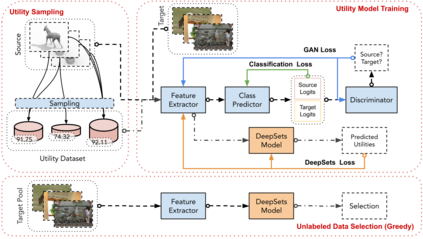
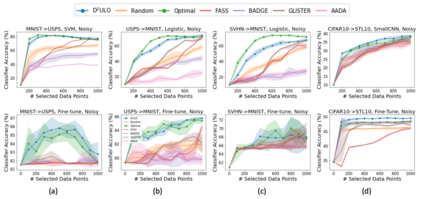
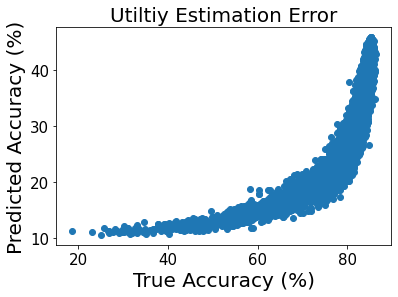
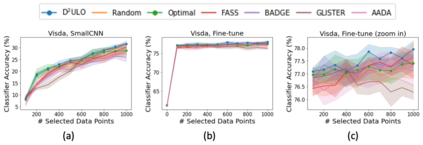
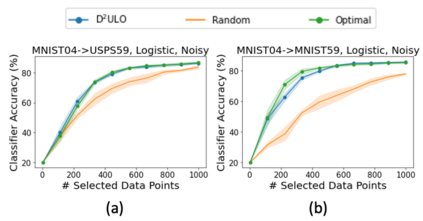
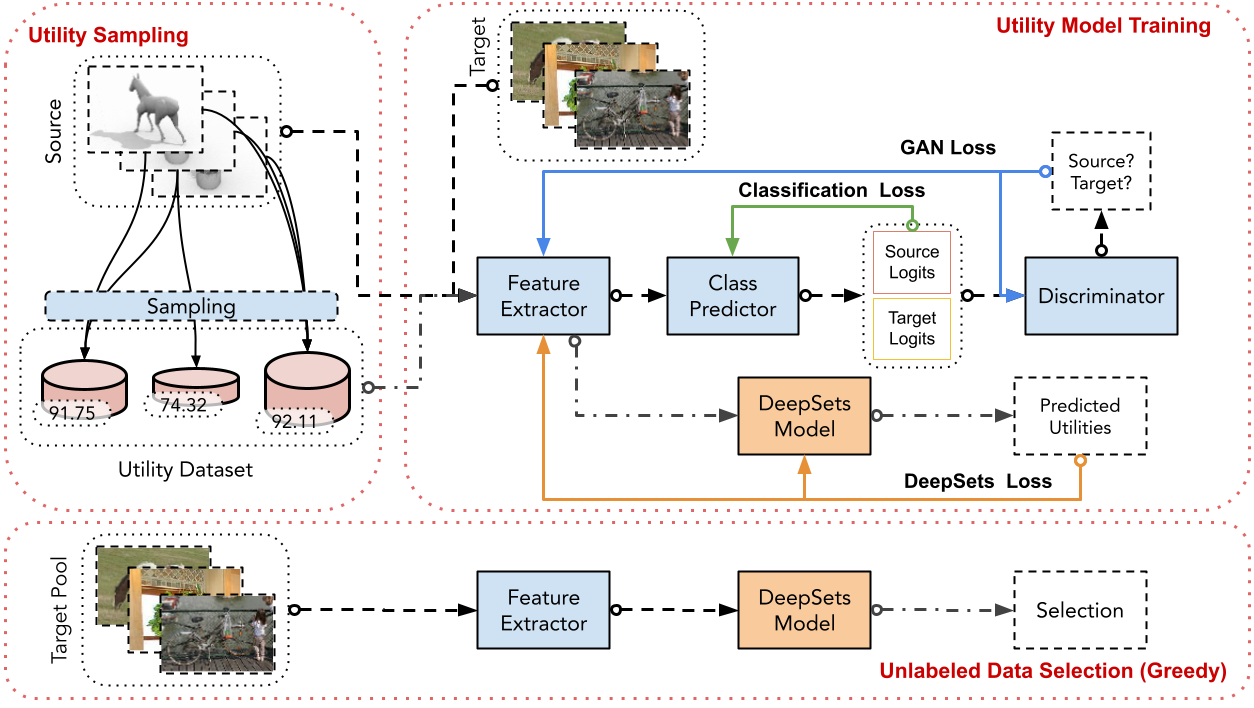
Active learning (AL) aims at reducing labeling effort by identifying the most valuable unlabeled data points from a large pool. Traditional AL frameworks have two limitations: First, they perform data selection in a multi-round manner, which is time-consuming and impractical. Second, they usually assume that there are a small amount of labeled data points available in the same domain as the data in the unlabeled pool. Recent work proposes a solution for one-round active learning based on data utility learning and optimization, which fixes the first issue but still requires the initially labeled data points in the same domain. In this paper, we propose $\mathrm{D^2ULO}$ as a solution that solves both issues. Specifically, $\mathrm{D^2ULO}$ leverages the idea of domain adaptation (DA) to train a data utility model which can effectively predict the utility for any given unlabeled data in the target domain once labeled. The trained data utility model can then be used to select high-utility data and at the same time, provide an estimate for the utility of the selected data. Our algorithm does not rely on any feedback from annotators in the target domain and hence, can be used to perform zero-round active learning or warm-start existing multi-round active learning strategies. Our experiments show that $\mathrm{D^2ULO}$ outperforms the existing state-of-the-art AL strategies equipped with domain adaptation over various domain shift settings (e.g., real-to-real data and synthetic-to-real data). Particularly, $\mathrm{D^2ULO}$ is applicable to the scenario where source and target labels have mismatches, which is not supported by the existing works.
翻译:积极学习 (AL) 的目的是减少标签工作, 方法是从大库中识别最有价值的未标签数据点 。 传统的 AL 框架有两个限制 : 首先, 它们以多轮方式进行数据选择, 这既耗时又不切实际。 其次, 它们通常假设在与未标签的集合中的数据在同一领域有少量的标签数据点 。 最近的工作提出了基于数据效用学习和优化的一回合积极学习解决方案, 它修正了第一个问题, 但仍然需要在同一域中初始的标签数据设置 。 在本文中, 我们提议用$\ mathrm{ D2=2ULO} 来进行数据选择。 具体来说, $\ mathrm{ D=2} 以多轮方式选择数据选择数据选择。 我们的主动算法无法从当前目标中获取任何最新数据, 正在从当前目标中学习到当前目标, 正在从当前目标中学习 。 正在运行的 正在运行的 正在运行的 正在运行的 URLO 。