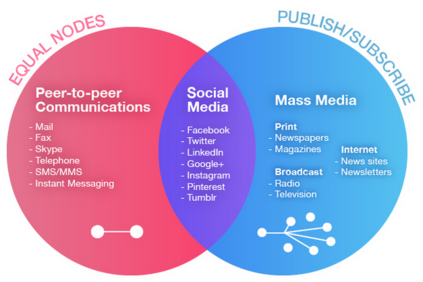
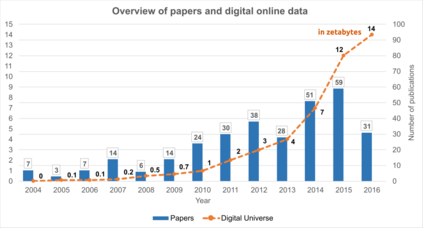
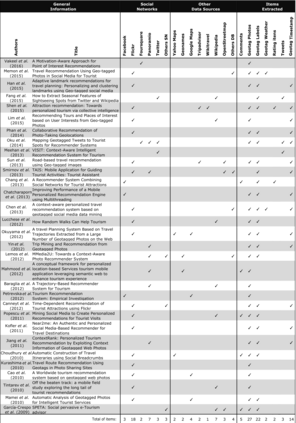
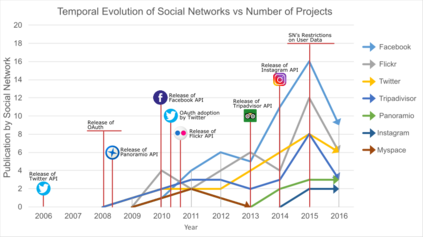
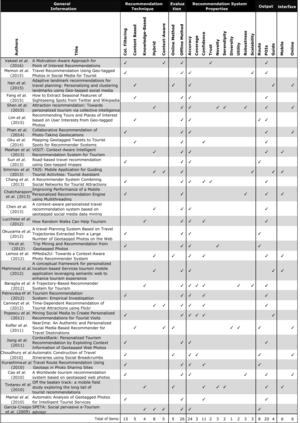
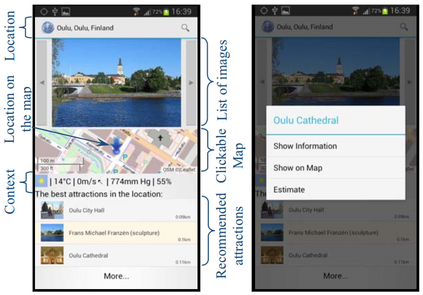
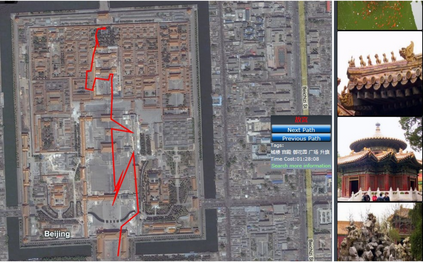
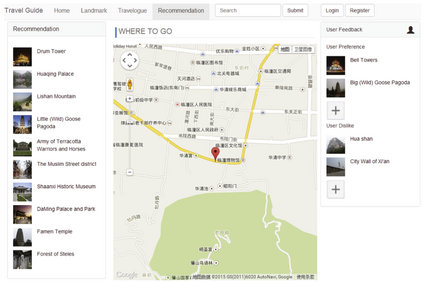
Nowadays, recommender systems are present in many daily activities such as online shopping, browsing social networks, etc. Given the rising demand for reinvigoration of the tourist industry through information technology, recommenders have been included into tourism websites such as Expedia, Booking or Tripadvisor, among others. Furthermore, the amount of scientific papers related to recommender systems for tourism is on solid and continuous growth since 2004. Much of this growth is due to social networks that, besides to offer researchers the possibility of using a great mass of available and constantly updated data, they also enable the recommendation systems to become more personalised, effective and natural. This paper reviews and analyses many research publications focusing on tourism recommender systems that use social networks in their projects. We detail their main characteristics, like which social networks are exploited, which data is extracted, the applied recommendation techniques, the methods of evaluation, etc. Through a comprehensive literature review, we aim to collaborate with the future recommender systems, by giving some clear classifications and descriptions of the current tourism recommender systems.
翻译:目前,许多日常活动,如网上购物、浏览社交网络等,都有推荐系统。 鉴于对通过信息技术振兴旅游业的需求不断增长,推荐者已被列入旅游网站,如Expedia、预订或Tripadvisor等。此外,自2004年以来,与旅游推荐者系统有关的科学论文数量是稳健和持续增长的。这种增长在很大程度上是由于社交网络的缘故,这些网络除了使研究人员有可能使用大量可用和不断更新的数据外,还使推荐系统能够更加个性化、有效和自然。本文审查并分析了许多侧重于旅游推荐者系统的研究出版物,这些研究出版物侧重于在其项目中使用社会网络的旅游推荐者系统。我们详细介绍了这些出版物的主要特征,如利用哪些社会网络、提取数据、应用推荐技术、评价方法等等。我们通过全面的文献审查,力求与未来的推荐者系统合作,对目前的旅游推荐者系统进行一些明确的分类和描述。