
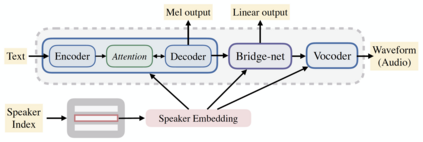
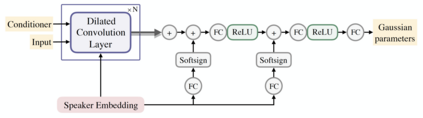
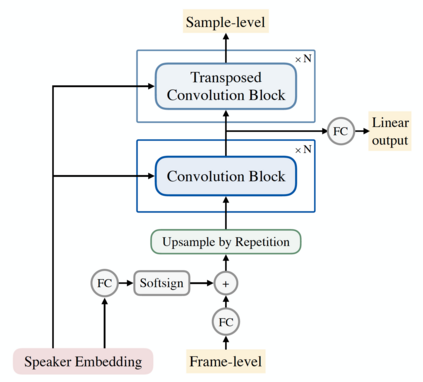
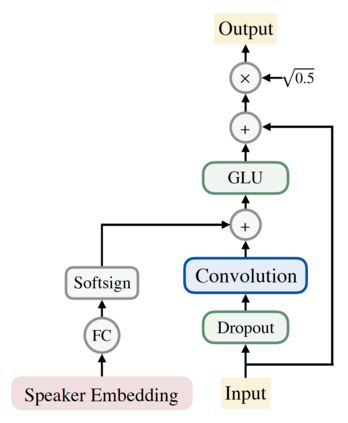
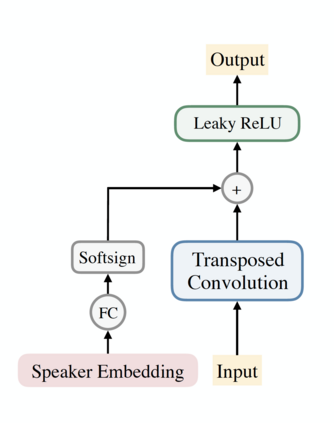
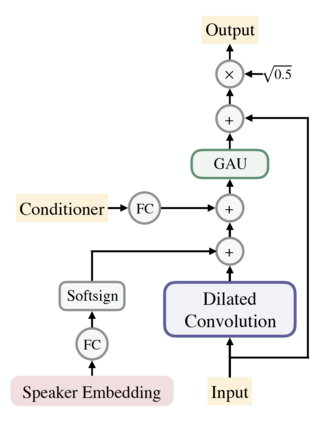
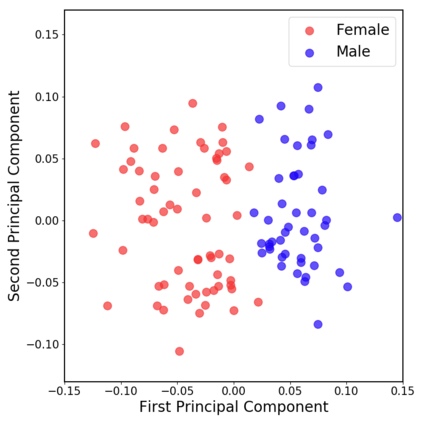
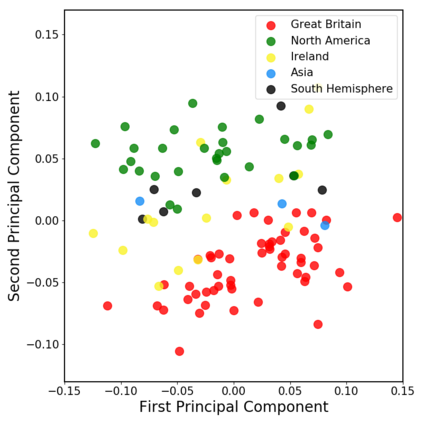
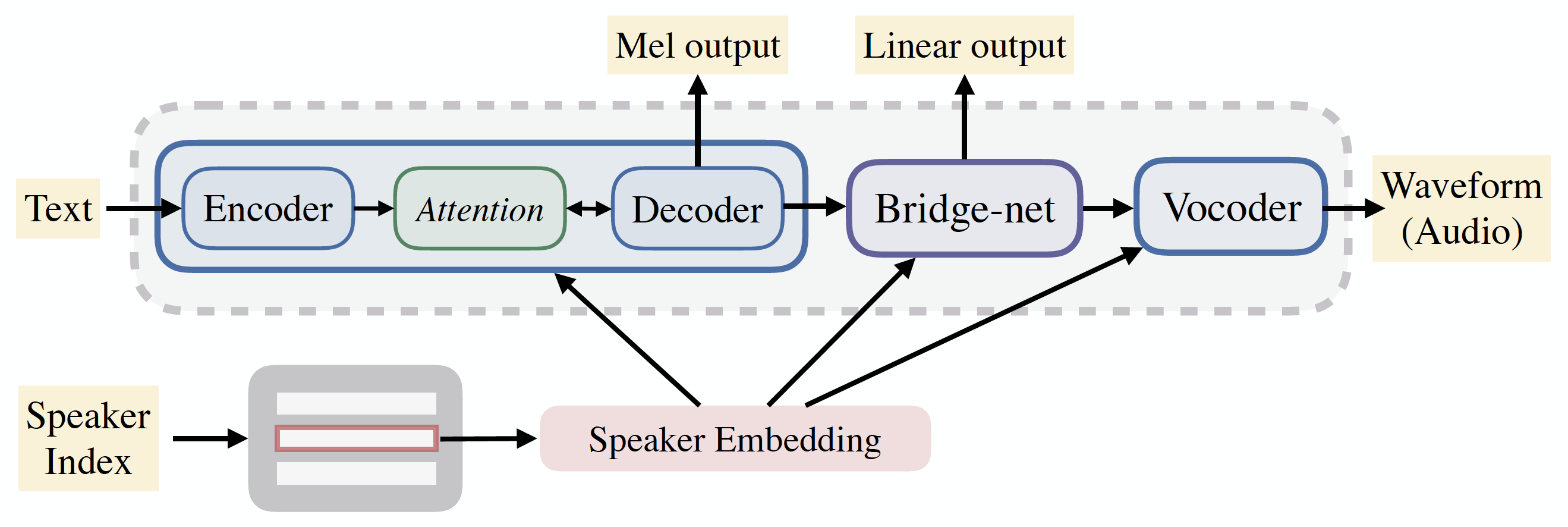
In this work, we extend ClariNet (Ping et al., 2019), a fully end-to-end speech synthesis model (i.e., text-to-wave), to generate high-fidelity speech from multiple speakers. To model the unique characteristic of different voices, low dimensional trainable speaker embeddings are shared across each component of ClariNet and