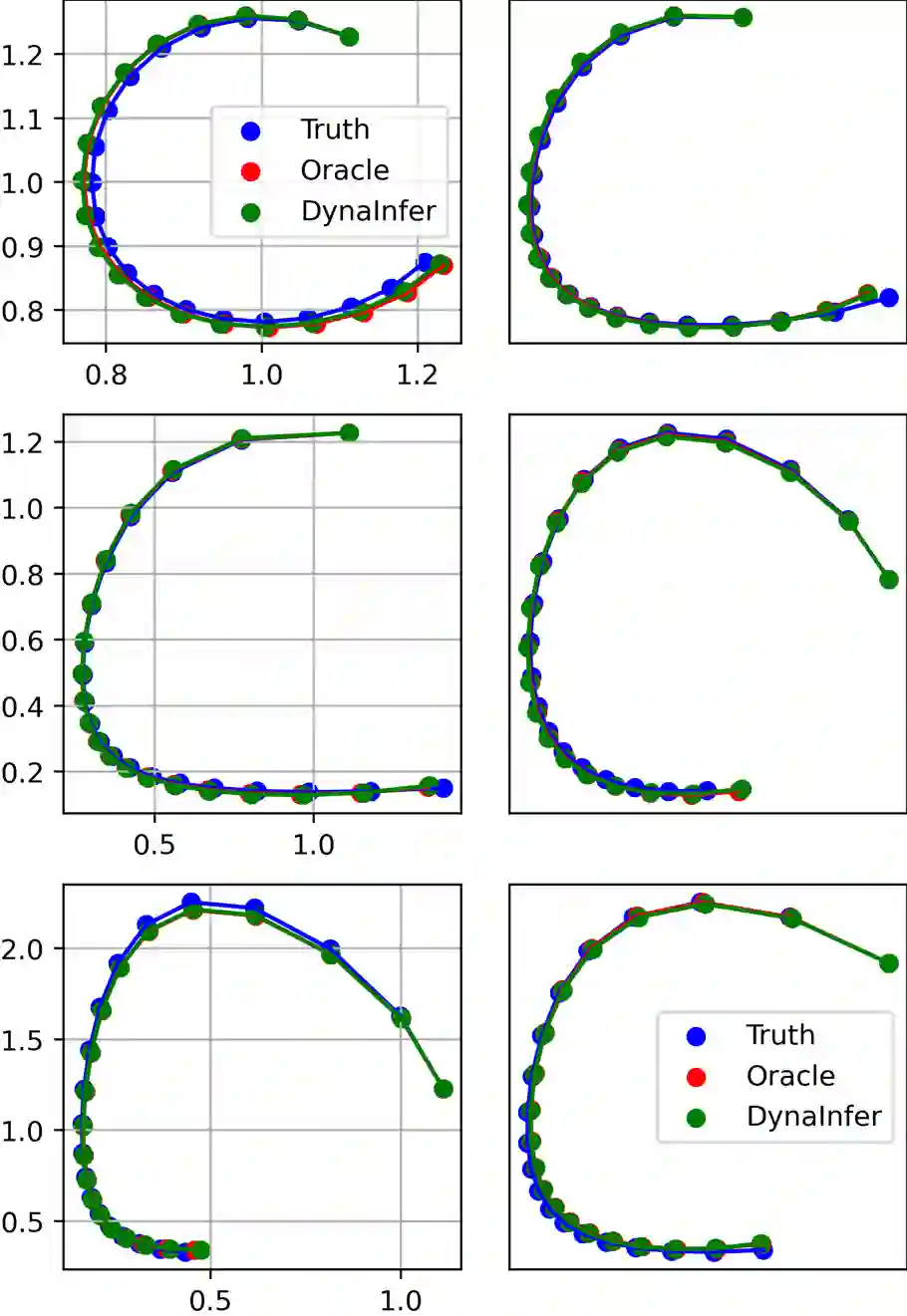
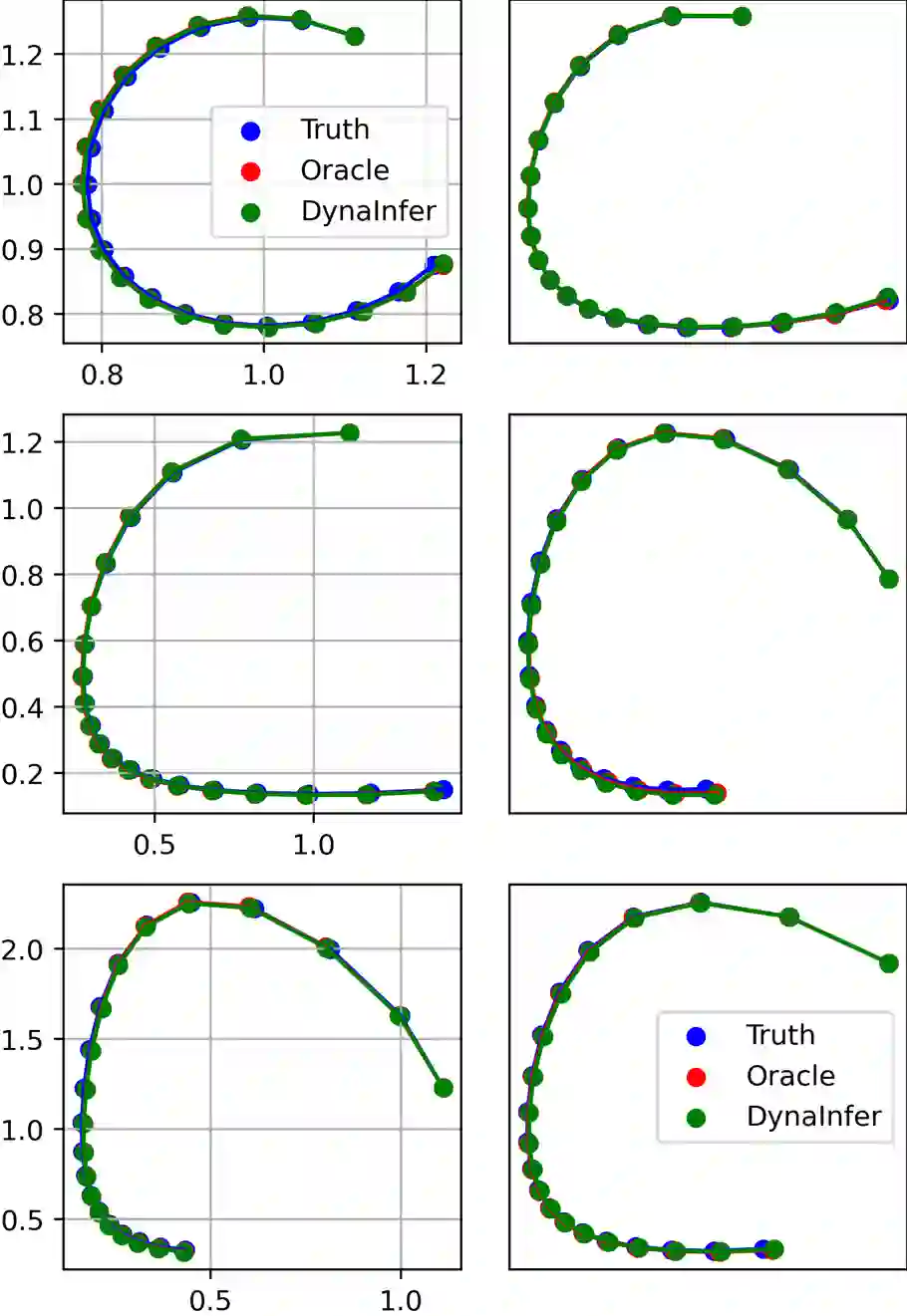
Data-driven methods offer efficient and robust solutions for analyzing complex dynamical systems but rely on the assumption of I.I.D. data, driving the development of generalization techniques for handling environmental differences. These techniques, however, are limited by their dependence on environment labels, which are often unavailable during training due to data acquisition challenges, privacy concerns, and environmental variability, particularly in large public datasets and privacy-sensitive domains. In response, we propose DynaInfer, a novel method that infers environment specifications by analyzing prediction errors from fixed neural networks within each training round, enabling environment assignments directly from data. We prove our algorithm effectively solves the alternating optimization problem in unlabeled scenarios and validate it through extensive experiments across diverse dynamical systems. Results show that DynaInfer outperforms existing environment assignment techniques, converges rapidly to true labels, and even achieves superior performance when environment labels are available.
翻译:数据驱动方法为分析复杂动态系统提供了高效且稳健的解决方案,但其依赖于独立同分布数据的假设,这推动了处理环境差异的泛化技术的发展。然而,这些技术受限于其对环境标签的依赖,由于数据采集的挑战、隐私问题以及环境变异性,这些标签在训练过程中往往难以获取,特别是在大型公共数据集和隐私敏感领域。为此,我们提出了DynaInfer,这是一种新颖的方法,通过分析每个训练轮次中固定神经网络的预测误差来推断环境规格,从而直接从数据中实现环境分配。我们证明了我们的算法能有效解决无标签场景下的交替优化问题,并通过在不同动态系统中的广泛实验进行了验证。结果表明,DynaInfer优于现有的环境分配技术,能快速收敛到真实标签,甚至在环境标签可用时也能实现更优的性能。