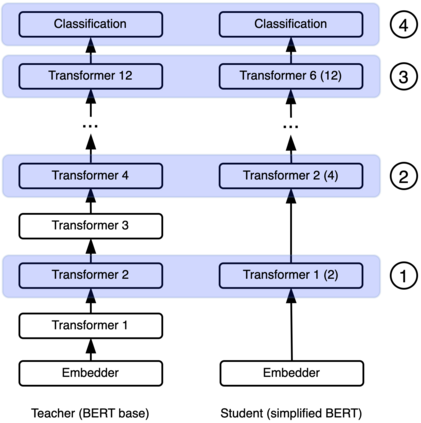
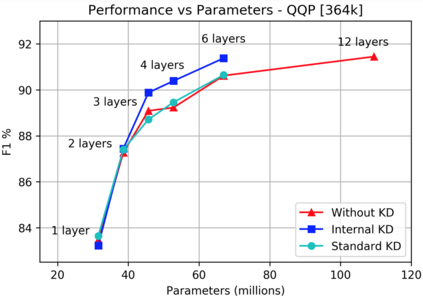
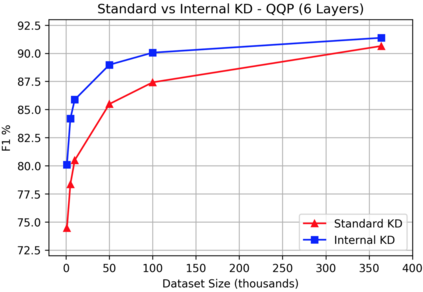
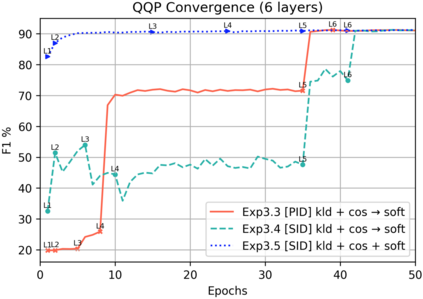
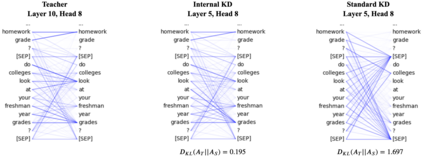
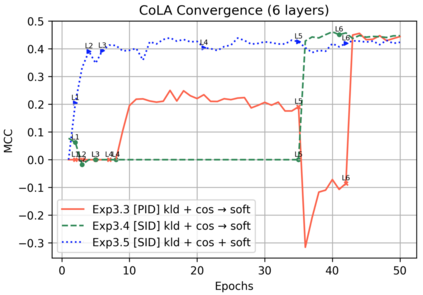
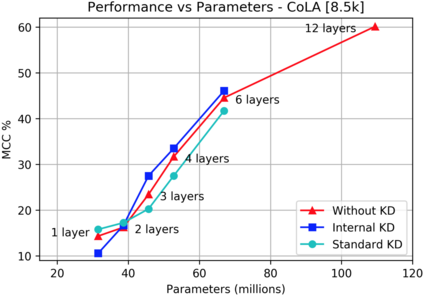
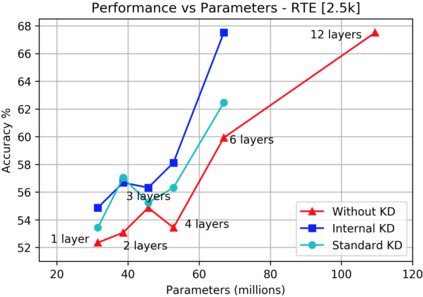
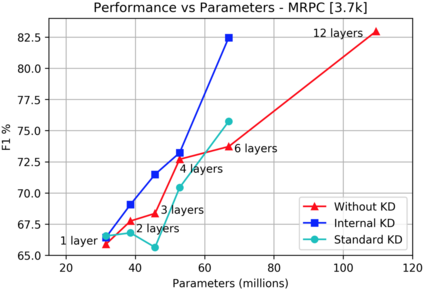
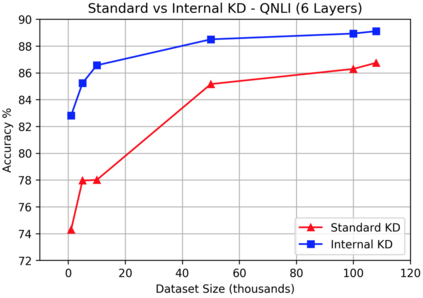
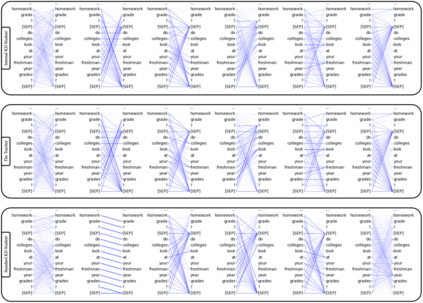
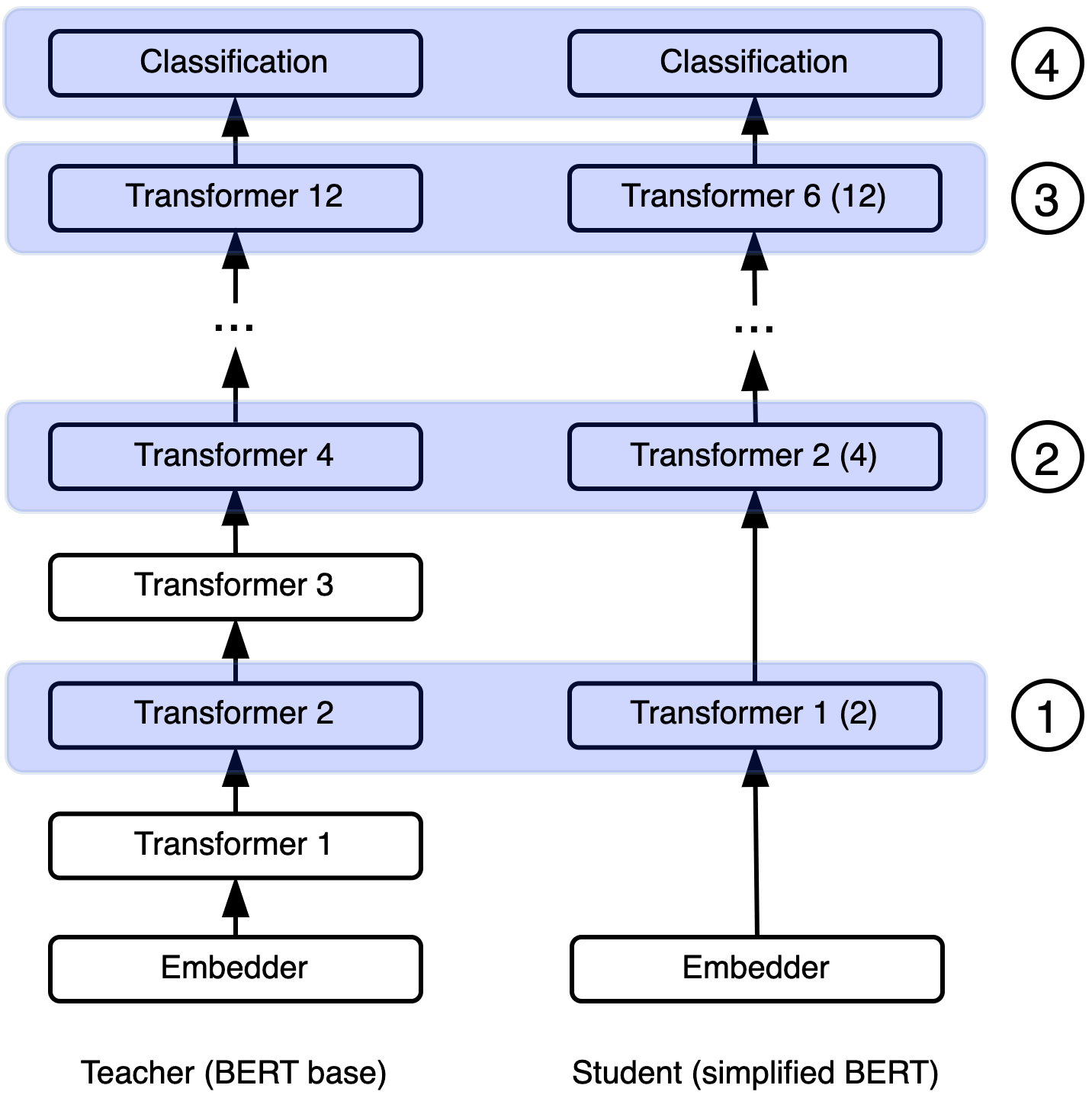
Knowledge distillation is typically conducted by training a small model (the student) to mimic a large and cumbersome model (the teacher). The idea is to compress the knowledge from the teacher by using its output probabilities as soft-labels to optimize the student. However, when the teacher is considerably large, there is no guarantee that the internal knowledge of the teacher will be transferred into the student; even if the student closely matches the soft-labels, its internal representations may be considerably different. This internal mismatch can undermine the generalization capabilities originally intended to be transferred from the teacher to the student. In this paper, we propose to distill the internal representations of a large model such as BERT into a simplified version of it. We formulate two ways to distill such representations and various algorithms to conduct the distillation. We experiment with datasets from the GLUE benchmark and consistently show that adding knowledge distillation from internal representations is a more powerful method than only using soft-label distillation.
翻译:通常通过培训一个小型模型(学生)来模仿一个庞大和繁琐的模型(教师)来进行知识蒸馏,目的是通过将教师的输出概率作为软标签来压缩教师的知识,优化学生的优化。然而,当教师人数相当大时,无法保证教师的内部知识将转移到学生身上;即使学生与软标签非常接近,其内部表现可能大不相同。这种内部不匹配会损害原来打算从教师转移到学生的概括能力。在本文中,我们提议将一个大型模型(如BERT)的内部表达方式提炼成一个简化版本。我们制定了两种方法来提炼这种表达方式和各种算法来进行蒸馏。我们用GLUE基准的数据集进行实验,并不断表明从内部表述中添加知识提炼是一种比使用软标签蒸馏法更强大的方法。