trained together with the rest of the model. We demonstrate that the multi-speaker ClariNet outperforms state-of-the-art systems in terms of naturalness, because the whole model is jointly optimized in an end-to-end manner.
翻译:在这项工作中,我们扩展了ClariNet(Ping等人,2019年),这是一个完全端对端的语音合成模型(即文本到波),以产生多个发言者的高度忠诚的演讲。为模拟不同声音的独特性,在ClariNet的每个组成部分中共享低维可训练的演讲器嵌入,并与该模型的其余部分一起培训。我们证明,在自然性方面,多发式的ClariNet在多发式上优于最先进的系统,因为整个模型以端对端的方式共同优化。
相关内容
专知会员服务
26+阅读 · 2020年2月16日
专知会员服务
54+阅读 · 2020年1月30日
专知会员服务
39+阅读 · 2020年1月30日
Arxiv
5+阅读 · 2019年7月4日
Arxiv
5+阅读 · 2019年2月14日



相关VIP内容
专知会员服务
26+阅读 · 2020年2月16日
专知会员服务
54+阅读 · 2020年1月30日
专知会员服务
39+阅读 · 2020年1月30日
相关资讯
相关论文
Arxiv
5+阅读 · 2019年7月4日
Arxiv
5+阅读 · 2019年2月14日