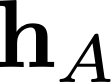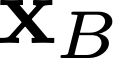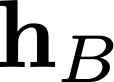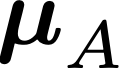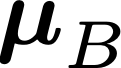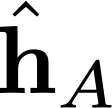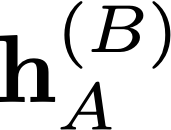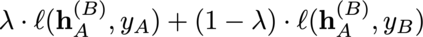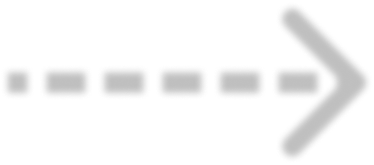Modern neural network training relies heavily on data augmentation for improved generalization. After the initial success of label-preserving augmentations, there has been a recent surge of interest in label-perturbing approaches, which combine features and labels across training samples to smooth the learned decision surface. In this paper, we propose a new augmentation method that leverages the first and second moments extracted and re-injected by feature normalization. We replace the moments of the learned features of one training image by those of another, and also interpolate the target labels. As our approach is fast, operates entirely in feature space, and mixes different signals than prior methods, one can effectively combine it with existing augmentation methods. We demonstrate its efficacy across benchmark data sets in computer vision, speech, and natural language processing, where it consistently improves the generalization performance of highly competitive baseline networks.
翻译:现代神经网络培训主要依靠数据增强来改进一般化。 在标签保护增强的初期成功之后,最近出现了对标签干扰方法的兴趣激增,这种方法将培训样本的特征和标签结合起来,以平滑学习的决策面。在本文中,我们提出一种新的增强方法,利用特征正常化提取和重新输入的第一和第二时刻。我们用另一个图像取代一个培训图像的学习特征,并同时对目标标签进行内插。由于我们的方法是快速的,完全在功能空间运行,并且将不同信号与先前的方法混合在一起,因此可以有效地将其与现有的增强方法结合起来。我们展示了计算机视觉、语音和自然语言处理中的基准数据集的功效,并不断提高高度竞争的基线网络的通用性能。