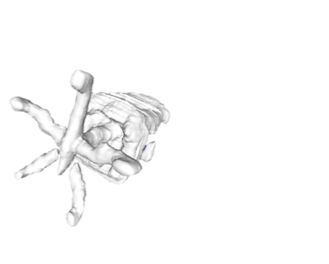
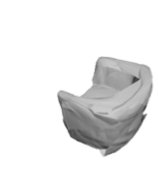
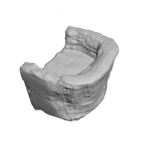
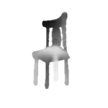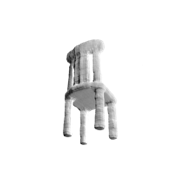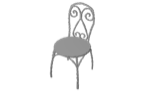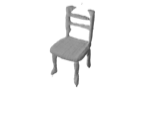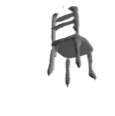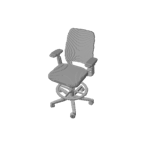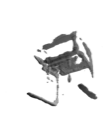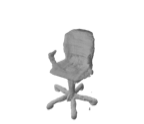The problem of single-view 3D shape completion or reconstruction is challenging, because among the many possible shapes that explain an observation, most are implausible and do not correspond to natural objects. Recent research in the field has tackled this problem by exploiting the expressiveness of deep convolutional networks. In fact, there is another level of ambiguity that is often overlooked: among plausible shapes, there are still multiple shapes that fit the 2D image equally well; i.e., the ground truth shape is non-deterministic given a single-view input. Existing fully supervised approaches fail to address this issue, and often produce blurry mean shapes with smooth surfaces but no fine details. In this paper, we propose ShapeHD, pushing the limit of single-view shape completion and reconstruction by integrating deep generative models with adversarially learned shape priors. The learned priors serve as a regularizer, penalizing the model only if its output is unrealistic, not if it deviates from the ground truth. Our design thus overcomes both levels of ambiguity aforementioned. Experiments demonstrate that ShapeHD outperforms state of the art by a large margin in both shape completion and shape reconstruction on multiple real datasets.
翻译:单一视图 3D 形状完成或重建的问题具有挑战性,因为在解释观察的许多可能的形状中,大多数是不可想象的,并且与自然物体不相符。最近实地研究利用深层革命网络的清晰度来解决这个问题。事实上,还有另一种程度的模糊性,常常被忽视:在可信的形状中,仍然存在着与 2D 图像同样相适应的多种形状;即,从单一视图输入中看,地面真相形状不是决定性的。现有的完全监督方法未能解决这一问题,往往产生光滑表面的模糊平均值,但没有细微的细节。在本文件中,我们建议 形状HD,通过将深度的变形模型与对立学习形状之前的形状结合起来,推动单一视图形状完成和重建的极限。 学过的前几期是一个正规化的形状,只有当模型的输出不切实际事实,而不是偏离地面事实时,才惩罚模型。我们的设计因此克服了上述两种模棱两面的模糊性。实验显示,在实际形状上以大比例进行重建的形状显示ShapeHD 外形。