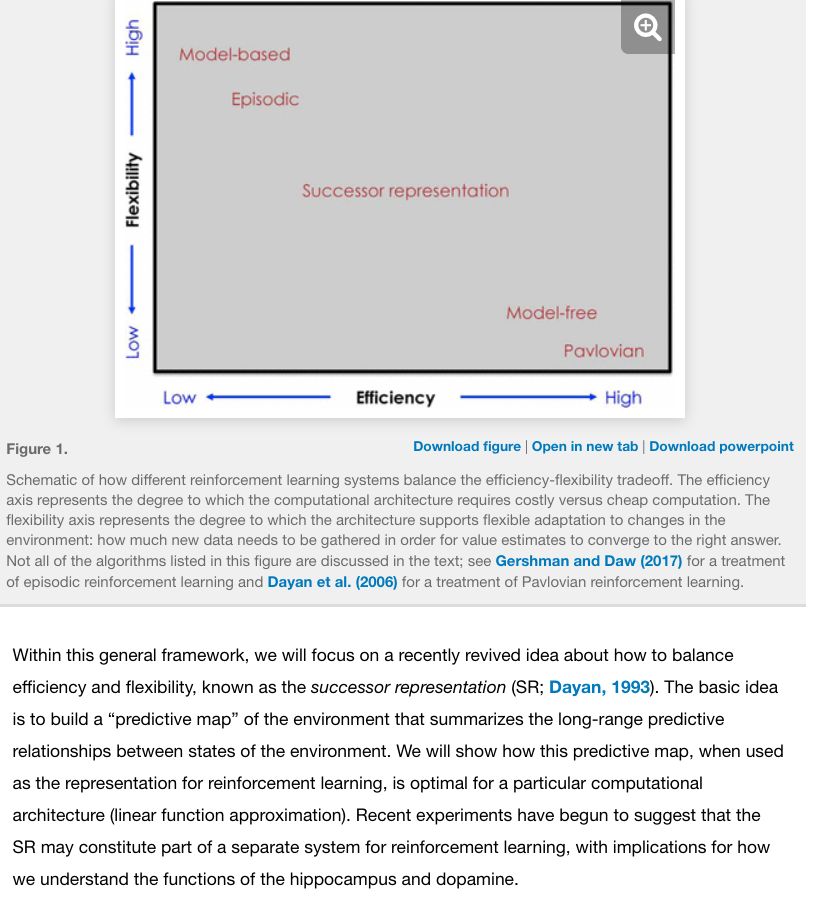
model base model free 相互关系的生物学解读 前额叶 多巴胺 Goal-directed behavior vs. habits Successor representations
temporal difference (TD) algorithm, where the reward prediction error (RPE)
sensory prediction error (SPE) similar to the TD RPE
The Successor Representation: Its Computational Logic and Neural Substrates
https://www.jneurosci.org/content/38/33/7193
生物学的SR解读



Behavioral evidence
Animals and humans are capable of “goal-directed” behavior, nimbly adapting to changes in the environment or their internal states as they pursue their goals. For example, Adams (1982) showed that rats trained to press a lever for sucrose subsequently ceased lever pressing in an extinction test after the sucrose was separately paired with illness (thereby devaluing the sucrose reinforcer) in the absence of the lever. It is critical that the rats did not have the opportunity to relearn the value of lever pressing after the devaluation treatment, thus ruling out a purely model-free account of behavior. Similarly, the observation that animals can learn under a variety of circumstances without direct reinforcement, such as latent learning (Tolman, 1948), is difficult to reconcile with model-free learning. Rather, these experimental phenomena have been interpreted as evidence for model-based control (Daw et al., 2005). However, they are not, as it turns out, strongly diagnostic of model-based control: they can be alternatively explained by SR-based accounts (Russek et al., 2017).



https://julien-vitay.net/2019/05/successor-representations/ 笔记:
successor representations
model base(MB) model free(MF) 相互关系的生物学解读 前额叶 多巴胺 Goal-directed behavior vs. habits Successor representations
temporal difference (TD) algorithm, where the reward prediction error (RPE)
sensory prediction error (SPE) similar to the TD RPE
https://julien-vitay.net/2019/05/successor-representations/
main drawback of MF methods is their inflexibility when the reward distribution changes
each action leading to that transition has to be experienced multiple times before the corresponding values reflect that change. This is due to the use of the temporal difference (TD) algorithm, where the reward prediction error (RPE) is used to update values:
When the reward associated to a transition changes drastically, only the last state (or action) is updated after that experience (unless we use eligibility traces). Only multiple repetitions of the same trajectory would allow changing the initial decisions. This is opposite to MB methods, where a change in the reward distribution would very quickly influence the planning of the optimal trajectory. In MB, the reward probabilities can be estimated with:
Pavlovian conditioning, DA cells react phasically to unconditioned stimuli (US, rewards). After enough conditioning trials, DA cells only react to conditioned stimuli (CS), i.e. stimuli which predict the delivery of a reward.
goal-directed behavior would quickly learn to avoid that outcome, while habitual behavior will continue to seek for it. Over-training can transform goal-directed behavior into habits (Corbit and Balleine, 2011). Habits are usually considered as a model-free learning behavior, while goal-directed behavior implies the use of a world model.
The SR algorithm learns two quantities:
The expected immediate reward received after each state:

