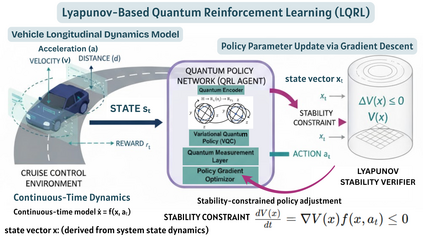
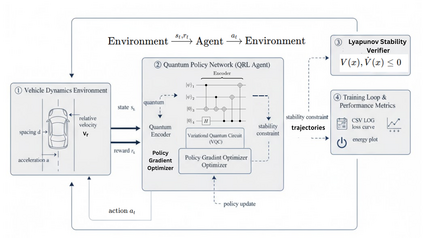
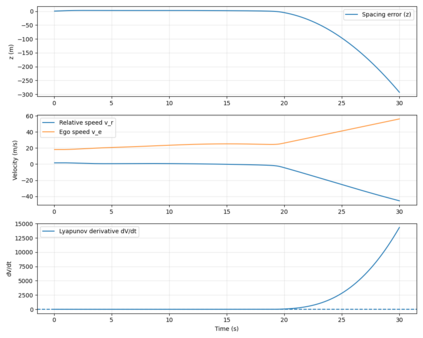
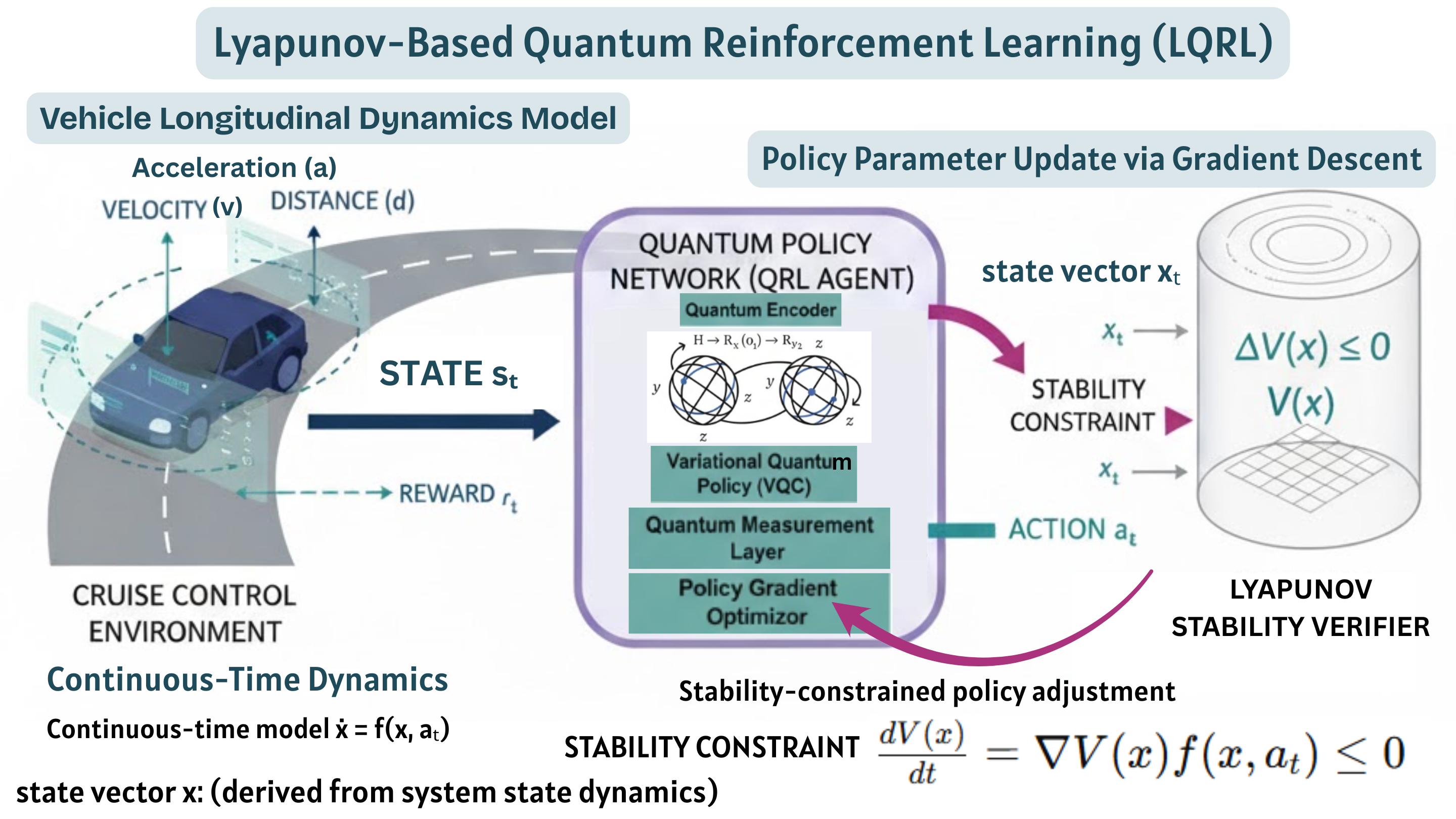
This paper presents a novel Lyapunov-Based Quantum Reinforcement Learning (LQRL) framework that integrates quantum policy optimization with Lyapunov stability analysis for continuous-time vehicle control. The proposed approach combines the representational power of variational quantum circuits (VQCs) with a stability-aware policy gradient mechanism to ensure asymptotic convergence and safe decision-making under dynamic environments. The vehicle longitudinal control problem was formulated as a continuous-state reinforcement learning task, where the quantum policy network generates control actions subject to Lyapunov stability constraints. Simulation experiments were conducted in a closed-loop adaptive cruise control scenario using a quantum-inspired policy trained under stability feedback. The results demonstrate that the LQRL framework successfully embeds Lyapunov stability verification into quantum policy learning, enabling interpretable and stability-aware control performance. Although transient overshoot and Lyapunov divergence were observed under aggressive acceleration, the system maintained bounded state evolution, validating the feasibility of integrating safety guarantees within quantum reinforcement learning architectures. The proposed framework provides a foundational step toward provably safe quantum control in autonomous systems and hybrid quantum-classical optimization domains.
翻译:暂无翻译