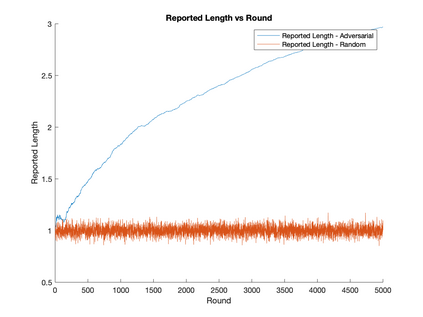
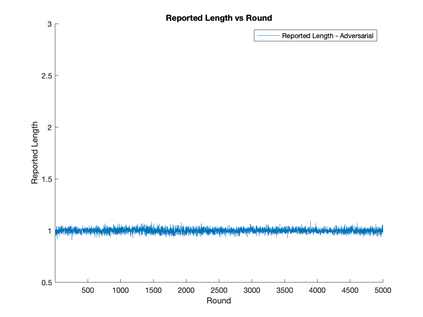
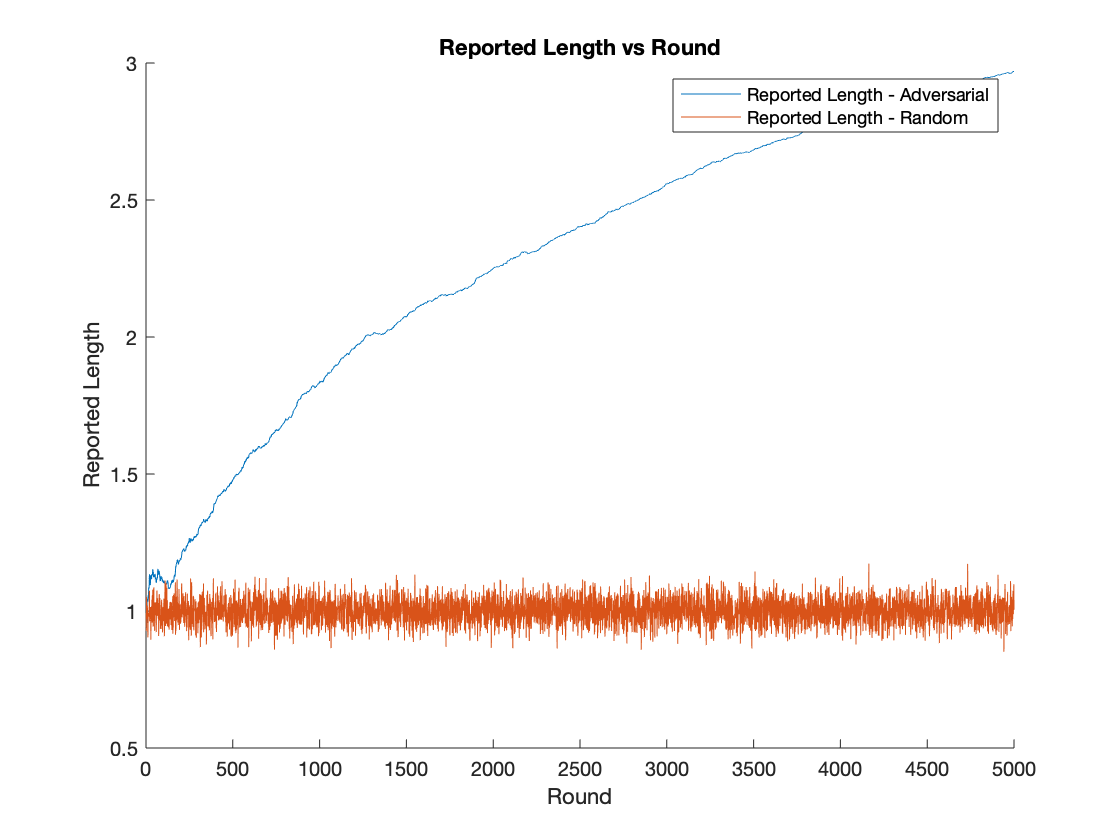
We provide a static data structure for distance estimation which supports {\it adaptive} queries. Concretely, given a dataset $X = \{x_i\}_{i = 1}^n$ of $n$ points in $\mathbb{R}^d$ and $0 < p \leq 2$, we construct a randomized data structure with low memory consumption and query time which, when later given any query point $q \in \mathbb{R}^d$, outputs a $(1+\epsilon)$-approximation of $\lVert q - x_i \rVert_p$ with high probability for all $i\in[n]$. The main novelty is our data structure's correctness guarantee holds even when the sequence of queries can be chosen adaptively: an adversary is allowed to choose the $j$th query point $q_j$ in a way that depends on the answers reported by the data structure for $q_1,\ldots,q_{j-1}$. Previous randomized Monte Carlo methods do not provide error guarantees in the setting of adaptively chosen queries. Our memory consumption is $\tilde O((n+d)d/\epsilon^2)$, slightly more than the $O(nd)$ required to store $X$ in memory explicitly, but with the benefit that our time to answer queries is only $\tilde O(\epsilon^{-2}(n + d))$, much faster than the naive $\Theta(nd)$ time obtained from a linear scan in the case of $n$ and $d$ very large. Here $\tilde O$ hides $\log(nd/\epsilon)$ factors. We discuss applications to nearest neighbor search and nonparametric estimation. Our method is simple and likely to be applicable to other domains: we describe a generic approach for transforming randomized Monte Carlo data structures which do not support adaptive queries to ones that do, and show that for the problem at hand, it can be applied to standard nonadaptive solutions to $\ell_p$ norm estimation with negligible overhead in query time and a factor $d$ overhead in memory.
翻译:我们为远程估算提供一个静态数据结构, 用于支持 [适应] 查询。 具体地说, 如果一个数据集 $X = $xx_ x_ i ⁇ i = 1 $n 美元, 美元\ mathb{ R ⁇ d$ 和 $ < p\leq 2 美元, 我们构建了一个随机化的数据结构, 内存消耗和查询时间的顺序较低, 当以后给出任何查询点 $@ in\ mathbb{R} 美元时, 产出 $( 1\\ eepsill) $- 和 美元 美元 美元 美元 的匹配 。 以内存 美元 美元 的 Order_ x_ 美元 = p$, 上调色色的 Orvl= d=xxx 。 内化的 Odressal= rodeal= dqr=xxxxxxxxxxx 内化数据, 内化的内存数据, 内存数据 =xxxxxxxxxxxxxxxxx