The SR represents the fact that a state s′ can be reached after s, with a value decreasing with the temporal gap between the two states: states occurring in rapid succession will have a high SR, very distant states will have a low SR. If s′ happens consistently before s, the SR should be 0 (causality principle). This is in principle similar to model-based RL, but without an explicit representation of the transition structure: it only represents how states are temporally correlated, not which action leads to which state

In short: is arriving in this new state surprising? It should be noted that the SPE is defined over all possible successor states s′, so the SPE is actually a vector.
SR is a trade-off between MF and MB methods. A change in the reward distribution can be quickly tracked by SR algorithms, as the immediate reward r(s) can be updated with:
Δr(s)=α(rt+1−r(s))
However, the SR M(s,s′) uses other estimates for its update (bootstrapping), so changes in the transition structure may take more time to propagate to all state-state discounted occupancies (Gershman, 2018).
Each feature can for example be the presence of an object in the scene, some encoding of the position of the agent in the world, etc. The SR for a state s only needs to predict the expected discounted probability that a feature fj will be observed in the future, not the complete state representation. This should ensure generalization across states, as only the presence of relevant features is needed. The SR can be linearly approximated by:
The SPE tells us how surprising is each feature fj when being in the state st. This explains the term sensory prediction error: we are now not learning based on how surprising rewards are anymore, but on how surprising the sensory features of the outcome are. Did I expect that door to open at some point? Should this event happen soon? What kind of outcome is likely to happen? As the SPE is now a vector for all sensory features, we see why successor representation have a great potential: instead of a single scalar RPE dealing only with reward magnitudes, we now can learn from very diverse representations describing the various relevant dimensions of the task. It can then deal with different rewards: food and monetary rewards are treated the same by RPEs, while we can distinguish them with SPEs.

The main potential problem is of course to extract the relevant features for the task
use information bottleneck ??
3 - Successor representations in neuroscience
It is hard to conclude anything definitive from this model and the somehow artificial fit to the data. Reward revaluation was the typical test to distinguish between MB and MF processes, or between goal-directed behavior and habits. This paper suggests that transition revaluation (and policy revaluation, investigated in the second experiment) might allow distinguishing between MB and SR mechanisms, supporting the existence of SR mechanisms in the brain. How MB and SR might interact in the brain and whether there is an arbitration mechanism between the two is still an open issue. (Russek et al., 2017) has a very interesting discussion on the link between MF and MB processes in the brain, based on different versions of the SR.
3.2 - Neural substrates of successor representations
In addition to describing human behavior at the functional level, the SR might also allow to better understand the computations made by the areas involved in goal-directed behavior, in particular the prefrontal cortex, the basal ganglia, the dopaminergic system, and the hippocampus. The key idea of Gershman and colleagues is that the SR M(s,s′) might be encoded in the place cells of the hippocampus (Stachenfeld et al., 2017), which are known to be critical for reward-based navigation. The sensory prediction error (SPE δSRt) might be encoded in the activation of the dopaminergic cells in VTA (or in a fronto-striatal network), driving learning of the SR in the hippocampus (Gardner et al., 2018), while the value of a state Vπ(s)=∑s′M(s,s′)r(s′) could be computed either in the prefrontal cortex (ventromedial or orbitofrontal) or in the ventral striatum (nucleus accumbens in rats), ultimately allowing action selection in the dorsal BG.
Dopamine as a SPE
The most striking prediction of the SR hypothesis is that the SPE is a vector of prediction errors, with one element per state (in the original formulation) or per reward feature (using linear function approximation, section 2.2). This contrasts with the classical RPE formulation, where dopaminergic activation is a single scalar signal driving reinforcement learning in the BG and prefrontal cortex.
Neurons in VTA have a rather uniform response to rewards or reward-predicting cues, encoding mostly the value of the outcome regardless its sensory features, except for those projecting to the tail of the striatum which mostly respond to threats and punishments (Watabe-Uchida and Uchida, 2019). The current state of knowledge seems to rule out VTA as a direct source of SPE signals.
欢迎加入打卡群自律学习强化学习,更欢迎支持或加入我们!请参考公众号createAmind菜单说明。




